Hyeongmin Cho , Sooyoung Yoo , Borham Kim , Sowon Jang , Leonard Sunwoo , Sanghwan Kim , Donghyoung Lee , Seok Kim , Sejin Nam , Jin-Haeng Chung
{"title":"从病理报告中提取肺癌分期描述符:生成语言模型方法","authors":"Hyeongmin Cho , Sooyoung Yoo , Borham Kim , Sowon Jang , Leonard Sunwoo , Sanghwan Kim , Donghyoung Lee , Seok Kim , Sejin Nam , Jin-Haeng Chung","doi":"10.1016/j.jbi.2024.104720","DOIUrl":null,"url":null,"abstract":"<div><h3>Background</h3><p>In oncology, electronic health records contain textual key information for the diagnosis, staging, and treatment planning of patients with cancer. However, text data processing requires a lot of time and effort, which limits the utilization of these data. Recent advances in natural language processing (NLP) technology, including large language models, can be applied to cancer research. Particularly, extracting the information required for the pathological stage from surgical pathology reports can be utilized to update cancer staging according to the latest cancer staging guidelines.</p></div><div><h3>Objectives</h3><p>This study has two main objectives. The first objective is to evaluate the performance of extracting information from text-based surgical pathology reports and determining pathological stages based on the extracted information using fine-tuned generative language models (GLMs) for patients with lung cancer. The second objective is to determine the feasibility of utilizing relatively small GLMs for information extraction in a resource-constrained computing environment.</p></div><div><h3>Methods</h3><p>Lung cancer surgical pathology reports were collected from the Common Data Model database of Seoul National University Bundang Hospital (SNUBH), a tertiary hospital in Korea. We selected 42 descriptors necessary for tumor-node (TN) classification based on these reports and created a gold standard with validation by two clinical experts. The pathology reports and gold standard were used to generate prompt-response pairs for training and evaluating GLMs which then were used to extract information required for staging from pathology reports.</p></div><div><h3>Results</h3><p>We evaluated the information extraction performance of six trained models as well as their performance in TN classification using the extracted information. The Deductive Mistral-7B model, which was pre-trained with the deductive dataset, showed the best performance overall, with an exact match ratio of 92.24% in the information extraction problem and an accuracy of 0.9876 (predicting T and N classification concurrently) in classification.</p></div><div><h3>Conclusion</h3><p>This study demonstrated that training GLMs with deductive datasets can improve information extraction performance, and GLMs with a relatively small number of parameters at approximately seven billion can achieve high performance in this problem. The proposed GLM-based information extraction method is expected to be useful in clinical decision-making support, lung cancer staging and research.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"157 ","pages":"Article 104720"},"PeriodicalIF":4.0000,"publicationDate":"2024-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S1532046424001382/pdfft?md5=a07a39b7bc41fc8621f04b2757525870&pid=1-s2.0-S1532046424001382-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Extracting lung cancer staging descriptors from pathology reports: A generative language model approach\",\"authors\":\"Hyeongmin Cho , Sooyoung Yoo , Borham Kim , Sowon Jang , Leonard Sunwoo , Sanghwan Kim , Donghyoung Lee , Seok Kim , Sejin Nam , Jin-Haeng Chung\",\"doi\":\"10.1016/j.jbi.2024.104720\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Background</h3><p>In oncology, electronic health records contain textual key information for the diagnosis, staging, and treatment planning of patients with cancer. However, text data processing requires a lot of time and effort, which limits the utilization of these data. Recent advances in natural language processing (NLP) technology, including large language models, can be applied to cancer research. Particularly, extracting the information required for the pathological stage from surgical pathology reports can be utilized to update cancer staging according to the latest cancer staging guidelines.</p></div><div><h3>Objectives</h3><p>This study has two main objectives. The first objective is to evaluate the performance of extracting information from text-based surgical pathology reports and determining pathological stages based on the extracted information using fine-tuned generative language models (GLMs) for patients with lung cancer. The second objective is to determine the feasibility of utilizing relatively small GLMs for information extraction in a resource-constrained computing environment.</p></div><div><h3>Methods</h3><p>Lung cancer surgical pathology reports were collected from the Common Data Model database of Seoul National University Bundang Hospital (SNUBH), a tertiary hospital in Korea. We selected 42 descriptors necessary for tumor-node (TN) classification based on these reports and created a gold standard with validation by two clinical experts. The pathology reports and gold standard were used to generate prompt-response pairs for training and evaluating GLMs which then were used to extract information required for staging from pathology reports.</p></div><div><h3>Results</h3><p>We evaluated the information extraction performance of six trained models as well as their performance in TN classification using the extracted information. The Deductive Mistral-7B model, which was pre-trained with the deductive dataset, showed the best performance overall, with an exact match ratio of 92.24% in the information extraction problem and an accuracy of 0.9876 (predicting T and N classification concurrently) in classification.</p></div><div><h3>Conclusion</h3><p>This study demonstrated that training GLMs with deductive datasets can improve information extraction performance, and GLMs with a relatively small number of parameters at approximately seven billion can achieve high performance in this problem. The proposed GLM-based information extraction method is expected to be useful in clinical decision-making support, lung cancer staging and research.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"157 \",\"pages\":\"Article 104720\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001382/pdfft?md5=a07a39b7bc41fc8621f04b2757525870&pid=1-s2.0-S1532046424001382-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001382\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001382","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
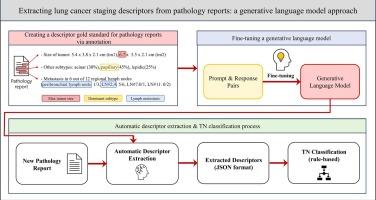
Extracting lung cancer staging descriptors from pathology reports: A generative language model approach
Background
In oncology, electronic health records contain textual key information for the diagnosis, staging, and treatment planning of patients with cancer. However, text data processing requires a lot of time and effort, which limits the utilization of these data. Recent advances in natural language processing (NLP) technology, including large language models, can be applied to cancer research. Particularly, extracting the information required for the pathological stage from surgical pathology reports can be utilized to update cancer staging according to the latest cancer staging guidelines.
Objectives
This study has two main objectives. The first objective is to evaluate the performance of extracting information from text-based surgical pathology reports and determining pathological stages based on the extracted information using fine-tuned generative language models (GLMs) for patients with lung cancer. The second objective is to determine the feasibility of utilizing relatively small GLMs for information extraction in a resource-constrained computing environment.
Methods
Lung cancer surgical pathology reports were collected from the Common Data Model database of Seoul National University Bundang Hospital (SNUBH), a tertiary hospital in Korea. We selected 42 descriptors necessary for tumor-node (TN) classification based on these reports and created a gold standard with validation by two clinical experts. The pathology reports and gold standard were used to generate prompt-response pairs for training and evaluating GLMs which then were used to extract information required for staging from pathology reports.
Results
We evaluated the information extraction performance of six trained models as well as their performance in TN classification using the extracted information. The Deductive Mistral-7B model, which was pre-trained with the deductive dataset, showed the best performance overall, with an exact match ratio of 92.24% in the information extraction problem and an accuracy of 0.9876 (predicting T and N classification concurrently) in classification.
Conclusion
This study demonstrated that training GLMs with deductive datasets can improve information extraction performance, and GLMs with a relatively small number of parameters at approximately seven billion can achieve high performance in this problem. The proposed GLM-based information extraction method is expected to be useful in clinical decision-making support, lung cancer staging and research.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


