Shuntaro Yada, Yuta Nakamura, Shoko Wakamiya, Eiji Aramaki
{"title":"英语和日语有限注释病例/放射学报告的跨语言自然语言处理:Real-MedNLP 研讨会的启示。","authors":"Shuntaro Yada, Yuta Nakamura, Shoko Wakamiya, Eiji Aramaki","doi":"10.1055/a-2405-2489","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong> Textual datasets (corpora) are crucial for the application of natural language processing (NLP) models. However, corpus creation in the medical field is challenging, primarily because of privacy issues with raw clinical data such as health records. Thus, the existing clinical corpora are generally small and scarce. Medical NLP (MedNLP) methodologies perform well with limited data availability.</p><p><strong>Objectives: </strong> We present the outcomes of the Real-MedNLP workshop, which was conducted using limited and parallel medical corpora. Real-MedNLP exhibits three distinct characteristics: (1) limited annotated documents: the training data comprise only a small set (∼100) of case reports (CRs) and radiology reports (RRs) that have been annotated. (2) Bilingually parallel: the constructed corpora are parallel in Japanese and English. (3) Practical tasks: the workshop addresses fundamental tasks, such as named entity recognition (NER) and applied practical tasks.</p><p><strong>Methods: </strong> We propose three tasks: NER of ∼100 available documents (Task 1), NER based only on annotation guidelines for humans (Task 2), and clinical applications (Task 3) consisting of adverse drug effect (ADE) detection for CRs and identical case identification (CI) for RRs.</p><p><strong>Results: </strong> Nine teams participated in this study. The best systems achieved 0.65 and 0.89 F1-scores for CRs and RRs in Task 1, whereas the top scores in Task 2 decreased by 50 to 70%. In Task 3, ADE reports were detected by up to 0.64 F1-score, and CI scored up to 0.96 binary accuracy.</p><p><strong>Conclusion: </strong> Most systems adopt medical-domain-specific pretrained language models using data augmentation methods. Despite the challenge of limited corpus size in Tasks 1 and 2, recent approaches are promising because the partial match scores reached ∼0.8-0.9 F1-scores. Task 3 applications revealed that the different availabilities of external language resources affected the performance per language.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":" ","pages":"145-163"},"PeriodicalIF":1.8000,"publicationDate":"2024-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12196824/pdf/","citationCount":"0","resultStr":"{\"title\":\"Cross-lingual Natural Language Processing on Limited Annotated Case/Radiology Reports in English and Japanese: Insights from the Real-MedNLP Workshop.\",\"authors\":\"Shuntaro Yada, Yuta Nakamura, Shoko Wakamiya, Eiji Aramaki\",\"doi\":\"10.1055/a-2405-2489\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong> Textual datasets (corpora) are crucial for the application of natural language processing (NLP) models. However, corpus creation in the medical field is challenging, primarily because of privacy issues with raw clinical data such as health records. Thus, the existing clinical corpora are generally small and scarce. Medical NLP (MedNLP) methodologies perform well with limited data availability.</p><p><strong>Objectives: </strong> We present the outcomes of the Real-MedNLP workshop, which was conducted using limited and parallel medical corpora. Real-MedNLP exhibits three distinct characteristics: (1) limited annotated documents: the training data comprise only a small set (∼100) of case reports (CRs) and radiology reports (RRs) that have been annotated. (2) Bilingually parallel: the constructed corpora are parallel in Japanese and English. (3) Practical tasks: the workshop addresses fundamental tasks, such as named entity recognition (NER) and applied practical tasks.</p><p><strong>Methods: </strong> We propose three tasks: NER of ∼100 available documents (Task 1), NER based only on annotation guidelines for humans (Task 2), and clinical applications (Task 3) consisting of adverse drug effect (ADE) detection for CRs and identical case identification (CI) for RRs.</p><p><strong>Results: </strong> Nine teams participated in this study. The best systems achieved 0.65 and 0.89 F1-scores for CRs and RRs in Task 1, whereas the top scores in Task 2 decreased by 50 to 70%. In Task 3, ADE reports were detected by up to 0.64 F1-score, and CI scored up to 0.96 binary accuracy.</p><p><strong>Conclusion: </strong> Most systems adopt medical-domain-specific pretrained language models using data augmentation methods. Despite the challenge of limited corpus size in Tasks 1 and 2, recent approaches are promising because the partial match scores reached ∼0.8-0.9 F1-scores. Task 3 applications revealed that the different availabilities of external language resources affected the performance per language.</p>\",\"PeriodicalId\":49822,\"journal\":{\"name\":\"Methods of Information in Medicine\",\"volume\":\" \",\"pages\":\"145-163\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12196824/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Methods of Information in Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1055/a-2405-2489\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2024/8/29 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/a-2405-2489","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2024/8/29 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Cross-lingual Natural Language Processing on Limited Annotated Case/Radiology Reports in English and Japanese: Insights from the Real-MedNLP Workshop.
Background: Textual datasets (corpora) are crucial for the application of natural language processing (NLP) models. However, corpus creation in the medical field is challenging, primarily because of privacy issues with raw clinical data such as health records. Thus, the existing clinical corpora are generally small and scarce. Medical NLP (MedNLP) methodologies perform well with limited data availability.
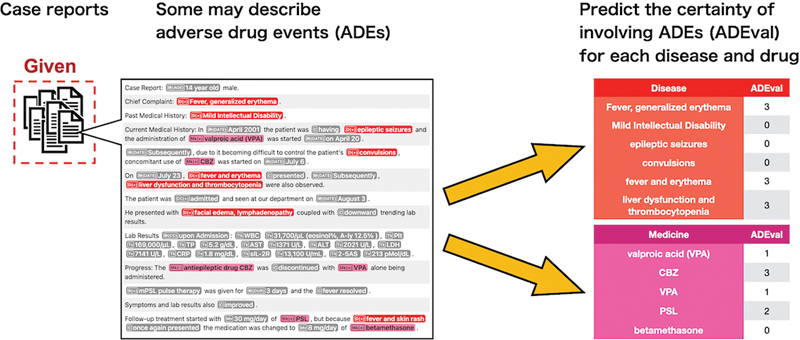
Objectives: We present the outcomes of the Real-MedNLP workshop, which was conducted using limited and parallel medical corpora. Real-MedNLP exhibits three distinct characteristics: (1) limited annotated documents: the training data comprise only a small set (∼100) of case reports (CRs) and radiology reports (RRs) that have been annotated. (2) Bilingually parallel: the constructed corpora are parallel in Japanese and English. (3) Practical tasks: the workshop addresses fundamental tasks, such as named entity recognition (NER) and applied practical tasks.
Methods: We propose three tasks: NER of ∼100 available documents (Task 1), NER based only on annotation guidelines for humans (Task 2), and clinical applications (Task 3) consisting of adverse drug effect (ADE) detection for CRs and identical case identification (CI) for RRs.
Results: Nine teams participated in this study. The best systems achieved 0.65 and 0.89 F1-scores for CRs and RRs in Task 1, whereas the top scores in Task 2 decreased by 50 to 70%. In Task 3, ADE reports were detected by up to 0.64 F1-score, and CI scored up to 0.96 binary accuracy.
Conclusion: Most systems adopt medical-domain-specific pretrained language models using data augmentation methods. Despite the challenge of limited corpus size in Tasks 1 and 2, recent approaches are promising because the partial match scores reached ∼0.8-0.9 F1-scores. Task 3 applications revealed that the different availabilities of external language resources affected the performance per language.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


