{"title":"在三维对齐空间中学习人脸结构依赖性以进行人脸对齐","authors":"Biying Li , Zhiwei Liu , Jinqiao Wang","doi":"10.1016/j.imavis.2024.105241","DOIUrl":null,"url":null,"abstract":"<div><p>Facial structure's statistical characteristics offer pivotal prior information in facial landmark prediction, forming inter-dependencies among different landmarks. Such inter-dependencies ensure that predictions adhere to the shape distribution typical of natural faces. In challenging scenarios like occlusions or extreme facial poses, this structure becomes indispensable, which can help to predict elusive landmarks based on more discernible ones. While current deep learning methods do capture these landmark dependencies, it's often an implicit process heavily reliant on vast training datasets. We contest that such implicit modeling approaches fail to manage more challenging situations. In this paper, we propose a new method that harnesses the facial structure and explicitly explores inter-dependencies among facial landmarks in an end-to-end fashion. We propose a Structural Dependency Learning Module (SDLM). It uses 3D face information to map facial features into a canonical UV space, in which the facial structure is explicitly 3D semantically aligned. Besides, to explore the global relationships between facial landmarks, we take advantage of the self-attention mechanism in the image and UV spaces. We name the proposed method Facial Structure-based Face Alignment (FSFA). FSFA reinforces the landmark structure, especially under challenging conditions. Extensive experiments demonstrate that FSFA achieves state-of-the-art performance on the WFLW, 300W, AFLW, and COFW68 datasets.</p></div>","PeriodicalId":50374,"journal":{"name":"Image and Vision Computing","volume":"150 ","pages":"Article 105241"},"PeriodicalIF":4.2000,"publicationDate":"2024-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Learning facial structural dependency in 3D aligned space for face alignment\",\"authors\":\"Biying Li , Zhiwei Liu , Jinqiao Wang\",\"doi\":\"10.1016/j.imavis.2024.105241\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Facial structure's statistical characteristics offer pivotal prior information in facial landmark prediction, forming inter-dependencies among different landmarks. Such inter-dependencies ensure that predictions adhere to the shape distribution typical of natural faces. In challenging scenarios like occlusions or extreme facial poses, this structure becomes indispensable, which can help to predict elusive landmarks based on more discernible ones. While current deep learning methods do capture these landmark dependencies, it's often an implicit process heavily reliant on vast training datasets. We contest that such implicit modeling approaches fail to manage more challenging situations. In this paper, we propose a new method that harnesses the facial structure and explicitly explores inter-dependencies among facial landmarks in an end-to-end fashion. We propose a Structural Dependency Learning Module (SDLM). It uses 3D face information to map facial features into a canonical UV space, in which the facial structure is explicitly 3D semantically aligned. Besides, to explore the global relationships between facial landmarks, we take advantage of the self-attention mechanism in the image and UV spaces. We name the proposed method Facial Structure-based Face Alignment (FSFA). FSFA reinforces the landmark structure, especially under challenging conditions. Extensive experiments demonstrate that FSFA achieves state-of-the-art performance on the WFLW, 300W, AFLW, and COFW68 datasets.</p></div>\",\"PeriodicalId\":50374,\"journal\":{\"name\":\"Image and Vision Computing\",\"volume\":\"150 \",\"pages\":\"Article 105241\"},\"PeriodicalIF\":4.2000,\"publicationDate\":\"2024-08-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Image and Vision Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0262885624003469\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Image and Vision Computing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0262885624003469","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Learning facial structural dependency in 3D aligned space for face alignment
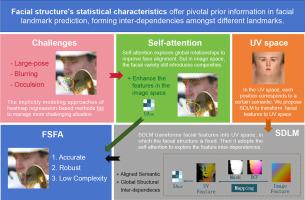
Facial structure's statistical characteristics offer pivotal prior information in facial landmark prediction, forming inter-dependencies among different landmarks. Such inter-dependencies ensure that predictions adhere to the shape distribution typical of natural faces. In challenging scenarios like occlusions or extreme facial poses, this structure becomes indispensable, which can help to predict elusive landmarks based on more discernible ones. While current deep learning methods do capture these landmark dependencies, it's often an implicit process heavily reliant on vast training datasets. We contest that such implicit modeling approaches fail to manage more challenging situations. In this paper, we propose a new method that harnesses the facial structure and explicitly explores inter-dependencies among facial landmarks in an end-to-end fashion. We propose a Structural Dependency Learning Module (SDLM). It uses 3D face information to map facial features into a canonical UV space, in which the facial structure is explicitly 3D semantically aligned. Besides, to explore the global relationships between facial landmarks, we take advantage of the self-attention mechanism in the image and UV spaces. We name the proposed method Facial Structure-based Face Alignment (FSFA). FSFA reinforces the landmark structure, especially under challenging conditions. Extensive experiments demonstrate that FSFA achieves state-of-the-art performance on the WFLW, 300W, AFLW, and COFW68 datasets.
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


