Xuechun Zhang, Xiaoxuan Hu, Tongtong Zhang, Ling Yang, Chunhong Liu, Ning Xu, Haoyi Wang, Wen Sun
{"title":"PLM_Sol:利用更新的大肠杆菌蛋白质溶解度数据集对多种蛋白质语言模型进行基准测试,从而预测蛋白质的溶解度。","authors":"Xuechun Zhang, Xiaoxuan Hu, Tongtong Zhang, Ling Yang, Chunhong Liu, Ning Xu, Haoyi Wang, Wen Sun","doi":"10.1093/bib/bbae404","DOIUrl":null,"url":null,"abstract":"<p><p>Protein solubility plays a crucial role in various biotechnological, industrial, and biomedical applications. With the reduction in sequencing and gene synthesis costs, the adoption of high-throughput experimental screening coupled with tailored bioinformatic prediction has witnessed a rapidly growing trend for the development of novel functional enzymes of interest (EOI). High protein solubility rates are essential in this process and accurate prediction of solubility is a challenging task. As deep learning technology continues to evolve, attention-based protein language models (PLMs) can extract intrinsic information from protein sequences to a greater extent. Leveraging these models along with the increasing availability of protein solubility data inferred from structural database like the Protein Data Bank holds great potential to enhance the prediction of protein solubility. In this study, we curated an Updated Escherichia coli protein Solubility DataSet (UESolDS) and employed a combination of multiple PLMs and classification layers to predict protein solubility. The resulting best-performing model, named Protein Language Model-based protein Solubility prediction model (PLM_Sol), demonstrated significant improvements over previous reported models, achieving a notable 6.4% increase in accuracy, 9.0% increase in F1_score, and 11.1% increase in Matthews correlation coefficient score on the independent test set. Moreover, additional evaluation utilizing our in-house synthesized protein resource as test data, encompassing diverse types of enzymes, also showcased the good performance of PLM_Sol. Overall, PLM_Sol exhibited consistent and promising performance across both independent test set and experimental set, thereby making it well suited for facilitating large-scale EOI studies. PLM_Sol is available as a standalone program and as an easy-to-use model at https://zenodo.org/doi/10.5281/zenodo.10675340.</p>","PeriodicalId":9209,"journal":{"name":"Briefings in bioinformatics","volume":"25 5","pages":""},"PeriodicalIF":7.7000,"publicationDate":"2024-07-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11343611/pdf/","citationCount":"0","resultStr":"{\"title\":\"PLM_Sol: predicting protein solubility by benchmarking multiple protein language models with the updated Escherichia coli protein solubility dataset.\",\"authors\":\"Xuechun Zhang, Xiaoxuan Hu, Tongtong Zhang, Ling Yang, Chunhong Liu, Ning Xu, Haoyi Wang, Wen Sun\",\"doi\":\"10.1093/bib/bbae404\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Protein solubility plays a crucial role in various biotechnological, industrial, and biomedical applications. With the reduction in sequencing and gene synthesis costs, the adoption of high-throughput experimental screening coupled with tailored bioinformatic prediction has witnessed a rapidly growing trend for the development of novel functional enzymes of interest (EOI). High protein solubility rates are essential in this process and accurate prediction of solubility is a challenging task. As deep learning technology continues to evolve, attention-based protein language models (PLMs) can extract intrinsic information from protein sequences to a greater extent. Leveraging these models along with the increasing availability of protein solubility data inferred from structural database like the Protein Data Bank holds great potential to enhance the prediction of protein solubility. In this study, we curated an Updated Escherichia coli protein Solubility DataSet (UESolDS) and employed a combination of multiple PLMs and classification layers to predict protein solubility. The resulting best-performing model, named Protein Language Model-based protein Solubility prediction model (PLM_Sol), demonstrated significant improvements over previous reported models, achieving a notable 6.4% increase in accuracy, 9.0% increase in F1_score, and 11.1% increase in Matthews correlation coefficient score on the independent test set. Moreover, additional evaluation utilizing our in-house synthesized protein resource as test data, encompassing diverse types of enzymes, also showcased the good performance of PLM_Sol. Overall, PLM_Sol exhibited consistent and promising performance across both independent test set and experimental set, thereby making it well suited for facilitating large-scale EOI studies. PLM_Sol is available as a standalone program and as an easy-to-use model at https://zenodo.org/doi/10.5281/zenodo.10675340.</p>\",\"PeriodicalId\":9209,\"journal\":{\"name\":\"Briefings in bioinformatics\",\"volume\":\"25 5\",\"pages\":\"\"},\"PeriodicalIF\":7.7000,\"publicationDate\":\"2024-07-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11343611/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Briefings in bioinformatics\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/bib/bbae404\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"BIOCHEMICAL RESEARCH METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Briefings in bioinformatics","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/bib/bbae404","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"BIOCHEMICAL RESEARCH METHODS","Score":null,"Total":0}
PLM_Sol: predicting protein solubility by benchmarking multiple protein language models with the updated Escherichia coli protein solubility dataset.
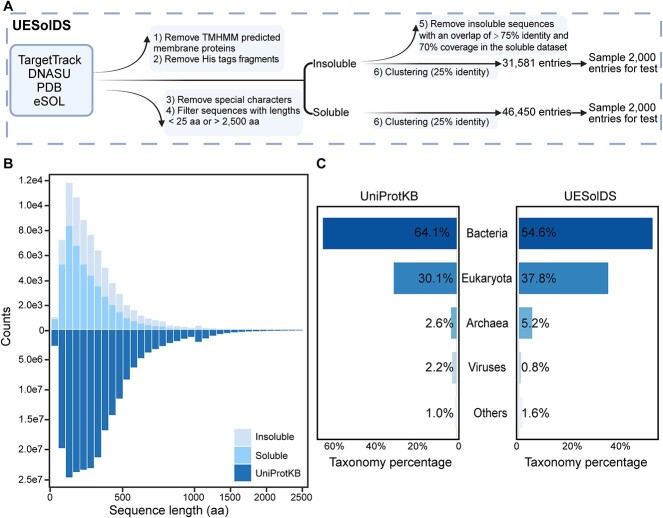
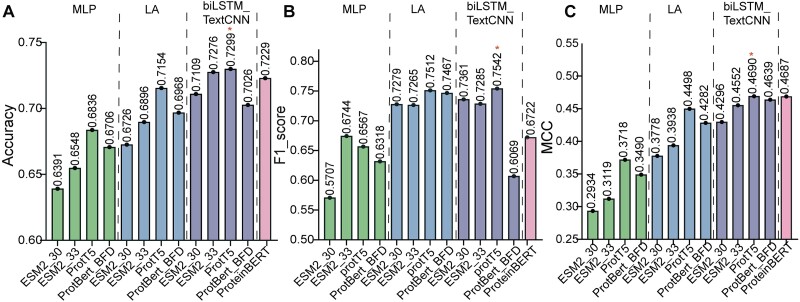
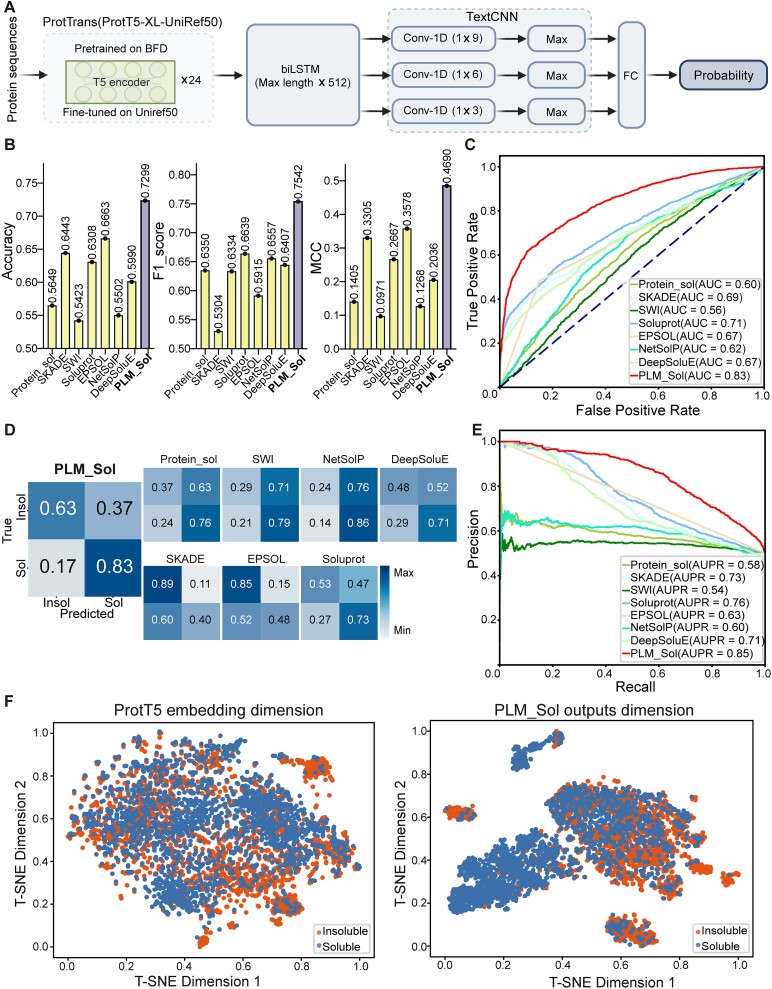
Protein solubility plays a crucial role in various biotechnological, industrial, and biomedical applications. With the reduction in sequencing and gene synthesis costs, the adoption of high-throughput experimental screening coupled with tailored bioinformatic prediction has witnessed a rapidly growing trend for the development of novel functional enzymes of interest (EOI). High protein solubility rates are essential in this process and accurate prediction of solubility is a challenging task. As deep learning technology continues to evolve, attention-based protein language models (PLMs) can extract intrinsic information from protein sequences to a greater extent. Leveraging these models along with the increasing availability of protein solubility data inferred from structural database like the Protein Data Bank holds great potential to enhance the prediction of protein solubility. In this study, we curated an Updated Escherichia coli protein Solubility DataSet (UESolDS) and employed a combination of multiple PLMs and classification layers to predict protein solubility. The resulting best-performing model, named Protein Language Model-based protein Solubility prediction model (PLM_Sol), demonstrated significant improvements over previous reported models, achieving a notable 6.4% increase in accuracy, 9.0% increase in F1_score, and 11.1% increase in Matthews correlation coefficient score on the independent test set. Moreover, additional evaluation utilizing our in-house synthesized protein resource as test data, encompassing diverse types of enzymes, also showcased the good performance of PLM_Sol. Overall, PLM_Sol exhibited consistent and promising performance across both independent test set and experimental set, thereby making it well suited for facilitating large-scale EOI studies. PLM_Sol is available as a standalone program and as an easy-to-use model at https://zenodo.org/doi/10.5281/zenodo.10675340.
期刊介绍:
Briefings in Bioinformatics is an international journal serving as a platform for researchers and educators in the life sciences. It also appeals to mathematicians, statisticians, and computer scientists applying their expertise to biological challenges. The journal focuses on reviews tailored for users of databases and analytical tools in contemporary genetics, molecular and systems biology. It stands out by offering practical assistance and guidance to non-specialists in computerized methodologies. Covering a wide range from introductory concepts to specific protocols and analyses, the papers address bacterial, plant, fungal, animal, and human data.
The journal's detailed subject areas include genetic studies of phenotypes and genotypes, mapping, DNA sequencing, expression profiling, gene expression studies, microarrays, alignment methods, protein profiles and HMMs, lipids, metabolic and signaling pathways, structure determination and function prediction, phylogenetic studies, and education and training.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


