{"title":"生成式大语言模型的零次和少量提示可对临床试验中的偏差风险进行微弱评估。","authors":"Simon Šuster, Timothy Baldwin, Karin Verspoor","doi":"10.1002/jrsm.1749","DOIUrl":null,"url":null,"abstract":"<p>Existing systems for automating the assessment of risk-of-bias (RoB) in medical studies are supervised approaches that require substantial training data to work well. However, recent revisions to RoB guidelines have resulted in a scarcity of available training data. In this study, we investigate the effectiveness of generative large language models (LLMs) for assessing RoB. Their application requires little or no training data and, if successful, could serve as a valuable tool to assist human experts during the construction of systematic reviews. Following Cochrane's latest guidelines (RoB2) designed for human reviewers, we prepare instructions that are fed as input to LLMs, which then infer the risk associated with a trial publication. We distinguish between two modelling tasks: directly predicting RoB2 from text; and employing decomposition, in which a RoB2 decision is made after the LLM responds to a series of signalling questions. We curate new testing data sets and evaluate the performance of four general- and medical-domain LLMs. The results fall short of expectations, with LLMs seldom surpassing trivial baselines. On the direct RoB2 prediction test set (<i>n</i> = 5993), LLMs perform akin to the baselines (F1: 0.1–0.2). In the decomposition task setup (<i>n</i> = 28,150), similar F1 scores are observed. Our additional comparative evaluation on RoB1 data also reveals results substantially below those of a supervised system. This testifies to the difficulty of solving this task based on (complex) instructions alone. Using LLMs as an assisting technology for assessing RoB2 thus currently seems beyond their reach.</p>","PeriodicalId":226,"journal":{"name":"Research Synthesis Methods","volume":"15 6","pages":"988-1000"},"PeriodicalIF":6.1000,"publicationDate":"2024-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/jrsm.1749","citationCount":"0","resultStr":"{\"title\":\"Zero- and few-shot prompting of generative large language models provides weak assessment of risk of bias in clinical trials\",\"authors\":\"Simon Šuster, Timothy Baldwin, Karin Verspoor\",\"doi\":\"10.1002/jrsm.1749\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Existing systems for automating the assessment of risk-of-bias (RoB) in medical studies are supervised approaches that require substantial training data to work well. However, recent revisions to RoB guidelines have resulted in a scarcity of available training data. In this study, we investigate the effectiveness of generative large language models (LLMs) for assessing RoB. Their application requires little or no training data and, if successful, could serve as a valuable tool to assist human experts during the construction of systematic reviews. Following Cochrane's latest guidelines (RoB2) designed for human reviewers, we prepare instructions that are fed as input to LLMs, which then infer the risk associated with a trial publication. We distinguish between two modelling tasks: directly predicting RoB2 from text; and employing decomposition, in which a RoB2 decision is made after the LLM responds to a series of signalling questions. We curate new testing data sets and evaluate the performance of four general- and medical-domain LLMs. The results fall short of expectations, with LLMs seldom surpassing trivial baselines. On the direct RoB2 prediction test set (<i>n</i> = 5993), LLMs perform akin to the baselines (F1: 0.1–0.2). In the decomposition task setup (<i>n</i> = 28,150), similar F1 scores are observed. Our additional comparative evaluation on RoB1 data also reveals results substantially below those of a supervised system. This testifies to the difficulty of solving this task based on (complex) instructions alone. Using LLMs as an assisting technology for assessing RoB2 thus currently seems beyond their reach.</p>\",\"PeriodicalId\":226,\"journal\":{\"name\":\"Research Synthesis Methods\",\"volume\":\"15 6\",\"pages\":\"988-1000\"},\"PeriodicalIF\":6.1000,\"publicationDate\":\"2024-08-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/jrsm.1749\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Research Synthesis Methods\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/jrsm.1749\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Research Synthesis Methods","FirstCategoryId":"99","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/jrsm.1749","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Zero- and few-shot prompting of generative large language models provides weak assessment of risk of bias in clinical trials
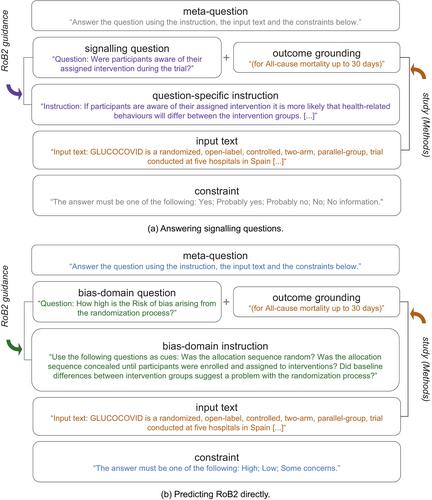
Existing systems for automating the assessment of risk-of-bias (RoB) in medical studies are supervised approaches that require substantial training data to work well. However, recent revisions to RoB guidelines have resulted in a scarcity of available training data. In this study, we investigate the effectiveness of generative large language models (LLMs) for assessing RoB. Their application requires little or no training data and, if successful, could serve as a valuable tool to assist human experts during the construction of systematic reviews. Following Cochrane's latest guidelines (RoB2) designed for human reviewers, we prepare instructions that are fed as input to LLMs, which then infer the risk associated with a trial publication. We distinguish between two modelling tasks: directly predicting RoB2 from text; and employing decomposition, in which a RoB2 decision is made after the LLM responds to a series of signalling questions. We curate new testing data sets and evaluate the performance of four general- and medical-domain LLMs. The results fall short of expectations, with LLMs seldom surpassing trivial baselines. On the direct RoB2 prediction test set (n = 5993), LLMs perform akin to the baselines (F1: 0.1–0.2). In the decomposition task setup (n = 28,150), similar F1 scores are observed. Our additional comparative evaluation on RoB1 data also reveals results substantially below those of a supervised system. This testifies to the difficulty of solving this task based on (complex) instructions alone. Using LLMs as an assisting technology for assessing RoB2 thus currently seems beyond their reach.
期刊介绍:
Research Synthesis Methods is a reputable, peer-reviewed journal that focuses on the development and dissemination of methods for conducting systematic research synthesis. Our aim is to advance the knowledge and application of research synthesis methods across various disciplines.
Our journal provides a platform for the exchange of ideas and knowledge related to designing, conducting, analyzing, interpreting, reporting, and applying research synthesis. While research synthesis is commonly practiced in the health and social sciences, our journal also welcomes contributions from other fields to enrich the methodologies employed in research synthesis across scientific disciplines.
By bridging different disciplines, we aim to foster collaboration and cross-fertilization of ideas, ultimately enhancing the quality and effectiveness of research synthesis methods. Whether you are a researcher, practitioner, or stakeholder involved in research synthesis, our journal strives to offer valuable insights and practical guidance for your work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


