{"title":"野外细粒度单目三维人脸重建的自我监督学习","authors":"Dongjin Huang, Yongsheng Shi, Jinhua Liu, Wen Tang","doi":"10.1007/s00530-024-01436-3","DOIUrl":null,"url":null,"abstract":"<p>Reconstructing 3D face from monocular images is a challenging computer vision task, due to the limitations of traditional 3DMM (3D Morphable Model) and the lack of high-fidelity 3D facial scanning data. To solve this issue, we propose a novel coarse-to-fine self-supervised learning framework for reconstructing fine-grained 3D faces from monocular images in the wild. In the coarse stage, face parameters extracted from a single image are used to reconstruct a coarse 3D face through a 3DMM. In the refinement stage, we design a wavelet transform perception model to extract facial details in different frequency domains from an input image. Furthermore, we propose a depth displacement module based on the wavelet transform perception model to generate a refined displacement map from the unwrapped UV textures of the input image and rendered coarse face, which can be used to synthesize detailed 3D face geometry. Moreover, we propose a novel albedo map module based on the wavelet transform perception model to capture high-frequency texture information and generate a detailed albedo map consistent with face illumination. The detailed face geometry and albedo map are used to reconstruct a fine-grained 3D face without any labeled data. We have conducted extensive experiments that demonstrate the superiority of our method over existing state-of-the-art approaches for 3D face reconstruction on four public datasets including CelebA, LS3D, LFW, and NoW benchmark. The experimental results indicate that our method achieved higher accuracy and robustness, particularly of under the challenging conditions such as occlusion, large poses, and varying illuminations.</p>","PeriodicalId":51138,"journal":{"name":"Multimedia Systems","volume":"23 1","pages":""},"PeriodicalIF":3.5000,"publicationDate":"2024-08-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Self-supervised learning for fine-grained monocular 3D face reconstruction in the wild\",\"authors\":\"Dongjin Huang, Yongsheng Shi, Jinhua Liu, Wen Tang\",\"doi\":\"10.1007/s00530-024-01436-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Reconstructing 3D face from monocular images is a challenging computer vision task, due to the limitations of traditional 3DMM (3D Morphable Model) and the lack of high-fidelity 3D facial scanning data. To solve this issue, we propose a novel coarse-to-fine self-supervised learning framework for reconstructing fine-grained 3D faces from monocular images in the wild. In the coarse stage, face parameters extracted from a single image are used to reconstruct a coarse 3D face through a 3DMM. In the refinement stage, we design a wavelet transform perception model to extract facial details in different frequency domains from an input image. Furthermore, we propose a depth displacement module based on the wavelet transform perception model to generate a refined displacement map from the unwrapped UV textures of the input image and rendered coarse face, which can be used to synthesize detailed 3D face geometry. Moreover, we propose a novel albedo map module based on the wavelet transform perception model to capture high-frequency texture information and generate a detailed albedo map consistent with face illumination. The detailed face geometry and albedo map are used to reconstruct a fine-grained 3D face without any labeled data. We have conducted extensive experiments that demonstrate the superiority of our method over existing state-of-the-art approaches for 3D face reconstruction on four public datasets including CelebA, LS3D, LFW, and NoW benchmark. The experimental results indicate that our method achieved higher accuracy and robustness, particularly of under the challenging conditions such as occlusion, large poses, and varying illuminations.</p>\",\"PeriodicalId\":51138,\"journal\":{\"name\":\"Multimedia Systems\",\"volume\":\"23 1\",\"pages\":\"\"},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2024-08-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Multimedia Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00530-024-01436-3\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Multimedia Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00530-024-01436-3","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
引用次数: 0
摘要
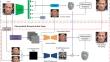
由于传统 3DMM(三维可变形模型)的局限性和高保真三维面部扫描数据的缺乏,从单目图像重建三维人脸是一项极具挑战性的计算机视觉任务。为了解决这个问题,我们提出了一种新颖的从粗到细的自监督学习框架,用于从野外单目图像中重建细粒度三维人脸。在粗粒度阶段,从单张图像中提取的人脸参数被用于通过 3DMM 重建粗粒度 3D 人脸。在细化阶段,我们设计了一个小波变换感知模型,从输入图像中提取不同频域的面部细节。此外,我们还提出了一个基于小波变换感知模型的深度位移模块,从输入图像和渲染后的粗略人脸的未包裹 UV 纹理中生成精细的位移图,用于合成详细的三维人脸几何图形。此外,我们还提出了基于小波变换感知模型的新型反照率图模块,用于捕捉高频纹理信息并生成与人脸光照一致的详细反照率图。详细的人脸几何图形和反照率图用于在没有任何标记数据的情况下重建精细的三维人脸。我们在 CelebA、LS3D、LFW 和 NoW 基准等四个公共数据集上进行了大量实验,证明我们的方法优于现有的最先进的三维人脸重建方法。实验结果表明,我们的方法实现了更高的准确性和鲁棒性,尤其是在遮挡、大姿势和不同光照等具有挑战性的条件下。
Self-supervised learning for fine-grained monocular 3D face reconstruction in the wild
Reconstructing 3D face from monocular images is a challenging computer vision task, due to the limitations of traditional 3DMM (3D Morphable Model) and the lack of high-fidelity 3D facial scanning data. To solve this issue, we propose a novel coarse-to-fine self-supervised learning framework for reconstructing fine-grained 3D faces from monocular images in the wild. In the coarse stage, face parameters extracted from a single image are used to reconstruct a coarse 3D face through a 3DMM. In the refinement stage, we design a wavelet transform perception model to extract facial details in different frequency domains from an input image. Furthermore, we propose a depth displacement module based on the wavelet transform perception model to generate a refined displacement map from the unwrapped UV textures of the input image and rendered coarse face, which can be used to synthesize detailed 3D face geometry. Moreover, we propose a novel albedo map module based on the wavelet transform perception model to capture high-frequency texture information and generate a detailed albedo map consistent with face illumination. The detailed face geometry and albedo map are used to reconstruct a fine-grained 3D face without any labeled data. We have conducted extensive experiments that demonstrate the superiority of our method over existing state-of-the-art approaches for 3D face reconstruction on four public datasets including CelebA, LS3D, LFW, and NoW benchmark. The experimental results indicate that our method achieved higher accuracy and robustness, particularly of under the challenging conditions such as occlusion, large poses, and varying illuminations.
期刊介绍:
This journal details innovative research ideas, emerging technologies, state-of-the-art methods and tools in all aspects of multimedia computing, communication, storage, and applications. It features theoretical, experimental, and survey articles.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


