David Amadi, Sylvia Kiwuwa-Muyingo, Tathagata Bhattacharjee, Amelia Taylor, Agnes Kiragga, Michael Ochola, Chifundo Kanjala, Arofan Gregory, Keith Tomlin, Jim Todd, Jay Greenfield
{"title":"使元数据机器可读是提供可查找、可访问、可互操作和可重复使用的人口健康数据的第一步:框架开发与实施研究》。","authors":"David Amadi, Sylvia Kiwuwa-Muyingo, Tathagata Bhattacharjee, Amelia Taylor, Agnes Kiragga, Michael Ochola, Chifundo Kanjala, Arofan Gregory, Keith Tomlin, Jim Todd, Jay Greenfield","doi":"10.2196/56237","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Metadata describe and provide context for other data, playing a pivotal role in enabling findability, accessibility, interoperability, and reusability (FAIR) data principles. By providing comprehensive and machine-readable descriptions of digital resources, metadata empower both machines and human users to seamlessly discover, access, integrate, and reuse data or content across diverse platforms and applications. However, the limited accessibility and machine-interpretability of existing metadata for population health data hinder effective data discovery and reuse.</p><p><strong>Objective: </strong>To address these challenges, we propose a comprehensive framework using standardized formats, vocabularies, and protocols to render population health data machine-readable, significantly enhancing their FAIRness and enabling seamless discovery, access, and integration across diverse platforms and research applications.</p><p><strong>Methods: </strong>The framework implements a 3-stage approach. The first stage is Data Documentation Initiative (DDI) integration, which involves leveraging the DDI Codebook metadata and documentation of detailed information for data and associated assets, while ensuring transparency and comprehensiveness. The second stage is Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) standardization. In this stage, the data are harmonized and standardized into the OMOP CDM, facilitating unified analysis across heterogeneous data sets. The third stage involves the integration of Schema.org and JavaScript Object Notation for Linked Data (JSON-LD), in which machine-readable metadata are generated using Schema.org entities and embedded within the data using JSON-LD, boosting discoverability and comprehension for both machines and human users. We demonstrated the implementation of these 3 stages using the Integrated Disease Surveillance and Response (IDSR) data from Malawi and Kenya.</p><p><strong>Results: </strong>The implementation of our framework significantly enhanced the FAIRness of population health data, resulting in improved discoverability through seamless integration with platforms such as Google Dataset Search. The adoption of standardized formats and protocols streamlined data accessibility and integration across various research environments, fostering collaboration and knowledge sharing. Additionally, the use of machine-interpretable metadata empowered researchers to efficiently reuse data for targeted analyses and insights, thereby maximizing the overall value of population health resources. The JSON-LD codes are accessible via a GitHub repository and the HTML code integrated with JSON-LD is available on the Implementation Network for Sharing Population Information from Research Entities website.</p><p><strong>Conclusions: </strong>The adoption of machine-readable metadata standards is essential for ensuring the FAIRness of population health data. By embracing these standards, organizations can enhance diverse resource visibility, accessibility, and utility, leading to a broader impact, particularly in low- and middle-income countries. Machine-readable metadata can accelerate research, improve health care decision-making, and ultimately promote better health outcomes for populations worldwide.</p>","PeriodicalId":74345,"journal":{"name":"Online journal of public health informatics","volume":"16 ","pages":"e56237"},"PeriodicalIF":1.1000,"publicationDate":"2024-08-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11327634/pdf/","citationCount":"0","resultStr":"{\"title\":\"Making Metadata Machine-Readable as the First Step to Providing Findable, Accessible, Interoperable, and Reusable Population Health Data: Framework Development and Implementation Study.\",\"authors\":\"David Amadi, Sylvia Kiwuwa-Muyingo, Tathagata Bhattacharjee, Amelia Taylor, Agnes Kiragga, Michael Ochola, Chifundo Kanjala, Arofan Gregory, Keith Tomlin, Jim Todd, Jay Greenfield\",\"doi\":\"10.2196/56237\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Metadata describe and provide context for other data, playing a pivotal role in enabling findability, accessibility, interoperability, and reusability (FAIR) data principles. By providing comprehensive and machine-readable descriptions of digital resources, metadata empower both machines and human users to seamlessly discover, access, integrate, and reuse data or content across diverse platforms and applications. However, the limited accessibility and machine-interpretability of existing metadata for population health data hinder effective data discovery and reuse.</p><p><strong>Objective: </strong>To address these challenges, we propose a comprehensive framework using standardized formats, vocabularies, and protocols to render population health data machine-readable, significantly enhancing their FAIRness and enabling seamless discovery, access, and integration across diverse platforms and research applications.</p><p><strong>Methods: </strong>The framework implements a 3-stage approach. The first stage is Data Documentation Initiative (DDI) integration, which involves leveraging the DDI Codebook metadata and documentation of detailed information for data and associated assets, while ensuring transparency and comprehensiveness. The second stage is Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) standardization. In this stage, the data are harmonized and standardized into the OMOP CDM, facilitating unified analysis across heterogeneous data sets. The third stage involves the integration of Schema.org and JavaScript Object Notation for Linked Data (JSON-LD), in which machine-readable metadata are generated using Schema.org entities and embedded within the data using JSON-LD, boosting discoverability and comprehension for both machines and human users. We demonstrated the implementation of these 3 stages using the Integrated Disease Surveillance and Response (IDSR) data from Malawi and Kenya.</p><p><strong>Results: </strong>The implementation of our framework significantly enhanced the FAIRness of population health data, resulting in improved discoverability through seamless integration with platforms such as Google Dataset Search. The adoption of standardized formats and protocols streamlined data accessibility and integration across various research environments, fostering collaboration and knowledge sharing. Additionally, the use of machine-interpretable metadata empowered researchers to efficiently reuse data for targeted analyses and insights, thereby maximizing the overall value of population health resources. The JSON-LD codes are accessible via a GitHub repository and the HTML code integrated with JSON-LD is available on the Implementation Network for Sharing Population Information from Research Entities website.</p><p><strong>Conclusions: </strong>The adoption of machine-readable metadata standards is essential for ensuring the FAIRness of population health data. By embracing these standards, organizations can enhance diverse resource visibility, accessibility, and utility, leading to a broader impact, particularly in low- and middle-income countries. Machine-readable metadata can accelerate research, improve health care decision-making, and ultimately promote better health outcomes for populations worldwide.</p>\",\"PeriodicalId\":74345,\"journal\":{\"name\":\"Online journal of public health informatics\",\"volume\":\"16 \",\"pages\":\"e56237\"},\"PeriodicalIF\":1.1000,\"publicationDate\":\"2024-08-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11327634/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Online journal of public health informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/56237\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Online journal of public health informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/56237","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Making Metadata Machine-Readable as the First Step to Providing Findable, Accessible, Interoperable, and Reusable Population Health Data: Framework Development and Implementation Study.
Background: Metadata describe and provide context for other data, playing a pivotal role in enabling findability, accessibility, interoperability, and reusability (FAIR) data principles. By providing comprehensive and machine-readable descriptions of digital resources, metadata empower both machines and human users to seamlessly discover, access, integrate, and reuse data or content across diverse platforms and applications. However, the limited accessibility and machine-interpretability of existing metadata for population health data hinder effective data discovery and reuse.
Objective: To address these challenges, we propose a comprehensive framework using standardized formats, vocabularies, and protocols to render population health data machine-readable, significantly enhancing their FAIRness and enabling seamless discovery, access, and integration across diverse platforms and research applications.
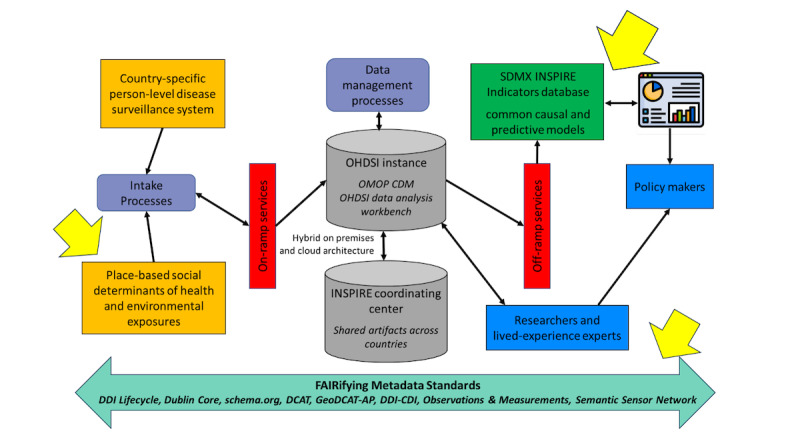
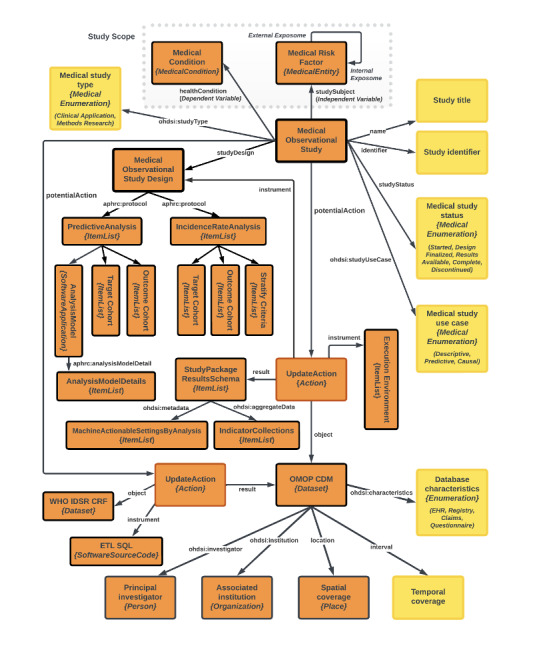
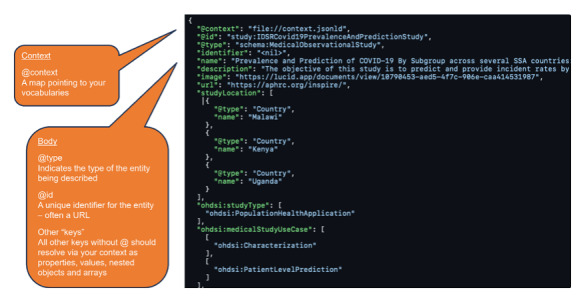
Methods: The framework implements a 3-stage approach. The first stage is Data Documentation Initiative (DDI) integration, which involves leveraging the DDI Codebook metadata and documentation of detailed information for data and associated assets, while ensuring transparency and comprehensiveness. The second stage is Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) standardization. In this stage, the data are harmonized and standardized into the OMOP CDM, facilitating unified analysis across heterogeneous data sets. The third stage involves the integration of Schema.org and JavaScript Object Notation for Linked Data (JSON-LD), in which machine-readable metadata are generated using Schema.org entities and embedded within the data using JSON-LD, boosting discoverability and comprehension for both machines and human users. We demonstrated the implementation of these 3 stages using the Integrated Disease Surveillance and Response (IDSR) data from Malawi and Kenya.
Results: The implementation of our framework significantly enhanced the FAIRness of population health data, resulting in improved discoverability through seamless integration with platforms such as Google Dataset Search. The adoption of standardized formats and protocols streamlined data accessibility and integration across various research environments, fostering collaboration and knowledge sharing. Additionally, the use of machine-interpretable metadata empowered researchers to efficiently reuse data for targeted analyses and insights, thereby maximizing the overall value of population health resources. The JSON-LD codes are accessible via a GitHub repository and the HTML code integrated with JSON-LD is available on the Implementation Network for Sharing Population Information from Research Entities website.
Conclusions: The adoption of machine-readable metadata standards is essential for ensuring the FAIRness of population health data. By embracing these standards, organizations can enhance diverse resource visibility, accessibility, and utility, leading to a broader impact, particularly in low- and middle-income countries. Machine-readable metadata can accelerate research, improve health care decision-making, and ultimately promote better health outcomes for populations worldwide.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


