{"title":"基于 NLP 的商业和学术智能决策","authors":"Pradnya Sawant, Kavita Sonawane","doi":"10.1016/j.nlp.2024.100090","DOIUrl":null,"url":null,"abstract":"<div><p>Natural Language Processing (NLP) systems enable machines to understand, interpret, and generate human-like language, bridging the gap between human communication and computer understanding. Natural Language Interface to Databases (NLIDB) and Natural Language Interface to Visualization (NLIV) systems are designed to enable non-technical users to retrieve and visualize data through natural language queries. However, these systems often face challenges in handling complex correlation and analytical questions, limiting their effectiveness for comprehensive data analysis. Additionally, current Business Intelligence (BI) tools also struggle with understanding the context and semantics of complex questions, further hindering their usability for strategic decision-making. Also, when building these models for generating the queries from natural language, the system handles only the semantic parsing issues as each column header is being changed manually to their normal names by all existing models which is time-consuming, tedious, and subjective.</p><p>Recent studies reflect the need for attention to context, semantics, and especially ambiguities in dealing with natural language questions. To address this problem, the proposed architecture focuses on understanding the context, correlation-based semantic analysis, and removal of ambiguities using a novel approach. An Enhanced Longest Common Subsequence (ELCS) is suggested where existing LCS is modified with a memorization component for mapping the natural language question tokens with ambiguous table column headers. This can speed up the overall process as human intervention is not required to manually change the column headers. The same is evidenced by carrying out thorough experimentation and comparative study in terms of precision, recall, and F1 score. By synthesizing the latest advancements and addressing challenges, this paper has proved how NLP can significantly enhance the accuracy and efficiency of information retrieval and visualization, broadening the inclusivity and usability of NLIDB, NLIV, and BI systems.</p></div>","PeriodicalId":100944,"journal":{"name":"Natural Language Processing Journal","volume":"8 ","pages":"Article 100090"},"PeriodicalIF":0.0000,"publicationDate":"2024-07-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2949719124000384/pdfft?md5=fd2e14b2d3243c083595a7e1f7015f23&pid=1-s2.0-S2949719124000384-main.pdf","citationCount":"0","resultStr":"{\"title\":\"NLP-based smart decision making for business and academics\",\"authors\":\"Pradnya Sawant, Kavita Sonawane\",\"doi\":\"10.1016/j.nlp.2024.100090\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Natural Language Processing (NLP) systems enable machines to understand, interpret, and generate human-like language, bridging the gap between human communication and computer understanding. Natural Language Interface to Databases (NLIDB) and Natural Language Interface to Visualization (NLIV) systems are designed to enable non-technical users to retrieve and visualize data through natural language queries. However, these systems often face challenges in handling complex correlation and analytical questions, limiting their effectiveness for comprehensive data analysis. Additionally, current Business Intelligence (BI) tools also struggle with understanding the context and semantics of complex questions, further hindering their usability for strategic decision-making. Also, when building these models for generating the queries from natural language, the system handles only the semantic parsing issues as each column header is being changed manually to their normal names by all existing models which is time-consuming, tedious, and subjective.</p><p>Recent studies reflect the need for attention to context, semantics, and especially ambiguities in dealing with natural language questions. To address this problem, the proposed architecture focuses on understanding the context, correlation-based semantic analysis, and removal of ambiguities using a novel approach. An Enhanced Longest Common Subsequence (ELCS) is suggested where existing LCS is modified with a memorization component for mapping the natural language question tokens with ambiguous table column headers. This can speed up the overall process as human intervention is not required to manually change the column headers. The same is evidenced by carrying out thorough experimentation and comparative study in terms of precision, recall, and F1 score. By synthesizing the latest advancements and addressing challenges, this paper has proved how NLP can significantly enhance the accuracy and efficiency of information retrieval and visualization, broadening the inclusivity and usability of NLIDB, NLIV, and BI systems.</p></div>\",\"PeriodicalId\":100944,\"journal\":{\"name\":\"Natural Language Processing Journal\",\"volume\":\"8 \",\"pages\":\"Article 100090\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-07-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2949719124000384/pdfft?md5=fd2e14b2d3243c083595a7e1f7015f23&pid=1-s2.0-S2949719124000384-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Natural Language Processing Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2949719124000384\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Natural Language Processing Journal","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2949719124000384","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
自然语言处理(NLP)系统使机器能够理解、解释和生成类似人类的语言,在人类交流和计算机理解之间架起了一座桥梁。数据库自然语言界面(NLIDB)和可视化自然语言界面(NLIV)系统旨在让非技术用户能够通过自然语言查询检索和可视化数据。然而,这些系统在处理复杂的关联和分析问题时往往面临挑战,从而限制了它们在综合数据分析方面的有效性。此外,当前的商业智能(BI)工具也很难理解复杂问题的上下文和语义,进一步阻碍了它们在战略决策方面的可用性。此外,在建立这些模型以生成自然语言查询时,系统只处理语义解析问题,因为所有现有模型都要手动将每一列的标题更改为它们的正常名称,这既费时、乏味,又主观。为了解决这个问题,我们提出的架构侧重于理解上下文、基于相关性的语义分析以及使用一种新方法消除歧义。建议采用增强型最长公共序列(ELCS),在现有 LCS 的基础上增加一个记忆组件,用于将自然语言问题标记与含糊不清的表列标题进行映射。这可以加快整个流程,因为不需要人工干预来手动更改列标题。在精确度、召回率和 F1 分数方面进行的全面实验和比较研究也证明了这一点。通过综合最新进展和应对挑战,本文证明了 NLP 如何能够显著提高信息检索和可视化的准确性和效率,扩大 NLIDB、NLIV 和 BI 系统的包容性和可用性。
NLP-based smart decision making for business and academics
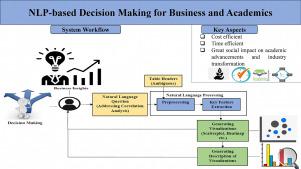
Natural Language Processing (NLP) systems enable machines to understand, interpret, and generate human-like language, bridging the gap between human communication and computer understanding. Natural Language Interface to Databases (NLIDB) and Natural Language Interface to Visualization (NLIV) systems are designed to enable non-technical users to retrieve and visualize data through natural language queries. However, these systems often face challenges in handling complex correlation and analytical questions, limiting their effectiveness for comprehensive data analysis. Additionally, current Business Intelligence (BI) tools also struggle with understanding the context and semantics of complex questions, further hindering their usability for strategic decision-making. Also, when building these models for generating the queries from natural language, the system handles only the semantic parsing issues as each column header is being changed manually to their normal names by all existing models which is time-consuming, tedious, and subjective.
Recent studies reflect the need for attention to context, semantics, and especially ambiguities in dealing with natural language questions. To address this problem, the proposed architecture focuses on understanding the context, correlation-based semantic analysis, and removal of ambiguities using a novel approach. An Enhanced Longest Common Subsequence (ELCS) is suggested where existing LCS is modified with a memorization component for mapping the natural language question tokens with ambiguous table column headers. This can speed up the overall process as human intervention is not required to manually change the column headers. The same is evidenced by carrying out thorough experimentation and comparative study in terms of precision, recall, and F1 score. By synthesizing the latest advancements and addressing challenges, this paper has proved how NLP can significantly enhance the accuracy and efficiency of information retrieval and visualization, broadening the inclusivity and usability of NLIDB, NLIV, and BI systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


