{"title":"无需梯度计算的结构化随机曲线拟合","authors":"Jixin Chen","doi":"10.1016/j.jcmds.2024.100097","DOIUrl":null,"url":null,"abstract":"<div><p>Optimization of parameters and hyperparameters is a general process for any data analysis. Because not all models are mathematically well-behaved, stochastic optimization can be useful in many analyses by randomly choosing parameters in each optimization iteration. Many such algorithms have been reported and applied in chemistry data analysis, but the one reported here is interesting to check out, where a naïve algorithm searches each parameter sequentially and randomly in its bounds. Then it picks the best for the next iteration. Thus, one can ignore irrational solution of the model itself or its gradient in parameter space and continue the optimization.</p></div>","PeriodicalId":100768,"journal":{"name":"Journal of Computational Mathematics and Data Science","volume":"12 ","pages":"Article 100097"},"PeriodicalIF":0.0000,"publicationDate":"2024-07-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2772415824000087/pdfft?md5=d29b0c976e4cd3877c7a001f5d45fd9a&pid=1-s2.0-S2772415824000087-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Structured stochastic curve fitting without gradient calculation\",\"authors\":\"Jixin Chen\",\"doi\":\"10.1016/j.jcmds.2024.100097\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Optimization of parameters and hyperparameters is a general process for any data analysis. Because not all models are mathematically well-behaved, stochastic optimization can be useful in many analyses by randomly choosing parameters in each optimization iteration. Many such algorithms have been reported and applied in chemistry data analysis, but the one reported here is interesting to check out, where a naïve algorithm searches each parameter sequentially and randomly in its bounds. Then it picks the best for the next iteration. Thus, one can ignore irrational solution of the model itself or its gradient in parameter space and continue the optimization.</p></div>\",\"PeriodicalId\":100768,\"journal\":{\"name\":\"Journal of Computational Mathematics and Data Science\",\"volume\":\"12 \",\"pages\":\"Article 100097\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-07-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2772415824000087/pdfft?md5=d29b0c976e4cd3877c7a001f5d45fd9a&pid=1-s2.0-S2772415824000087-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Computational Mathematics and Data Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2772415824000087\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Computational Mathematics and Data Science","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2772415824000087","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Structured stochastic curve fitting without gradient calculation
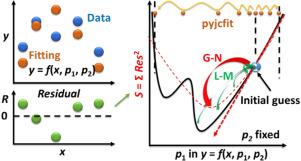
Optimization of parameters and hyperparameters is a general process for any data analysis. Because not all models are mathematically well-behaved, stochastic optimization can be useful in many analyses by randomly choosing parameters in each optimization iteration. Many such algorithms have been reported and applied in chemistry data analysis, but the one reported here is interesting to check out, where a naïve algorithm searches each parameter sequentially and randomly in its bounds. Then it picks the best for the next iteration. Thus, one can ignore irrational solution of the model itself or its gradient in parameter space and continue the optimization.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


