Stefan Hödl, Tal Kachman, Yoram Bachrach, Wilhelm T. S. Huck and William E. Robinson
{"title":"归因方法能向我们展示哪些化学语言模型?","authors":"Stefan Hödl, Tal Kachman, Yoram Bachrach, Wilhelm T. S. Huck and William E. Robinson","doi":"10.1039/D4DD00084F","DOIUrl":null,"url":null,"abstract":"<p >Language models trained on molecular string representations have shown strong performance in predictive and generative tasks. However, practical applications require not only making accurate predictions, but also explainability – the ability to explain the reasons and rationale behind the predictions. In this work, we explore explainability for a chemical language model by adapting a transformer-specific and a model-agnostic input attribution technique. We fine-tune a pretrained model to predict aqueous solubility, compare training and architecture variants, and evaluate visualizations of attributed relevance. The model-agnostic SHAP technique provides sensible attributions, highlighting the positive influence of individual electronegative atoms, but does not explain the model in terms of functional groups or explain how the model represents molecular strings internally to make predictions. In contrast, the adapted transformer-specific explainability technique produces sparse attributions, which cannot be directly attributed to functional groups relevant to solubility. Instead, the attributions are more characteristic of how the model maps molecular strings to its latent space, which seems to represent features relevant to molecular similarity rather than functional groups. These findings provide insight into the representations underpinning chemical language models, which we propose may be leveraged for the design of informative chemical spaces for training more accurate, advanced and explainable models.</p>","PeriodicalId":72816,"journal":{"name":"Digital discovery","volume":" 9","pages":" 1738-1748"},"PeriodicalIF":6.2000,"publicationDate":"2024-07-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://pubs.rsc.org/en/content/articlepdf/2024/dd/d4dd00084f?page=search","citationCount":"0","resultStr":"{\"title\":\"What can attribution methods show us about chemical language models?†‡\",\"authors\":\"Stefan Hödl, Tal Kachman, Yoram Bachrach, Wilhelm T. S. Huck and William E. Robinson\",\"doi\":\"10.1039/D4DD00084F\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Language models trained on molecular string representations have shown strong performance in predictive and generative tasks. However, practical applications require not only making accurate predictions, but also explainability – the ability to explain the reasons and rationale behind the predictions. In this work, we explore explainability for a chemical language model by adapting a transformer-specific and a model-agnostic input attribution technique. We fine-tune a pretrained model to predict aqueous solubility, compare training and architecture variants, and evaluate visualizations of attributed relevance. The model-agnostic SHAP technique provides sensible attributions, highlighting the positive influence of individual electronegative atoms, but does not explain the model in terms of functional groups or explain how the model represents molecular strings internally to make predictions. In contrast, the adapted transformer-specific explainability technique produces sparse attributions, which cannot be directly attributed to functional groups relevant to solubility. Instead, the attributions are more characteristic of how the model maps molecular strings to its latent space, which seems to represent features relevant to molecular similarity rather than functional groups. These findings provide insight into the representations underpinning chemical language models, which we propose may be leveraged for the design of informative chemical spaces for training more accurate, advanced and explainable models.</p>\",\"PeriodicalId\":72816,\"journal\":{\"name\":\"Digital discovery\",\"volume\":\" 9\",\"pages\":\" 1738-1748\"},\"PeriodicalIF\":6.2000,\"publicationDate\":\"2024-07-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://pubs.rsc.org/en/content/articlepdf/2024/dd/d4dd00084f?page=search\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Digital discovery\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://pubs.rsc.org/en/content/articlelanding/2024/dd/d4dd00084f\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Digital discovery","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2024/dd/d4dd00084f","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
What can attribution methods show us about chemical language models?†‡
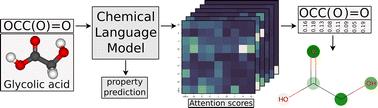
Language models trained on molecular string representations have shown strong performance in predictive and generative tasks. However, practical applications require not only making accurate predictions, but also explainability – the ability to explain the reasons and rationale behind the predictions. In this work, we explore explainability for a chemical language model by adapting a transformer-specific and a model-agnostic input attribution technique. We fine-tune a pretrained model to predict aqueous solubility, compare training and architecture variants, and evaluate visualizations of attributed relevance. The model-agnostic SHAP technique provides sensible attributions, highlighting the positive influence of individual electronegative atoms, but does not explain the model in terms of functional groups or explain how the model represents molecular strings internally to make predictions. In contrast, the adapted transformer-specific explainability technique produces sparse attributions, which cannot be directly attributed to functional groups relevant to solubility. Instead, the attributions are more characteristic of how the model maps molecular strings to its latent space, which seems to represent features relevant to molecular similarity rather than functional groups. These findings provide insight into the representations underpinning chemical language models, which we propose may be leveraged for the design of informative chemical spaces for training more accurate, advanced and explainable models.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


