Yiwen Lu , Jiayi Tong , Jessica Chubak , Thomas Lumley , Rebecca A Hubbard , Hua Xu , Yong Chen
{"title":"利用容易出错的算法衍生表型:加强电子病历数据中风险因素的关联研究。","authors":"Yiwen Lu , Jiayi Tong , Jessica Chubak , Thomas Lumley , Rebecca A Hubbard , Hua Xu , Yong Chen","doi":"10.1016/j.jbi.2024.104690","DOIUrl":null,"url":null,"abstract":"<div><h3>Objectives</h3><p>It has become increasingly common for multiple computable phenotypes from electronic health records (EHR) to be developed for a given phenotype. However, EHR-based association studies often focus on a single phenotype. In this paper, we develop a method aiming to simultaneously make use of multiple EHR-derived phenotypes for reduction of bias due to phenotyping error and improved efficiency of phenotype/exposure associations.</p></div><div><h3>Materials and Methods</h3><p>The proposed method combines multiple algorithm-derived phenotypes with a small set of validated outcomes to reduce bias and improve estimation accuracy and efficiency. The performance of our method was evaluated through simulation studies and real-world application to an analysis of colon cancer recurrence using EHR data from Kaiser Permanente Washington.</p></div><div><h3>Results</h3><p>In settings where there was no single surrogate performing uniformly better than all others in terms of both sensitivity and specificity, our method achieved substantial bias reduction compared to using a single algorithm-derived phenotype. Our method also led to higher estimation efficiency by up to 30% compared to an estimator that used only one algorithm-derived phenotype.</p></div><div><h3>Discussion</h3><p>Simulation studies and application to real-world data demonstrated the effectiveness of our method in integrating multiple phenotypes, thereby enhancing bias reduction, statistical accuracy and efficiency.</p></div><div><h3>Conclusions</h3><p>Our method combines information across multiple surrogates using a statistically efficient seemingly unrelated regression framework. Our method provides a robust alternative to single-surrogate-based bias correction, especially in contexts lacking information on which surrogate is superior.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"157 ","pages":"Article 104690"},"PeriodicalIF":4.0000,"publicationDate":"2024-07-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Leveraging error-prone algorithm-derived phenotypes: Enhancing association studies for risk factors in EHR data\",\"authors\":\"Yiwen Lu , Jiayi Tong , Jessica Chubak , Thomas Lumley , Rebecca A Hubbard , Hua Xu , Yong Chen\",\"doi\":\"10.1016/j.jbi.2024.104690\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objectives</h3><p>It has become increasingly common for multiple computable phenotypes from electronic health records (EHR) to be developed for a given phenotype. However, EHR-based association studies often focus on a single phenotype. In this paper, we develop a method aiming to simultaneously make use of multiple EHR-derived phenotypes for reduction of bias due to phenotyping error and improved efficiency of phenotype/exposure associations.</p></div><div><h3>Materials and Methods</h3><p>The proposed method combines multiple algorithm-derived phenotypes with a small set of validated outcomes to reduce bias and improve estimation accuracy and efficiency. The performance of our method was evaluated through simulation studies and real-world application to an analysis of colon cancer recurrence using EHR data from Kaiser Permanente Washington.</p></div><div><h3>Results</h3><p>In settings where there was no single surrogate performing uniformly better than all others in terms of both sensitivity and specificity, our method achieved substantial bias reduction compared to using a single algorithm-derived phenotype. Our method also led to higher estimation efficiency by up to 30% compared to an estimator that used only one algorithm-derived phenotype.</p></div><div><h3>Discussion</h3><p>Simulation studies and application to real-world data demonstrated the effectiveness of our method in integrating multiple phenotypes, thereby enhancing bias reduction, statistical accuracy and efficiency.</p></div><div><h3>Conclusions</h3><p>Our method combines information across multiple surrogates using a statistically efficient seemingly unrelated regression framework. Our method provides a robust alternative to single-surrogate-based bias correction, especially in contexts lacking information on which surrogate is superior.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"157 \",\"pages\":\"Article 104690\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-07-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424001084\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424001084","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
目的:从电子健康记录(EHR)中为特定表型开发多种可计算的表型已变得越来越普遍。然而,基于电子病历的关联研究通常只关注单一表型。在本文中,我们开发了一种方法,旨在同时利用多个 EHR 衍生表型,以减少表型错误造成的偏差,并提高表型/暴露关联的效率:所提出的方法将多种算法得出的表型与一小部分经过验证的结果相结合,以减少偏差并提高估计的准确性和效率。通过模拟研究和实际应用,利用华盛顿州凯撒医疗保健公司的电子病历数据对结肠癌复发进行分析,评估了我们方法的性能:结果:在灵敏度和特异性方面,没有任何一种替代物能比其他替代物表现得更好,与使用单一算法衍生的表型相比,我们的方法大大减少了偏差。与仅使用一种算法衍生表型的估算器相比,我们的方法还能提高估算效率达 30%:讨论:模拟研究和对真实世界数据的应用证明了我们的方法在整合多种表型方面的有效性,从而提高了偏差减少率、统计准确性和效率:结论:我们的方法利用统计上高效的看似无关回归框架整合了多个代用指标的信息。我们的方法为基于单一代用指标的偏差校正提供了一种稳健的替代方法,尤其是在缺乏代用指标优劣信息的情况下。
Leveraging error-prone algorithm-derived phenotypes: Enhancing association studies for risk factors in EHR data
Objectives
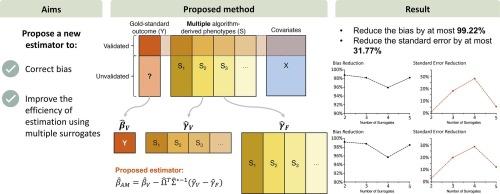
It has become increasingly common for multiple computable phenotypes from electronic health records (EHR) to be developed for a given phenotype. However, EHR-based association studies often focus on a single phenotype. In this paper, we develop a method aiming to simultaneously make use of multiple EHR-derived phenotypes for reduction of bias due to phenotyping error and improved efficiency of phenotype/exposure associations.
Materials and Methods
The proposed method combines multiple algorithm-derived phenotypes with a small set of validated outcomes to reduce bias and improve estimation accuracy and efficiency. The performance of our method was evaluated through simulation studies and real-world application to an analysis of colon cancer recurrence using EHR data from Kaiser Permanente Washington.
Results
In settings where there was no single surrogate performing uniformly better than all others in terms of both sensitivity and specificity, our method achieved substantial bias reduction compared to using a single algorithm-derived phenotype. Our method also led to higher estimation efficiency by up to 30% compared to an estimator that used only one algorithm-derived phenotype.
Discussion
Simulation studies and application to real-world data demonstrated the effectiveness of our method in integrating multiple phenotypes, thereby enhancing bias reduction, statistical accuracy and efficiency.
Conclusions
Our method combines information across multiple surrogates using a statistically efficient seemingly unrelated regression framework. Our method provides a robust alternative to single-surrogate-based bias correction, especially in contexts lacking information on which surrogate is superior.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


