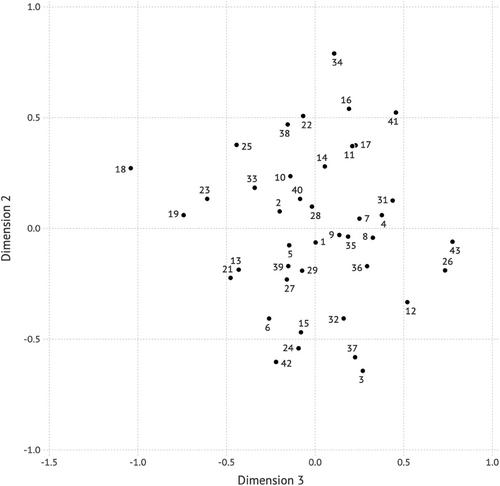
{"title":"利用话语世界分析语言变异","authors":"Heather Burnett, Julie Abbou, Gabriel Thiberge","doi":"10.1111/josl.12672","DOIUrl":null,"url":null,"abstract":"<p>Researchers in variationist sociolinguistics have long sought to develop social measures that are more sophisticated than demographic categories such as age, gender, and social class, while still being useful for quantitative analysis. This paper presents one such new measure: discursive worlds. For each speaker in a corpus, their discursive world is operationalized through compiling a list of specific referents cited in their interview. These lists are then used to construct similarity spaces locating the speakers along dimensions that are discursively relevant in the corpus. Using common clustering algorithms, the corpus speakers are then partitioned into categories, and this partition can be used in statistical analysis. We show how this method can be used to analyze a series of lexical variables in the <i>Cartographie linguistique des féminismes</i> corpus, a corpus of francophone interviews with feminist and queer activists, for which, we argue, quantitative analysis using classic demographic categories is inappropriate.</p>","PeriodicalId":51486,"journal":{"name":"Journal of Sociolinguistics","volume":"28 4","pages":"40-63"},"PeriodicalIF":2.6000,"publicationDate":"2024-07-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1111/josl.12672","citationCount":"0","resultStr":"{\"title\":\"Analyzing linguistic variation using discursive worlds\",\"authors\":\"Heather Burnett, Julie Abbou, Gabriel Thiberge\",\"doi\":\"10.1111/josl.12672\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Researchers in variationist sociolinguistics have long sought to develop social measures that are more sophisticated than demographic categories such as age, gender, and social class, while still being useful for quantitative analysis. This paper presents one such new measure: discursive worlds. For each speaker in a corpus, their discursive world is operationalized through compiling a list of specific referents cited in their interview. These lists are then used to construct similarity spaces locating the speakers along dimensions that are discursively relevant in the corpus. Using common clustering algorithms, the corpus speakers are then partitioned into categories, and this partition can be used in statistical analysis. We show how this method can be used to analyze a series of lexical variables in the <i>Cartographie linguistique des féminismes</i> corpus, a corpus of francophone interviews with feminist and queer activists, for which, we argue, quantitative analysis using classic demographic categories is inappropriate.</p>\",\"PeriodicalId\":51486,\"journal\":{\"name\":\"Journal of Sociolinguistics\",\"volume\":\"28 4\",\"pages\":\"40-63\"},\"PeriodicalIF\":2.6000,\"publicationDate\":\"2024-07-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1111/josl.12672\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Sociolinguistics\",\"FirstCategoryId\":\"98\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1111/josl.12672\",\"RegionNum\":1,\"RegionCategory\":\"文学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"LINGUISTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Sociolinguistics","FirstCategoryId":"98","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1111/josl.12672","RegionNum":1,"RegionCategory":"文学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"LINGUISTICS","Score":null,"Total":0}
引用次数: 0
摘要
长期以来,变异社会语言学的研究人员一直在寻求开发比年龄、性别和社会阶层等人口统计类别更复杂的社会测量方法,同时仍能用于定量分析。本文介绍了这样一种新的测量方法:话语世界。对于语料库中的每一位发言者,其话语世界都是通过编制其访谈中所引用的特定参照物列表来实现的。然后利用这些列表构建相似性空间,并根据语料库中与话语相关的维度对发言人进行定位。然后使用常见的聚类算法,将语料库中的发言人划分为不同类别,并将这一划分用于统计分析。我们展示了如何使用这种方法来分析 Cartographie linguistique des féminismes 语料库中的一系列词汇变量,该语料库是对女权主义者和同性恋活动家的法语访谈。
Analyzing linguistic variation using discursive worlds
Researchers in variationist sociolinguistics have long sought to develop social measures that are more sophisticated than demographic categories such as age, gender, and social class, while still being useful for quantitative analysis. This paper presents one such new measure: discursive worlds. For each speaker in a corpus, their discursive world is operationalized through compiling a list of specific referents cited in their interview. These lists are then used to construct similarity spaces locating the speakers along dimensions that are discursively relevant in the corpus. Using common clustering algorithms, the corpus speakers are then partitioned into categories, and this partition can be used in statistical analysis. We show how this method can be used to analyze a series of lexical variables in the Cartographie linguistique des féminismes corpus, a corpus of francophone interviews with feminist and queer activists, for which, we argue, quantitative analysis using classic demographic categories is inappropriate.
期刊介绍:
Journal of Sociolinguistics promotes sociolinguistics as a thoroughly linguistic and thoroughly social-scientific endeavour. The journal is concerned with language in all its dimensions, macro and micro, as formal features or abstract discourses, as situated talk or written text. Data in published articles represent a wide range of languages, regions and situations - from Alune to Xhosa, from Cameroun to Canada, from bulletin boards to dating ads.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


