Ruihong Wang, Chuqing Gao, Jianguo Wang, Prishita Kadam, M. TamerÖzsu, Walid G. Aref
{"title":"为分解内存优化基于 LSM 的索引","authors":"Ruihong Wang, Chuqing Gao, Jianguo Wang, Prishita Kadam, M. TamerÖzsu, Walid G. Aref","doi":"10.1007/s00778-024-00863-y","DOIUrl":null,"url":null,"abstract":"<p>The emerging trend of memory disaggregation where CPU and memory are physically separated from each other and are connected via ultra-fast networking, e.g., over Remote Direct Memory Access (RDMA), allows elastic and independent scaling of compute (CPU) and main memory. This paper investigates how indexing can be efficiently designed in the memory disaggregated architecture. Although existing research has optimized the B-tree for this new architecture, its performance is unsatisfactory. This paper focuses on LSM-based indexing and proposes <span>dLSM</span>,the first highly optimized LSM-tree for <u>d</u>isaggregated memory. <span>dLSM</span> introduces a suite of optimizations including reducing software overhead, leveraging near-data computing, tuning for byte-addressability, and an instantiation over RDMA as a case study with RDMA-specific customizations to improve system performance. Experiments illustrate that <span>dLSM</span> achieves 2.3<span>\\(\\times \\)</span> to 11.6<span>\\(\\times \\)</span> higher write throughput than running the optimized B-tree and four adaptations of existing LSM-tree indexes over disaggregated memory. <span>dLSM</span> is written in C++ (with approximately 54,400 LOC), and is open-sourced.</p>","PeriodicalId":501532,"journal":{"name":"The VLDB Journal","volume":"24 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Optimizing LSM-based indexes for disaggregated memory\",\"authors\":\"Ruihong Wang, Chuqing Gao, Jianguo Wang, Prishita Kadam, M. TamerÖzsu, Walid G. Aref\",\"doi\":\"10.1007/s00778-024-00863-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The emerging trend of memory disaggregation where CPU and memory are physically separated from each other and are connected via ultra-fast networking, e.g., over Remote Direct Memory Access (RDMA), allows elastic and independent scaling of compute (CPU) and main memory. This paper investigates how indexing can be efficiently designed in the memory disaggregated architecture. Although existing research has optimized the B-tree for this new architecture, its performance is unsatisfactory. This paper focuses on LSM-based indexing and proposes <span>dLSM</span>,the first highly optimized LSM-tree for <u>d</u>isaggregated memory. <span>dLSM</span> introduces a suite of optimizations including reducing software overhead, leveraging near-data computing, tuning for byte-addressability, and an instantiation over RDMA as a case study with RDMA-specific customizations to improve system performance. Experiments illustrate that <span>dLSM</span> achieves 2.3<span>\\\\(\\\\times \\\\)</span> to 11.6<span>\\\\(\\\\times \\\\)</span> higher write throughput than running the optimized B-tree and four adaptations of existing LSM-tree indexes over disaggregated memory. <span>dLSM</span> is written in C++ (with approximately 54,400 LOC), and is open-sourced.</p>\",\"PeriodicalId\":501532,\"journal\":{\"name\":\"The VLDB Journal\",\"volume\":\"24 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-06-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"The VLDB Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s00778-024-00863-y\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"The VLDB Journal","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s00778-024-00863-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
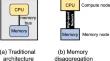
内存分解是一种新兴趋势,即 CPU 和内存物理上相互分离,并通过超快网络(如远程直接内存访问(RDMA))连接,从而实现计算(CPU)和主内存的弹性独立扩展。本文研究了如何在内存分解架构中高效设计索引。尽管现有研究已经针对这种新架构优化了 B 树,但其性能仍不尽如人意。dLSM 引入了一系列优化措施,包括减少软件开销、利用近数据计算、调整字节寻址能力,以及将 RDMA 实例化作为案例研究,并进行 RDMA 特定定制,以提高系统性能。实验表明,与在分解内存上运行优化的 B 树和现有 LSM 树索引的四种适应性相比,dLSM 的写吞吐量要高出 2.3 (\times \)到 11.6(\times \)。
Optimizing LSM-based indexes for disaggregated memory
The emerging trend of memory disaggregation where CPU and memory are physically separated from each other and are connected via ultra-fast networking, e.g., over Remote Direct Memory Access (RDMA), allows elastic and independent scaling of compute (CPU) and main memory. This paper investigates how indexing can be efficiently designed in the memory disaggregated architecture. Although existing research has optimized the B-tree for this new architecture, its performance is unsatisfactory. This paper focuses on LSM-based indexing and proposes dLSM,the first highly optimized LSM-tree for disaggregated memory. dLSM introduces a suite of optimizations including reducing software overhead, leveraging near-data computing, tuning for byte-addressability, and an instantiation over RDMA as a case study with RDMA-specific customizations to improve system performance. Experiments illustrate that dLSM achieves 2.3\(\times \) to 11.6\(\times \) higher write throughput than running the optimized B-tree and four adaptations of existing LSM-tree indexes over disaggregated memory. dLSM is written in C++ (with approximately 54,400 LOC), and is open-sourced.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


