{"title":"人类基因组中 DNA 功能词的范围限制 Heaps 定律。","authors":"Wentian Li , Yannis Almirantis , Astero Provata","doi":"10.1016/j.jtbi.2024.111878","DOIUrl":null,"url":null,"abstract":"<div><p>Heaps’ or Herdan-Heaps’ law is a linguistic law describing the relationship between the vocabulary/dictionary size (type) and word counts (token) to be a power-law function. Its existence in genomes with certain definition of DNA words is unclear partly because the dictionary size in genome could be much smaller than that in a human language. We define a DNA word as a coding region in a genome that codes for a protein domain. Using human chromosomes and chromosome arms as individual samples, we establish the existence of Heaps’ law in the human genome within limited range. Our definition of words in a genomic or proteomic context is different from other definitions such as over-represented k-mers which are much shorter in length. Although an approximate power-law distribution of protein domain sizes due to gene duplication and the related Zipf’s law is well known, their translation to the Heaps’ law in DNA words is not automatic. Several other animal genomes are shown herein also to exhibit range-limited Heaps’ law with our definition of DNA words, though with various exponents. When tokens were randomly sampled and sample sizes reach to the maximum level, a deviation from the Heaps’ law was observed, but a quadratic regression in log–log type-token plot fits the data perfectly. Investigation of type-token plot and its regression coefficients could provide an alternative narrative of reusage and redundancy of protein domains as well as creation of new protein domains from a linguistic perspective.</p></div>","PeriodicalId":54763,"journal":{"name":"Journal of Theoretical Biology","volume":"592 ","pages":"Article 111878"},"PeriodicalIF":1.9000,"publicationDate":"2024-06-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Range-limited Heaps’ law for functional DNA words in the human genome\",\"authors\":\"Wentian Li , Yannis Almirantis , Astero Provata\",\"doi\":\"10.1016/j.jtbi.2024.111878\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Heaps’ or Herdan-Heaps’ law is a linguistic law describing the relationship between the vocabulary/dictionary size (type) and word counts (token) to be a power-law function. Its existence in genomes with certain definition of DNA words is unclear partly because the dictionary size in genome could be much smaller than that in a human language. We define a DNA word as a coding region in a genome that codes for a protein domain. Using human chromosomes and chromosome arms as individual samples, we establish the existence of Heaps’ law in the human genome within limited range. Our definition of words in a genomic or proteomic context is different from other definitions such as over-represented k-mers which are much shorter in length. Although an approximate power-law distribution of protein domain sizes due to gene duplication and the related Zipf’s law is well known, their translation to the Heaps’ law in DNA words is not automatic. Several other animal genomes are shown herein also to exhibit range-limited Heaps’ law with our definition of DNA words, though with various exponents. When tokens were randomly sampled and sample sizes reach to the maximum level, a deviation from the Heaps’ law was observed, but a quadratic regression in log–log type-token plot fits the data perfectly. Investigation of type-token plot and its regression coefficients could provide an alternative narrative of reusage and redundancy of protein domains as well as creation of new protein domains from a linguistic perspective.</p></div>\",\"PeriodicalId\":54763,\"journal\":{\"name\":\"Journal of Theoretical Biology\",\"volume\":\"592 \",\"pages\":\"Article 111878\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2024-06-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Theoretical Biology\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0022519324001620\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Theoretical Biology","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0022519324001620","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
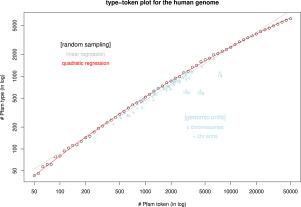
希普斯定律(Heaps' or Herdan's law)是一种语言学定律,它将词汇量/词典规模(类型)与字数(标记)之间的关系描述为幂律函数。目前还不清楚该定律是否存在于具有特定 DNA 词定义的基因组中,部分原因是基因组中的字典规模可能比人类语言中的字典规模小得多。我们将 DNA 词定义为基因组中编码蛋白质域的编码区域。我们以人类染色体和染色体臂为单个样本,在有限范围内确定了人类基因组中存在希普斯定律。我们对基因组或蛋白质组中的单词所下的定义不同于其他定义,例如长度更短的超比例 k-mers。虽然基因复制导致的蛋白质结构域大小的近似幂律分布和相关的齐普夫定律已广为人知,但它们在 DNA 单词中并不能自动转化为希普斯定律。根据我们对 DNA 单词的定义,其他几个动物基因组也表现出范围有限的 Heaps'定律,但指数各不相同。当标记词被随机抽样且样本量达到最大值时,就会出现偏离希普斯定律的情况,但类型-标记词对数图中的二次回归完全符合数据。对类型-令牌图及其回归系数的研究可以从语言学的角度为蛋白质结构域的重复使用和冗余以及新蛋白质结构域的产生提供另一种解释。
Range-limited Heaps’ law for functional DNA words in the human genome
Heaps’ or Herdan-Heaps’ law is a linguistic law describing the relationship between the vocabulary/dictionary size (type) and word counts (token) to be a power-law function. Its existence in genomes with certain definition of DNA words is unclear partly because the dictionary size in genome could be much smaller than that in a human language. We define a DNA word as a coding region in a genome that codes for a protein domain. Using human chromosomes and chromosome arms as individual samples, we establish the existence of Heaps’ law in the human genome within limited range. Our definition of words in a genomic or proteomic context is different from other definitions such as over-represented k-mers which are much shorter in length. Although an approximate power-law distribution of protein domain sizes due to gene duplication and the related Zipf’s law is well known, their translation to the Heaps’ law in DNA words is not automatic. Several other animal genomes are shown herein also to exhibit range-limited Heaps’ law with our definition of DNA words, though with various exponents. When tokens were randomly sampled and sample sizes reach to the maximum level, a deviation from the Heaps’ law was observed, but a quadratic regression in log–log type-token plot fits the data perfectly. Investigation of type-token plot and its regression coefficients could provide an alternative narrative of reusage and redundancy of protein domains as well as creation of new protein domains from a linguistic perspective.
期刊介绍:
The Journal of Theoretical Biology is the leading forum for theoretical perspectives that give insight into biological processes. It covers a very wide range of topics and is of interest to biologists in many areas of research, including:
• Brain and Neuroscience
• Cancer Growth and Treatment
• Cell Biology
• Developmental Biology
• Ecology
• Evolution
• Immunology,
• Infectious and non-infectious Diseases,
• Mathematical, Computational, Biophysical and Statistical Modeling
• Microbiology, Molecular Biology, and Biochemistry
• Networks and Complex Systems
• Physiology
• Pharmacodynamics
• Animal Behavior and Game Theory
Acceptable papers are those that bear significant importance on the biology per se being presented, and not on the mathematical analysis. Papers that include some data or experimental material bearing on theory will be considered, including those that contain comparative study, statistical data analysis, mathematical proof, computer simulations, experiments, field observations, or even philosophical arguments, which are all methods to support or reject theoretical ideas. However, there should be a concerted effort to make papers intelligible to biologists in the chosen field.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


