Milan Picard , Marie-Pier Scott-Boyer , Antoine Bodein , Mickaël Leclercq , Julien Prunier , Olivier Périn , Arnaud Droit
{"title":"利用多层网络和机器学习进行目标重新定位:前列腺癌案例。","authors":"Milan Picard , Marie-Pier Scott-Boyer , Antoine Bodein , Mickaël Leclercq , Julien Prunier , Olivier Périn , Arnaud Droit","doi":"10.1016/j.csbj.2024.06.012","DOIUrl":null,"url":null,"abstract":"<div><p>The discovery of novel therapeutic targets, defined as proteins which drugs can interact with to induce therapeutic benefits, typically represent the first and most important step of drug discovery. One solution for target discovery is target repositioning, a strategy which relies on the repurposing of known targets for new diseases, leading to new treatments, less side effects and potential drug synergies. Biological networks have emerged as powerful tools for integrating heterogeneous data and facilitating the prediction of biological or therapeutic properties. Consequently, they are widely employed to predict new therapeutic targets by characterizing potential candidates, often based on their interactions within a Protein-Protein Interaction (PPI) network, and their proximity to genes associated with the disease. However, over-reliance on PPI networks and the assumption that potential targets are necessarily near known genes can introduce biases that may limit the effectiveness of these methods. This study addresses these limitations in two ways. First, by exploiting a multi-layer network which incorporates additional information such as gene regulation, metabolite interactions, metabolic pathways, and several disease signatures such as Differentially Expressed Genes, mutated genes, Copy Number Alteration, and structural variants. Second, by extracting relevant features from the network using several approaches including proximity to disease-associated genes, but also unbiased approaches such as propagation-based methods, topological metrics, and module detection algorithms. Using prostate cancer as a case study, the best features were identified and utilized to train machine learning algorithms to predict 5 novel promising therapeutic targets for prostate cancer: IGF2R, C5AR, RAB7, SETD2 and NPBWR1.</p></div>","PeriodicalId":10715,"journal":{"name":"Computational and structural biotechnology journal","volume":"24 ","pages":"Pages 464-475"},"PeriodicalIF":4.4000,"publicationDate":"2024-06-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2001037024002101/pdfft?md5=e8ab07e9322518bddc67353b175cc15e&pid=1-s2.0-S2001037024002101-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Target repositioning using multi-layer networks and machine learning: The case of prostate cancer\",\"authors\":\"Milan Picard , Marie-Pier Scott-Boyer , Antoine Bodein , Mickaël Leclercq , Julien Prunier , Olivier Périn , Arnaud Droit\",\"doi\":\"10.1016/j.csbj.2024.06.012\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>The discovery of novel therapeutic targets, defined as proteins which drugs can interact with to induce therapeutic benefits, typically represent the first and most important step of drug discovery. One solution for target discovery is target repositioning, a strategy which relies on the repurposing of known targets for new diseases, leading to new treatments, less side effects and potential drug synergies. Biological networks have emerged as powerful tools for integrating heterogeneous data and facilitating the prediction of biological or therapeutic properties. Consequently, they are widely employed to predict new therapeutic targets by characterizing potential candidates, often based on their interactions within a Protein-Protein Interaction (PPI) network, and their proximity to genes associated with the disease. However, over-reliance on PPI networks and the assumption that potential targets are necessarily near known genes can introduce biases that may limit the effectiveness of these methods. This study addresses these limitations in two ways. First, by exploiting a multi-layer network which incorporates additional information such as gene regulation, metabolite interactions, metabolic pathways, and several disease signatures such as Differentially Expressed Genes, mutated genes, Copy Number Alteration, and structural variants. Second, by extracting relevant features from the network using several approaches including proximity to disease-associated genes, but also unbiased approaches such as propagation-based methods, topological metrics, and module detection algorithms. Using prostate cancer as a case study, the best features were identified and utilized to train machine learning algorithms to predict 5 novel promising therapeutic targets for prostate cancer: IGF2R, C5AR, RAB7, SETD2 and NPBWR1.</p></div>\",\"PeriodicalId\":10715,\"journal\":{\"name\":\"Computational and structural biotechnology journal\",\"volume\":\"24 \",\"pages\":\"Pages 464-475\"},\"PeriodicalIF\":4.4000,\"publicationDate\":\"2024-06-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2001037024002101/pdfft?md5=e8ab07e9322518bddc67353b175cc15e&pid=1-s2.0-S2001037024002101-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational and structural biotechnology journal\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2001037024002101\",\"RegionNum\":2,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"BIOCHEMISTRY & MOLECULAR BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational and structural biotechnology journal","FirstCategoryId":"99","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2001037024002101","RegionNum":2,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"BIOCHEMISTRY & MOLECULAR BIOLOGY","Score":null,"Total":0}
引用次数: 0
摘要
新型治疗靶点是指药物能与之相互作用从而产生治疗效果的蛋白质,发现这种靶点通常是药物发现的第一步,也是最重要的一步。靶点重新定位是靶点发现的一种解决方案,这种策略依赖于将已知靶点重新用于新的疾病,从而获得新的治疗方法、更少的副作用和潜在的药物协同作用。生物网络已成为整合异构数据和促进生物或治疗特性预测的强大工具。因此,生物网络被广泛应用于预测新的治疗靶点,通过描述潜在候选靶点的特征,通常是基于它们在蛋白质-蛋白质相互作用(PPI)网络中的相互作用,以及它们与疾病相关基因的接近程度。然而,过度依赖 PPI 网络和假设潜在靶点一定靠近已知基因可能会带来偏差,从而限制这些方法的有效性。本研究通过两种方法解决了这些局限性。首先,利用多层网络,将基因调控、代谢物相互作用、代谢途径等额外信息以及差异表达基因、突变基因、拷贝数改变和结构变异等几种疾病特征纳入其中。其次,利用多种方法从网络中提取相关特征,包括与疾病相关基因的接近性,以及基于传播的方法、拓扑指标和模块检测算法等无偏方法。以前列腺癌为例,我们确定了最佳特征,并利用这些特征来训练机器学习算法,以预测前列腺癌的 5 个有前景的新型治疗靶点:IGF2R、C5AR、RAB7、SETD2 和 NPBWR1。
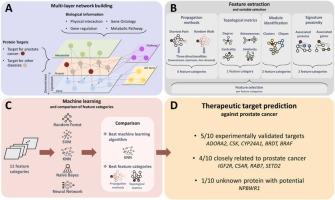
Target repositioning using multi-layer networks and machine learning: The case of prostate cancer
The discovery of novel therapeutic targets, defined as proteins which drugs can interact with to induce therapeutic benefits, typically represent the first and most important step of drug discovery. One solution for target discovery is target repositioning, a strategy which relies on the repurposing of known targets for new diseases, leading to new treatments, less side effects and potential drug synergies. Biological networks have emerged as powerful tools for integrating heterogeneous data and facilitating the prediction of biological or therapeutic properties. Consequently, they are widely employed to predict new therapeutic targets by characterizing potential candidates, often based on their interactions within a Protein-Protein Interaction (PPI) network, and their proximity to genes associated with the disease. However, over-reliance on PPI networks and the assumption that potential targets are necessarily near known genes can introduce biases that may limit the effectiveness of these methods. This study addresses these limitations in two ways. First, by exploiting a multi-layer network which incorporates additional information such as gene regulation, metabolite interactions, metabolic pathways, and several disease signatures such as Differentially Expressed Genes, mutated genes, Copy Number Alteration, and structural variants. Second, by extracting relevant features from the network using several approaches including proximity to disease-associated genes, but also unbiased approaches such as propagation-based methods, topological metrics, and module detection algorithms. Using prostate cancer as a case study, the best features were identified and utilized to train machine learning algorithms to predict 5 novel promising therapeutic targets for prostate cancer: IGF2R, C5AR, RAB7, SETD2 and NPBWR1.
期刊介绍:
Computational and Structural Biotechnology Journal (CSBJ) is an online gold open access journal publishing research articles and reviews after full peer review. All articles are published, without barriers to access, immediately upon acceptance. The journal places a strong emphasis on functional and mechanistic understanding of how molecular components in a biological process work together through the application of computational methods. Structural data may provide such insights, but they are not a pre-requisite for publication in the journal. Specific areas of interest include, but are not limited to:
Structure and function of proteins, nucleic acids and other macromolecules
Structure and function of multi-component complexes
Protein folding, processing and degradation
Enzymology
Computational and structural studies of plant systems
Microbial Informatics
Genomics
Proteomics
Metabolomics
Algorithms and Hypothesis in Bioinformatics
Mathematical and Theoretical Biology
Computational Chemistry and Drug Discovery
Microscopy and Molecular Imaging
Nanotechnology
Systems and Synthetic Biology

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


