Bui Duc Tho , Minh-Tien Nguyen , Dung Tien Le , Lin-Lung Ying , Shumpei Inoue , Tri-Thanh Nguyen
{"title":"利用额外的外部上下文改进生物医学命名实体识别。","authors":"Bui Duc Tho , Minh-Tien Nguyen , Dung Tien Le , Lin-Lung Ying , Shumpei Inoue , Tri-Thanh Nguyen","doi":"10.1016/j.jbi.2024.104674","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective:</h3><p>Biomedical Named Entity Recognition (bio NER) is the task of recognizing named entities in biomedical texts. This paper introduces a new model that addresses bio NER by considering additional external contexts. Different from prior methods that mainly use original input sequences for sequence labeling, the model takes into account additional contexts to enhance the representation of entities in the original sequences, since additional contexts can provide enhanced information for the concept explanation of biomedical entities.</p></div><div><h3>Methods:</h3><p>To exploit an additional context, given an original input sequence, the model first retrieves the relevant sentences from PubMed and then ranks the retrieved sentences to form the contexts. It next combines the context with the original input sequence to form a new enhanced sequence. The original and new enhanced sequences are fed into PubMedBERT for learning feature representation. To obtain more fine-grained features, the model stacks a BiLSTM layer on top of PubMedBERT. The final named entity label prediction is done by using a CRF layer. The model is jointly trained in an end-to-end manner to take advantage of the additional context for NER of the original sequence.</p></div><div><h3>Results:</h3><p>Experimental results on six biomedical datasets show that the proposed model achieves promising performance compared to strong baselines and confirms the contribution of additional contexts for bio NER.</p></div><div><h3>Conclusion:</h3><p>The promising results confirm three important points. First, the additional context from PubMed helps to improve the quality of the recognition of biomedical entities. Second, PubMed is more appropriate than the Google search engine for providing relevant information of bio NER. Finally, more relevant sentences from the context are more beneficial than irrelevant ones to provide enhanced information for the original input sequences. The model is flexible to integrate any additional context types for the NER task.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":"156 ","pages":"Article 104674"},"PeriodicalIF":4.5000,"publicationDate":"2024-06-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Improving biomedical Named Entity Recognition with additional external contexts\",\"authors\":\"Bui Duc Tho , Minh-Tien Nguyen , Dung Tien Le , Lin-Lung Ying , Shumpei Inoue , Tri-Thanh Nguyen\",\"doi\":\"10.1016/j.jbi.2024.104674\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective:</h3><p>Biomedical Named Entity Recognition (bio NER) is the task of recognizing named entities in biomedical texts. This paper introduces a new model that addresses bio NER by considering additional external contexts. Different from prior methods that mainly use original input sequences for sequence labeling, the model takes into account additional contexts to enhance the representation of entities in the original sequences, since additional contexts can provide enhanced information for the concept explanation of biomedical entities.</p></div><div><h3>Methods:</h3><p>To exploit an additional context, given an original input sequence, the model first retrieves the relevant sentences from PubMed and then ranks the retrieved sentences to form the contexts. It next combines the context with the original input sequence to form a new enhanced sequence. The original and new enhanced sequences are fed into PubMedBERT for learning feature representation. To obtain more fine-grained features, the model stacks a BiLSTM layer on top of PubMedBERT. The final named entity label prediction is done by using a CRF layer. The model is jointly trained in an end-to-end manner to take advantage of the additional context for NER of the original sequence.</p></div><div><h3>Results:</h3><p>Experimental results on six biomedical datasets show that the proposed model achieves promising performance compared to strong baselines and confirms the contribution of additional contexts for bio NER.</p></div><div><h3>Conclusion:</h3><p>The promising results confirm three important points. First, the additional context from PubMed helps to improve the quality of the recognition of biomedical entities. Second, PubMed is more appropriate than the Google search engine for providing relevant information of bio NER. Finally, more relevant sentences from the context are more beneficial than irrelevant ones to provide enhanced information for the original input sequences. The model is flexible to integrate any additional context types for the NER task.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":\"156 \",\"pages\":\"Article 104674\"},\"PeriodicalIF\":4.5000,\"publicationDate\":\"2024-06-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000923\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000923","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
目的:生物医学命名实体识别(bio NER)是一项识别生物医学文本中命名实体的任务:生物医学命名实体识别(bio NER)是一项识别生物医学文本中命名实体的任务。本文介绍了一种通过考虑额外外部上下文来解决生物 NER 问题的新模型。与之前主要使用原始输入序列进行序列标注的方法不同,该模型考虑了附加上下文,以增强原始序列中实体的表示,因为附加上下文可为生物医学实体的概念解释提供更多信息:为了利用附加上下文,在给定原始输入序列的情况下,模型首先从 PubMed 中检索相关句子,然后对检索到的句子进行排序以形成上下文。接下来,它将上下文与原始输入序列相结合,形成新的增强序列。原始序列和新的增强序列被输入 PubMedBERT 以学习特征表示。为了获得更精细的特征,该模型在 PubMedBERT 的顶部堆叠了一个 BiLSTM 层。最终的命名实体标签预测由 CRF 层完成。该模型以端到端的方式进行联合训练,以利用额外的上下文对原始序列进行 NER:在六个生物医学数据集上的实验结果表明,与强大的基线相比,所提出的模型取得了可喜的性能,并证实了附加上下文对生物 NER 的贡献:良好的结果证实了三个要点。首先,来自 PubMed 的附加上下文有助于提高生物医学实体的识别质量。其次,PubMed 比 Google 搜索引擎更适合提供生物 NER 的相关信息。最后,上下文中的相关句子比无关句子更有利于为原始输入序列提供增强信息。该模型非常灵活,可以为 NER 任务整合任何其他上下文类型。
Improving biomedical Named Entity Recognition with additional external contexts
Objective:
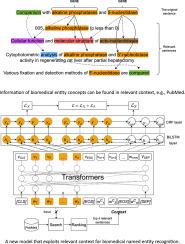
Biomedical Named Entity Recognition (bio NER) is the task of recognizing named entities in biomedical texts. This paper introduces a new model that addresses bio NER by considering additional external contexts. Different from prior methods that mainly use original input sequences for sequence labeling, the model takes into account additional contexts to enhance the representation of entities in the original sequences, since additional contexts can provide enhanced information for the concept explanation of biomedical entities.
Methods:
To exploit an additional context, given an original input sequence, the model first retrieves the relevant sentences from PubMed and then ranks the retrieved sentences to form the contexts. It next combines the context with the original input sequence to form a new enhanced sequence. The original and new enhanced sequences are fed into PubMedBERT for learning feature representation. To obtain more fine-grained features, the model stacks a BiLSTM layer on top of PubMedBERT. The final named entity label prediction is done by using a CRF layer. The model is jointly trained in an end-to-end manner to take advantage of the additional context for NER of the original sequence.
Results:
Experimental results on six biomedical datasets show that the proposed model achieves promising performance compared to strong baselines and confirms the contribution of additional contexts for bio NER.
Conclusion:
The promising results confirm three important points. First, the additional context from PubMed helps to improve the quality of the recognition of biomedical entities. Second, PubMed is more appropriate than the Google search engine for providing relevant information of bio NER. Finally, more relevant sentences from the context are more beneficial than irrelevant ones to provide enhanced information for the original input sequences. The model is flexible to integrate any additional context types for the NER task.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


