Brad Hershowitz , Melinda Hodkiewicz , Tyler Bikaun , Michael Stewart , Wei Liu
{"title":"从长文本维护文档中提取因果知识","authors":"Brad Hershowitz , Melinda Hodkiewicz , Tyler Bikaun , Michael Stewart , Wei Liu","doi":"10.1016/j.compind.2024.104110","DOIUrl":null,"url":null,"abstract":"<div><p>Large numbers of maintenance Work Request Notification (WRN) records are created by industry as part of standard business work flows. These digital records hold invaluable insights crucial to best practice in asset management. Of particular interest are the cause–effect relations in the <em>long text</em> WRN field. In this research we develop a two-stage deep learning pipeline to extract cause-and-effect triples and construct a causal graph database. A novel sentence-level noise removal method in the first stage filters out information extraneous to causal semantics. The second stage leverages a joint entity-and-relation extraction model to extract causal relations. To train the noise removal and causality extraction models we produced an annotated dataset of 1027 WRN records. The results for causality extraction as measured by F1-score are 83% and 92% for the identification of <em>Cause</em> and <em>Effect</em> entities respectively, and 78% for a correct causal relation between these entities. The pipeline is applied to a real-word, industrial plant dataset of 98,000 WRN records to produce a graph database. This work provides a framework for technical personnel to query the causes of equipment failures enabling answers to questions such as “what are the most <em>common</em>, <em>costly</em>, and <em>recent</em> causes of failures at my facility?”.</p></div>","PeriodicalId":55219,"journal":{"name":"Computers in Industry","volume":"161 ","pages":"Article 104110"},"PeriodicalIF":8.2000,"publicationDate":"2024-05-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S0166361524000381/pdfft?md5=96893d090d4ff3f33a64736705fd345b&pid=1-s2.0-S0166361524000381-main.pdf","citationCount":"0","resultStr":"{\"title\":\"Causal knowledge extraction from long text maintenance documents\",\"authors\":\"Brad Hershowitz , Melinda Hodkiewicz , Tyler Bikaun , Michael Stewart , Wei Liu\",\"doi\":\"10.1016/j.compind.2024.104110\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Large numbers of maintenance Work Request Notification (WRN) records are created by industry as part of standard business work flows. These digital records hold invaluable insights crucial to best practice in asset management. Of particular interest are the cause–effect relations in the <em>long text</em> WRN field. In this research we develop a two-stage deep learning pipeline to extract cause-and-effect triples and construct a causal graph database. A novel sentence-level noise removal method in the first stage filters out information extraneous to causal semantics. The second stage leverages a joint entity-and-relation extraction model to extract causal relations. To train the noise removal and causality extraction models we produced an annotated dataset of 1027 WRN records. The results for causality extraction as measured by F1-score are 83% and 92% for the identification of <em>Cause</em> and <em>Effect</em> entities respectively, and 78% for a correct causal relation between these entities. The pipeline is applied to a real-word, industrial plant dataset of 98,000 WRN records to produce a graph database. This work provides a framework for technical personnel to query the causes of equipment failures enabling answers to questions such as “what are the most <em>common</em>, <em>costly</em>, and <em>recent</em> causes of failures at my facility?”.</p></div>\",\"PeriodicalId\":55219,\"journal\":{\"name\":\"Computers in Industry\",\"volume\":\"161 \",\"pages\":\"Article 104110\"},\"PeriodicalIF\":8.2000,\"publicationDate\":\"2024-05-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S0166361524000381/pdfft?md5=96893d090d4ff3f33a64736705fd345b&pid=1-s2.0-S0166361524000381-main.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computers in Industry\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0166361524000381\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computers in Industry","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0166361524000381","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Causal knowledge extraction from long text maintenance documents
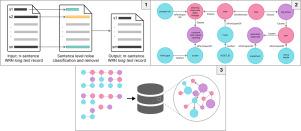
Large numbers of maintenance Work Request Notification (WRN) records are created by industry as part of standard business work flows. These digital records hold invaluable insights crucial to best practice in asset management. Of particular interest are the cause–effect relations in the long text WRN field. In this research we develop a two-stage deep learning pipeline to extract cause-and-effect triples and construct a causal graph database. A novel sentence-level noise removal method in the first stage filters out information extraneous to causal semantics. The second stage leverages a joint entity-and-relation extraction model to extract causal relations. To train the noise removal and causality extraction models we produced an annotated dataset of 1027 WRN records. The results for causality extraction as measured by F1-score are 83% and 92% for the identification of Cause and Effect entities respectively, and 78% for a correct causal relation between these entities. The pipeline is applied to a real-word, industrial plant dataset of 98,000 WRN records to produce a graph database. This work provides a framework for technical personnel to query the causes of equipment failures enabling answers to questions such as “what are the most common, costly, and recent causes of failures at my facility?”.
期刊介绍:
The objective of Computers in Industry is to present original, high-quality, application-oriented research papers that:
• Illuminate emerging trends and possibilities in the utilization of Information and Communication Technology in industry;
• Establish connections or integrations across various technology domains within the expansive realm of computer applications for industry;
• Foster connections or integrations across diverse application areas of ICT in industry.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


