Saba Hameed, Javaria Amin, Muhammad Almas Anjum, Muhammad Sharif
{"title":"利用基于视觉变换器和递归神经网络的时空特征检测可疑活动","authors":"Saba Hameed, Javaria Amin, Muhammad Almas Anjum, Muhammad Sharif","doi":"10.1007/s12652-024-04818-7","DOIUrl":null,"url":null,"abstract":"<p>Nowadays there is growing demand for surveillance applications due to the safety and security from anomalous events. An anomaly in the video is referred to as an event that has some unusual behavior. Although time is required for the recognition of these anomalous events, computerized methods might help to decrease it and perform efficient prediction. However, accurate anomaly detection is still a challenge due to complex background, illumination, variations, and occlusion. To handle these challenges a method is proposed for a vision transformer convolutional recurrent neural network named ViT-CNN-RCNN model for the classification of suspicious activities based on frames and videos. The proposed pre-trained ViT-base-patch16-224-in21k model contains 224 × 224 × 3 video frames as input and converts into a 16 × 16 patch size. The ViT-base-patch16-224-in21k has a patch embedding layer, ViT encoder, and ViT transformer layer having 11 blocks, layer-norm, and ViT pooler. The ViT model is trained on selected learning parameters such as 20 training epochs, and 10 batch-size to categorize the input frames into thirteen different classes such as robbery, fighting, shooting, stealing, shoplifting, Arrest, Arson, Abuse, exploiting, Road Accident, Burglary, and Vandalism. The CNN-RNN sequential model is designed to process sequential data, that contains an input layer, GRU layer, GRU-1 Layer and Dense Layer. This model is trained on optimal hyperparameters such as 32 video frame sizes, 30 training epochs, and 16 batch-size for classification into corresponding class labels. The proposed model is evaluated on UNI-crime and UCF-crime datasets. The experimental outcomes conclude that the proposed approach better performed as compared to recently published works.</p>","PeriodicalId":14959,"journal":{"name":"Journal of Ambient Intelligence and Humanized Computing","volume":"95 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-05-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Suspicious activities detection using spatial–temporal features based on vision transformer and recurrent neural network\",\"authors\":\"Saba Hameed, Javaria Amin, Muhammad Almas Anjum, Muhammad Sharif\",\"doi\":\"10.1007/s12652-024-04818-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Nowadays there is growing demand for surveillance applications due to the safety and security from anomalous events. An anomaly in the video is referred to as an event that has some unusual behavior. Although time is required for the recognition of these anomalous events, computerized methods might help to decrease it and perform efficient prediction. However, accurate anomaly detection is still a challenge due to complex background, illumination, variations, and occlusion. To handle these challenges a method is proposed for a vision transformer convolutional recurrent neural network named ViT-CNN-RCNN model for the classification of suspicious activities based on frames and videos. The proposed pre-trained ViT-base-patch16-224-in21k model contains 224 × 224 × 3 video frames as input and converts into a 16 × 16 patch size. The ViT-base-patch16-224-in21k has a patch embedding layer, ViT encoder, and ViT transformer layer having 11 blocks, layer-norm, and ViT pooler. The ViT model is trained on selected learning parameters such as 20 training epochs, and 10 batch-size to categorize the input frames into thirteen different classes such as robbery, fighting, shooting, stealing, shoplifting, Arrest, Arson, Abuse, exploiting, Road Accident, Burglary, and Vandalism. The CNN-RNN sequential model is designed to process sequential data, that contains an input layer, GRU layer, GRU-1 Layer and Dense Layer. This model is trained on optimal hyperparameters such as 32 video frame sizes, 30 training epochs, and 16 batch-size for classification into corresponding class labels. The proposed model is evaluated on UNI-crime and UCF-crime datasets. The experimental outcomes conclude that the proposed approach better performed as compared to recently published works.</p>\",\"PeriodicalId\":14959,\"journal\":{\"name\":\"Journal of Ambient Intelligence and Humanized Computing\",\"volume\":\"95 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-05-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Ambient Intelligence and Humanized Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s12652-024-04818-7\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Ambient Intelligence and Humanized Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12652-024-04818-7","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
Suspicious activities detection using spatial–temporal features based on vision transformer and recurrent neural network
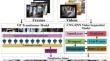
Nowadays there is growing demand for surveillance applications due to the safety and security from anomalous events. An anomaly in the video is referred to as an event that has some unusual behavior. Although time is required for the recognition of these anomalous events, computerized methods might help to decrease it and perform efficient prediction. However, accurate anomaly detection is still a challenge due to complex background, illumination, variations, and occlusion. To handle these challenges a method is proposed for a vision transformer convolutional recurrent neural network named ViT-CNN-RCNN model for the classification of suspicious activities based on frames and videos. The proposed pre-trained ViT-base-patch16-224-in21k model contains 224 × 224 × 3 video frames as input and converts into a 16 × 16 patch size. The ViT-base-patch16-224-in21k has a patch embedding layer, ViT encoder, and ViT transformer layer having 11 blocks, layer-norm, and ViT pooler. The ViT model is trained on selected learning parameters such as 20 training epochs, and 10 batch-size to categorize the input frames into thirteen different classes such as robbery, fighting, shooting, stealing, shoplifting, Arrest, Arson, Abuse, exploiting, Road Accident, Burglary, and Vandalism. The CNN-RNN sequential model is designed to process sequential data, that contains an input layer, GRU layer, GRU-1 Layer and Dense Layer. This model is trained on optimal hyperparameters such as 32 video frame sizes, 30 training epochs, and 16 batch-size for classification into corresponding class labels. The proposed model is evaluated on UNI-crime and UCF-crime datasets. The experimental outcomes conclude that the proposed approach better performed as compared to recently published works.
期刊介绍:
The purpose of JAIHC is to provide a high profile, leading edge forum for academics, industrial professionals, educators and policy makers involved in the field to contribute, to disseminate the most innovative researches and developments of all aspects of ambient intelligence and humanized computing, such as intelligent/smart objects, environments/spaces, and systems. The journal discusses various technical, safety, personal, social, physical, political, artistic and economic issues. The research topics covered by the journal are (but not limited to):
Pervasive/Ubiquitous Computing and Applications
Cognitive wireless sensor network
Embedded Systems and Software
Mobile Computing and Wireless Communications
Next Generation Multimedia Systems
Security, Privacy and Trust
Service and Semantic Computing
Advanced Networking Architectures
Dependable, Reliable and Autonomic Computing
Embedded Smart Agents
Context awareness, social sensing and inference
Multi modal interaction design
Ergonomics and product prototyping
Intelligent and self-organizing transportation networks & services
Healthcare Systems
Virtual Humans & Virtual Worlds
Wearables sensors and actuators

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


