{"title":"LMFormer:用于人体姿态估计的轻量级多特征透视变换器","authors":"Biao Li , Shoufeng Tang , Wenyi Li","doi":"10.1016/j.neucom.2024.127884","DOIUrl":null,"url":null,"abstract":"<div><p>The effectiveness of Token Mixer in visual tasks is well-established; however, its high computational complexity and a relatively singular spatial relationship modeling perspective present challenges. In this study, we propose LMFormer, a hybrid model based on CNN and Transformer architectures for human pose estimation. To achieve this, we first design a lightweight multi-feature perspective Token Mixer, using a lightweight feature reconstruction strategy to simultaneously aggregate the spatial and channel feature information, thereby enhancing the performance and generalization capabilities of the model. Subsequently, we explore multi-scale information interaction by developing an iterative multi-feature weighting module, coupled with the design of a multi-scale information propagation mechanism incorporated into the skip connections. Finally, we validate the effectiveness of the network on benchmark datasets, including COCO, MPII, and CrowdPose, utilizing a multi-scale deep supervision strategy. Extensive experiments demonstrate that LMFormer, with reduced computational complexity, comprehensively captures multi-scale features, resulting in significant performance improvements. Specifically, LMFormer-B achieves an AP score of 65.8 on the COCO val dataset, surpassing MobileNetV2 and ShuffleNetV2 by 1.0 and 5.6 points, respectively. Moreover, its parameters are merely 19.8% and 25% of MobileNetV2 and ShuffleNetV2, with corresponding GFLOPs at 43.8% and 50%. We aim to provide new insights into lightweight and efficient feature extraction strategies, as well as efficient Token Mixer designs.</p></div>","PeriodicalId":19268,"journal":{"name":"Neurocomputing","volume":"594 ","pages":"Article 127884"},"PeriodicalIF":5.5000,"publicationDate":"2024-05-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"LMFormer: Lightweight and multi-feature perspective via transformer for human pose estimation\",\"authors\":\"Biao Li , Shoufeng Tang , Wenyi Li\",\"doi\":\"10.1016/j.neucom.2024.127884\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>The effectiveness of Token Mixer in visual tasks is well-established; however, its high computational complexity and a relatively singular spatial relationship modeling perspective present challenges. In this study, we propose LMFormer, a hybrid model based on CNN and Transformer architectures for human pose estimation. To achieve this, we first design a lightweight multi-feature perspective Token Mixer, using a lightweight feature reconstruction strategy to simultaneously aggregate the spatial and channel feature information, thereby enhancing the performance and generalization capabilities of the model. Subsequently, we explore multi-scale information interaction by developing an iterative multi-feature weighting module, coupled with the design of a multi-scale information propagation mechanism incorporated into the skip connections. Finally, we validate the effectiveness of the network on benchmark datasets, including COCO, MPII, and CrowdPose, utilizing a multi-scale deep supervision strategy. Extensive experiments demonstrate that LMFormer, with reduced computational complexity, comprehensively captures multi-scale features, resulting in significant performance improvements. Specifically, LMFormer-B achieves an AP score of 65.8 on the COCO val dataset, surpassing MobileNetV2 and ShuffleNetV2 by 1.0 and 5.6 points, respectively. Moreover, its parameters are merely 19.8% and 25% of MobileNetV2 and ShuffleNetV2, with corresponding GFLOPs at 43.8% and 50%. We aim to provide new insights into lightweight and efficient feature extraction strategies, as well as efficient Token Mixer designs.</p></div>\",\"PeriodicalId\":19268,\"journal\":{\"name\":\"Neurocomputing\",\"volume\":\"594 \",\"pages\":\"Article 127884\"},\"PeriodicalIF\":5.5000,\"publicationDate\":\"2024-05-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Neurocomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S0925231224006556\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Neurocomputing","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S0925231224006556","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
LMFormer: Lightweight and multi-feature perspective via transformer for human pose estimation
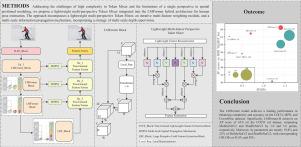
The effectiveness of Token Mixer in visual tasks is well-established; however, its high computational complexity and a relatively singular spatial relationship modeling perspective present challenges. In this study, we propose LMFormer, a hybrid model based on CNN and Transformer architectures for human pose estimation. To achieve this, we first design a lightweight multi-feature perspective Token Mixer, using a lightweight feature reconstruction strategy to simultaneously aggregate the spatial and channel feature information, thereby enhancing the performance and generalization capabilities of the model. Subsequently, we explore multi-scale information interaction by developing an iterative multi-feature weighting module, coupled with the design of a multi-scale information propagation mechanism incorporated into the skip connections. Finally, we validate the effectiveness of the network on benchmark datasets, including COCO, MPII, and CrowdPose, utilizing a multi-scale deep supervision strategy. Extensive experiments demonstrate that LMFormer, with reduced computational complexity, comprehensively captures multi-scale features, resulting in significant performance improvements. Specifically, LMFormer-B achieves an AP score of 65.8 on the COCO val dataset, surpassing MobileNetV2 and ShuffleNetV2 by 1.0 and 5.6 points, respectively. Moreover, its parameters are merely 19.8% and 25% of MobileNetV2 and ShuffleNetV2, with corresponding GFLOPs at 43.8% and 50%. We aim to provide new insights into lightweight and efficient feature extraction strategies, as well as efficient Token Mixer designs.
期刊介绍:
Neurocomputing publishes articles describing recent fundamental contributions in the field of neurocomputing. Neurocomputing theory, practice and applications are the essential topics being covered.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


