Siddhesh Mehta, Rushikesh Karwa, Rahul Chavan, Vaibhav Khatavkar, Amit Joshi
{"title":"利用基于图的统计方法和 NLP 模式提取关键词","authors":"Siddhesh Mehta, Rushikesh Karwa, Rahul Chavan, Vaibhav Khatavkar, Amit Joshi","doi":"10.1007/s12046-024-02494-z","DOIUrl":null,"url":null,"abstract":"<p>Extracting keyphrases plays a vital role in the field of natural language processing, that focuses on recognizing and retrieving significant phrases that summarize the essential information in a document. This research paper introduces a novel approach to extract keyphrases using a statistical approach based on graphs that incorporates degree centrality, TextRank, closeness, and betweenness measures and natural language processing patterns. This approach involves constructing a graph representation of the document and identifying the most important nodes in the graph and leveraging natural language processing patterns to enhance the accuracy and relevance of the extracted keyphrases. The proposed model is examined on a standard dataset for performance evaluation and its outcomes are evaluated by comparing them with the state-of-art methods for extracting keyphrases. The precision, recall, and F-measure achieved by the proposed model are 0.5263, 0.5498, and 0.5323, respectively which shows that proposed model outperforms existing models. The principal novelty of this methodology resides in the utilization of statistical techniques based on graphs and patterns of natural language processing, which enable the detection of the most pertinent nodes and keyphrases of utmost significance. The proposed approach is generalizable to a wide range of domains and text types, making it a promising approach for keyphrase extraction in various applications, including content analysis, document classification, and search engine optimization. In conclusion, the proposed approach offers a robust and scalable solution for identifying keyphrases that capture the essential information of a document. Future research can build upon this approach to improve the efficiency and effectiveness of automated text analysis.</p>","PeriodicalId":21498,"journal":{"name":"Sādhanā","volume":"31 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-05-05","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Keyphrase extraction using graph-based statistical approach with NLP patterns\",\"authors\":\"Siddhesh Mehta, Rushikesh Karwa, Rahul Chavan, Vaibhav Khatavkar, Amit Joshi\",\"doi\":\"10.1007/s12046-024-02494-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Extracting keyphrases plays a vital role in the field of natural language processing, that focuses on recognizing and retrieving significant phrases that summarize the essential information in a document. This research paper introduces a novel approach to extract keyphrases using a statistical approach based on graphs that incorporates degree centrality, TextRank, closeness, and betweenness measures and natural language processing patterns. This approach involves constructing a graph representation of the document and identifying the most important nodes in the graph and leveraging natural language processing patterns to enhance the accuracy and relevance of the extracted keyphrases. The proposed model is examined on a standard dataset for performance evaluation and its outcomes are evaluated by comparing them with the state-of-art methods for extracting keyphrases. The precision, recall, and F-measure achieved by the proposed model are 0.5263, 0.5498, and 0.5323, respectively which shows that proposed model outperforms existing models. The principal novelty of this methodology resides in the utilization of statistical techniques based on graphs and patterns of natural language processing, which enable the detection of the most pertinent nodes and keyphrases of utmost significance. The proposed approach is generalizable to a wide range of domains and text types, making it a promising approach for keyphrase extraction in various applications, including content analysis, document classification, and search engine optimization. In conclusion, the proposed approach offers a robust and scalable solution for identifying keyphrases that capture the essential information of a document. Future research can build upon this approach to improve the efficiency and effectiveness of automated text analysis.</p>\",\"PeriodicalId\":21498,\"journal\":{\"name\":\"Sādhanā\",\"volume\":\"31 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-05-05\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Sādhanā\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s12046-024-02494-z\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Sādhanā","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s12046-024-02494-z","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
提取关键短语在自然语言处理领域发挥着至关重要的作用,其重点是识别和检索概括文档基本信息的重要短语。本研究论文介绍了一种提取关键短语的新方法,该方法采用基于图的统计方法,结合了度中心性、TextRank、接近度和间隔度量以及自然语言处理模式。这种方法包括构建文档的图表示法,识别图中最重要的节点,并利用自然语言处理模式来提高提取关键词的准确性和相关性。我们在标准数据集上对所提出的模型进行了性能评估,并将其结果与最先进的关键词提取方法进行了比较。拟议模型的精确度、召回率和 F 测量值分别为 0.5263、0.5498 和 0.5323,这表明拟议模型优于现有模型。该方法的主要创新点在于利用了基于自然语言处理图和模式的统计技术,从而能够检测出最相关的节点和最重要的关键词。所提出的方法适用于广泛的领域和文本类型,使其成为内容分析、文档分类和搜索引擎优化等各种应用中提取关键词的有效方法。总之,所提出的方法提供了一种稳健且可扩展的解决方案,可用于识别捕捉文档基本信息的关键词。未来的研究可以在此方法的基础上提高自动文本分析的效率和效果。
Keyphrase extraction using graph-based statistical approach with NLP patterns
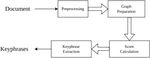
Extracting keyphrases plays a vital role in the field of natural language processing, that focuses on recognizing and retrieving significant phrases that summarize the essential information in a document. This research paper introduces a novel approach to extract keyphrases using a statistical approach based on graphs that incorporates degree centrality, TextRank, closeness, and betweenness measures and natural language processing patterns. This approach involves constructing a graph representation of the document and identifying the most important nodes in the graph and leveraging natural language processing patterns to enhance the accuracy and relevance of the extracted keyphrases. The proposed model is examined on a standard dataset for performance evaluation and its outcomes are evaluated by comparing them with the state-of-art methods for extracting keyphrases. The precision, recall, and F-measure achieved by the proposed model are 0.5263, 0.5498, and 0.5323, respectively which shows that proposed model outperforms existing models. The principal novelty of this methodology resides in the utilization of statistical techniques based on graphs and patterns of natural language processing, which enable the detection of the most pertinent nodes and keyphrases of utmost significance. The proposed approach is generalizable to a wide range of domains and text types, making it a promising approach for keyphrase extraction in various applications, including content analysis, document classification, and search engine optimization. In conclusion, the proposed approach offers a robust and scalable solution for identifying keyphrases that capture the essential information of a document. Future research can build upon this approach to improve the efficiency and effectiveness of automated text analysis.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


