{"title":"在合成伪语言中安全预训练深度语言模型","authors":"T. E. Gorbacheva, I. Y. Bondarenko","doi":"10.1134/S1064562423701636","DOIUrl":null,"url":null,"abstract":"<p>This paper compares the pretraining of a transformer on natural language texts and on sentences of a synthetic pseudo-language. The artificial texts are automatically generated according to the rules written in a context-free grammar. The results of fine-tuning to complete tasks of the RussianSuperGLUE project statistically reliably showed that the models had the same scores. That is, the use of artificial texts facilitates the AI safety, because it can completely control the composition of the dataset. In addition, at the pretraining stage of a RoBERTa-like model, it is enough to learn recognizing only the syntactic and morphological patterns of the language, which can be successfully created in a fairly simple way, such as a context-free grammar.</p>","PeriodicalId":531,"journal":{"name":"Doklady Mathematics","volume":"108 2 supplement","pages":"S494 - S502"},"PeriodicalIF":0.6000,"publicationDate":"2024-03-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Safe Pretraining of Deep Language Models in a Synthetic Pseudo-Language\",\"authors\":\"T. E. Gorbacheva, I. Y. Bondarenko\",\"doi\":\"10.1134/S1064562423701636\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This paper compares the pretraining of a transformer on natural language texts and on sentences of a synthetic pseudo-language. The artificial texts are automatically generated according to the rules written in a context-free grammar. The results of fine-tuning to complete tasks of the RussianSuperGLUE project statistically reliably showed that the models had the same scores. That is, the use of artificial texts facilitates the AI safety, because it can completely control the composition of the dataset. In addition, at the pretraining stage of a RoBERTa-like model, it is enough to learn recognizing only the syntactic and morphological patterns of the language, which can be successfully created in a fairly simple way, such as a context-free grammar.</p>\",\"PeriodicalId\":531,\"journal\":{\"name\":\"Doklady Mathematics\",\"volume\":\"108 2 supplement\",\"pages\":\"S494 - S502\"},\"PeriodicalIF\":0.6000,\"publicationDate\":\"2024-03-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Doklady Mathematics\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://link.springer.com/article/10.1134/S1064562423701636\",\"RegionNum\":4,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Doklady Mathematics","FirstCategoryId":"100","ListUrlMain":"https://link.springer.com/article/10.1134/S1064562423701636","RegionNum":4,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICS","Score":null,"Total":0}
引用次数: 0
摘要
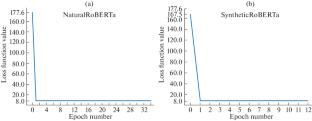
摘要 本文比较了转换器对自然语言文本和合成伪语言句子的预训练。人工文本是根据无上下文语法规则自动生成的。为完成 RussianSuperGLUE 项目的任务而进行的微调结果可靠地表明,两种模型的得分相同。也就是说,人工文本的使用有利于人工智能的安全性,因为它可以完全控制数据集的组成。此外,在类 RoBERTa 模型的预训练阶段,只需学习识别语言的句法和形态模式即可,这可以通过相当简单的方法(如无上下文语法)成功创建。
Safe Pretraining of Deep Language Models in a Synthetic Pseudo-Language
This paper compares the pretraining of a transformer on natural language texts and on sentences of a synthetic pseudo-language. The artificial texts are automatically generated according to the rules written in a context-free grammar. The results of fine-tuning to complete tasks of the RussianSuperGLUE project statistically reliably showed that the models had the same scores. That is, the use of artificial texts facilitates the AI safety, because it can completely control the composition of the dataset. In addition, at the pretraining stage of a RoBERTa-like model, it is enough to learn recognizing only the syntactic and morphological patterns of the language, which can be successfully created in a fairly simple way, such as a context-free grammar.
期刊介绍:
Doklady Mathematics is a journal of the Presidium of the Russian Academy of Sciences. It contains English translations of papers published in Doklady Akademii Nauk (Proceedings of the Russian Academy of Sciences), which was founded in 1933 and is published 36 times a year. Doklady Mathematics includes the materials from the following areas: mathematics, mathematical physics, computer science, control theory, and computers. It publishes brief scientific reports on previously unpublished significant new research in mathematics and its applications. The main contributors to the journal are Members of the RAS, Corresponding Members of the RAS, and scientists from the former Soviet Union and other foreign countries. Among the contributors are the outstanding Russian mathematicians.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


