{"title":"对大型语言模型进行 Xai 驱动的知识提炼,以便在低资源设备上高效部署","authors":"Riccardo Cantini, Alessio Orsino, Domenico Talia","doi":"10.1186/s40537-024-00928-3","DOIUrl":null,"url":null,"abstract":"<p>Large Language Models (LLMs) are characterized by their inherent memory inefficiency and compute-intensive nature, making them impractical to run on low-resource devices and hindering their applicability in edge AI contexts. To address this issue, Knowledge Distillation approaches have been adopted to transfer knowledge from a complex model, referred to as the teacher, to a more compact, computationally efficient one, known as the student. The aim is to retain the performance of the original model while substantially reducing computational requirements. However, traditional knowledge distillation methods may struggle to effectively transfer crucial explainable knowledge from an LLM teacher to the student, potentially leading to explanation inconsistencies and decreased performance. This paper presents <i>DiXtill</i>, a method based on a novel approach to distilling knowledge from LLMs into lightweight neural architectures. The main idea is to leverage local explanations provided by an eXplainable Artificial Intelligence (XAI) method to guide the cross-architecture distillation of a teacher LLM into a self-explainable student, specifically a bi-directional LSTM network.Experimental results show that our XAI-driven distillation method allows the teacher explanations to be effectively transferred to the student, resulting in better agreement compared to classical distillation methods,thus enhancing the student interpretability. Furthermore, it enables the student to achieve comparable performance to the teacher LLM while also delivering a significantly higher compression ratio and speedup compared to other techniques such as post-training quantization and pruning, which paves the way for more efficient and sustainable edge AI applications</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"18 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-05-04","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Xai-driven knowledge distillation of large language models for efficient deployment on low-resource devices\",\"authors\":\"Riccardo Cantini, Alessio Orsino, Domenico Talia\",\"doi\":\"10.1186/s40537-024-00928-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Large Language Models (LLMs) are characterized by their inherent memory inefficiency and compute-intensive nature, making them impractical to run on low-resource devices and hindering their applicability in edge AI contexts. To address this issue, Knowledge Distillation approaches have been adopted to transfer knowledge from a complex model, referred to as the teacher, to a more compact, computationally efficient one, known as the student. The aim is to retain the performance of the original model while substantially reducing computational requirements. However, traditional knowledge distillation methods may struggle to effectively transfer crucial explainable knowledge from an LLM teacher to the student, potentially leading to explanation inconsistencies and decreased performance. This paper presents <i>DiXtill</i>, a method based on a novel approach to distilling knowledge from LLMs into lightweight neural architectures. The main idea is to leverage local explanations provided by an eXplainable Artificial Intelligence (XAI) method to guide the cross-architecture distillation of a teacher LLM into a self-explainable student, specifically a bi-directional LSTM network.Experimental results show that our XAI-driven distillation method allows the teacher explanations to be effectively transferred to the student, resulting in better agreement compared to classical distillation methods,thus enhancing the student interpretability. Furthermore, it enables the student to achieve comparable performance to the teacher LLM while also delivering a significantly higher compression ratio and speedup compared to other techniques such as post-training quantization and pruning, which paves the way for more efficient and sustainable edge AI applications</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"18 1\",\"pages\":\"\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-05-04\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-024-00928-3\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00928-3","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Xai-driven knowledge distillation of large language models for efficient deployment on low-resource devices
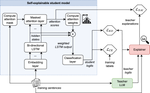
Large Language Models (LLMs) are characterized by their inherent memory inefficiency and compute-intensive nature, making them impractical to run on low-resource devices and hindering their applicability in edge AI contexts. To address this issue, Knowledge Distillation approaches have been adopted to transfer knowledge from a complex model, referred to as the teacher, to a more compact, computationally efficient one, known as the student. The aim is to retain the performance of the original model while substantially reducing computational requirements. However, traditional knowledge distillation methods may struggle to effectively transfer crucial explainable knowledge from an LLM teacher to the student, potentially leading to explanation inconsistencies and decreased performance. This paper presents DiXtill, a method based on a novel approach to distilling knowledge from LLMs into lightweight neural architectures. The main idea is to leverage local explanations provided by an eXplainable Artificial Intelligence (XAI) method to guide the cross-architecture distillation of a teacher LLM into a self-explainable student, specifically a bi-directional LSTM network.Experimental results show that our XAI-driven distillation method allows the teacher explanations to be effectively transferred to the student, resulting in better agreement compared to classical distillation methods,thus enhancing the student interpretability. Furthermore, it enables the student to achieve comparable performance to the teacher LLM while also delivering a significantly higher compression ratio and speedup compared to other techniques such as post-training quantization and pruning, which paves the way for more efficient and sustainable edge AI applications
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


