{"title":"概率 SAX:认知物联网传感器网络时间序列分类的认知启发方法","authors":"Vidyapati Jha, Priyanka Tripathi","doi":"10.1007/s11036-024-02322-y","DOIUrl":null,"url":null,"abstract":"<p>Cognitive Internet of Things (CIoT) is a new subfield of the Internet of Things (IoT) that aims to integrate cognition into the IoT's architecture and design. Various CIoT applications require techniques to inevitably extract machine-understandable concepts from unprocessed sensory data to provide value-added insights about CIoT devices and their users. The time series classification, which is used for the concept's extraction poses challenges to many applications across various domains, i.e., dimensionality reduction strategies have been suggested as an effective method to decrease the dimensionality of time series. The most common approach for time-series classification is the symbolic aggregate approximation (SAX). However, its main drawback is that it does not select the most significant point from the segment during the piecewise aggregate approximation (PAA) stage. The situation is cumbersome when data is heterogeneous and massive. Therefore, this research presents a novel technique for the selection of the most significant point from a segment during the PAA stage in SAX. The proposed technique chooses the maximum informative point as the most significant point using the probabilistic interpretation of sensory data with an appropriate copula design. The appropriate copula is selected using the minimum akaike information criteria (AIC) value. Subsequently, the modified SAX considers the maximum informative points instead of a selection of mean/max/extreme data points on a given segment during the PAA stage. The experimental evaluation of the environmental dataset reveals that the proposed method is more accurate and computationally efficient than classic SAX. Also, for cross-validation it computes the entropy of the information point (<i>i</i>-value) from each dataset to verify the successful transformation of normal data points to information points.</p>","PeriodicalId":501103,"journal":{"name":"Mobile Networks and Applications","volume":"15 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-05-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Probabilistic SAX: A Cognitively-Inspired Method for Time Series Classification in Cognitive IoT Sensor Network\",\"authors\":\"Vidyapati Jha, Priyanka Tripathi\",\"doi\":\"10.1007/s11036-024-02322-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Cognitive Internet of Things (CIoT) is a new subfield of the Internet of Things (IoT) that aims to integrate cognition into the IoT's architecture and design. Various CIoT applications require techniques to inevitably extract machine-understandable concepts from unprocessed sensory data to provide value-added insights about CIoT devices and their users. The time series classification, which is used for the concept's extraction poses challenges to many applications across various domains, i.e., dimensionality reduction strategies have been suggested as an effective method to decrease the dimensionality of time series. The most common approach for time-series classification is the symbolic aggregate approximation (SAX). However, its main drawback is that it does not select the most significant point from the segment during the piecewise aggregate approximation (PAA) stage. The situation is cumbersome when data is heterogeneous and massive. Therefore, this research presents a novel technique for the selection of the most significant point from a segment during the PAA stage in SAX. The proposed technique chooses the maximum informative point as the most significant point using the probabilistic interpretation of sensory data with an appropriate copula design. The appropriate copula is selected using the minimum akaike information criteria (AIC) value. Subsequently, the modified SAX considers the maximum informative points instead of a selection of mean/max/extreme data points on a given segment during the PAA stage. The experimental evaluation of the environmental dataset reveals that the proposed method is more accurate and computationally efficient than classic SAX. Also, for cross-validation it computes the entropy of the information point (<i>i</i>-value) from each dataset to verify the successful transformation of normal data points to information points.</p>\",\"PeriodicalId\":501103,\"journal\":{\"name\":\"Mobile Networks and Applications\",\"volume\":\"15 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-05-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Mobile Networks and Applications\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s11036-024-02322-y\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Mobile Networks and Applications","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s11036-024-02322-y","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Probabilistic SAX: A Cognitively-Inspired Method for Time Series Classification in Cognitive IoT Sensor Network
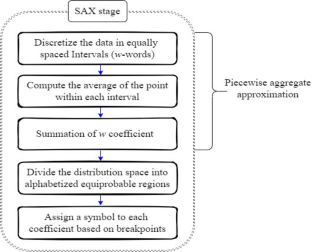
Cognitive Internet of Things (CIoT) is a new subfield of the Internet of Things (IoT) that aims to integrate cognition into the IoT's architecture and design. Various CIoT applications require techniques to inevitably extract machine-understandable concepts from unprocessed sensory data to provide value-added insights about CIoT devices and their users. The time series classification, which is used for the concept's extraction poses challenges to many applications across various domains, i.e., dimensionality reduction strategies have been suggested as an effective method to decrease the dimensionality of time series. The most common approach for time-series classification is the symbolic aggregate approximation (SAX). However, its main drawback is that it does not select the most significant point from the segment during the piecewise aggregate approximation (PAA) stage. The situation is cumbersome when data is heterogeneous and massive. Therefore, this research presents a novel technique for the selection of the most significant point from a segment during the PAA stage in SAX. The proposed technique chooses the maximum informative point as the most significant point using the probabilistic interpretation of sensory data with an appropriate copula design. The appropriate copula is selected using the minimum akaike information criteria (AIC) value. Subsequently, the modified SAX considers the maximum informative points instead of a selection of mean/max/extreme data points on a given segment during the PAA stage. The experimental evaluation of the environmental dataset reveals that the proposed method is more accurate and computationally efficient than classic SAX. Also, for cross-validation it computes the entropy of the information point (i-value) from each dataset to verify the successful transformation of normal data points to information points.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


