最大扩散强化学习
IF 23.9
1区 计算机科学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
机器人和动物都通过自己的身体和感官来体验世界。它们的身体限制了它们的体验,确保它们在空间和时间上持续展开。因此,具身代理的体验在本质上是相关的。相关性给机器学习带来了根本性的挑战,因为大多数技术都依赖于数据独立且分布相同的假设。在强化学习中,数据是直接从代理的连续经验中收集的,违反这一假设往往是不可避免的。在这里,我们通过利用遍历过程的统计力学,推导出一种克服这一问题的方法,我们称之为最大扩散强化学习。通过对代理经验进行去相关化处理,我们的方法可以在单个任务尝试过程中的连续部署中实现单次学习。此外,我们还证明了我们的方法可以推广众所周知的最大熵技术,并在流行的基准测试中稳健地超越了最先进的性能。我们在物理学、学习和控制领域的研究成果为强化学习代理的透明、可靠决策奠定了基础。本文章由计算机程序翻译,如有差异,请以英文原文为准。
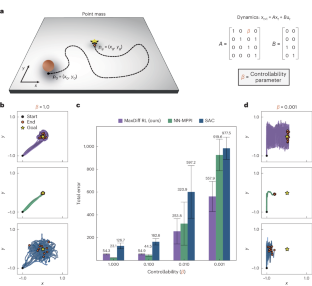

Maximum diffusion reinforcement learning
Robots and animals both experience the world through their bodies and senses. Their embodiment constrains their experiences, ensuring that they unfold continuously in space and time. As a result, the experiences of embodied agents are intrinsically correlated. Correlations create fundamental challenges for machine learning, as most techniques rely on the assumption that data are independent and identically distributed. In reinforcement learning, where data are directly collected from an agent’s sequential experiences, violations of this assumption are often unavoidable. Here we derive a method that overcomes this issue by exploiting the statistical mechanics of ergodic processes, which we term maximum diffusion reinforcement learning. By decorrelating agent experiences, our approach provably enables single-shot learning in continuous deployments over the course of individual task attempts. Moreover, we prove our approach generalizes well-known maximum entropy techniques and robustly exceeds state-of-the-art performance across popular benchmarks. Our results at the nexus of physics, learning and control form a foundation for transparent and reliable decision-making in embodied reinforcement learning agents. The central assumption in machine learning that data are independent and identically distributed does not hold in many reinforcement learning settings, as experiences of reinforcement learning agents are sequential and intrinsically correlated in time. Berrueta and colleagues use the mathematical theory of ergodic processes to develop a reinforcement framework that can decorrelate agent experiences and is capable of learning in single-shot deployments.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Nature Machine Intelligence
Multiple-
CiteScore
36.90
自引率
2.10%
发文量
127
期刊介绍:
Nature Machine Intelligence is a distinguished publication that presents original research and reviews on various topics in machine learning, robotics, and AI. Our focus extends beyond these fields, exploring their profound impact on other scientific disciplines, as well as societal and industrial aspects. We recognize limitless possibilities wherein machine intelligence can augment human capabilities and knowledge in domains like scientific exploration, healthcare, medical diagnostics, and the creation of safe and sustainable cities, transportation, and agriculture. Simultaneously, we acknowledge the emergence of ethical, social, and legal concerns due to the rapid pace of advancements.
To foster interdisciplinary discussions on these far-reaching implications, Nature Machine Intelligence serves as a platform for dialogue facilitated through Comments, News Features, News & Views articles, and Correspondence. Our goal is to encourage a comprehensive examination of these subjects.
Similar to all Nature-branded journals, Nature Machine Intelligence operates under the guidance of a team of skilled editors. We adhere to a fair and rigorous peer-review process, ensuring high standards of copy-editing and production, swift publication, and editorial independence.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


