Hussien Ali El-Sayed Ali, M. H. Alham, Doaa Khalil Ibrahim
{"title":"使用 Apache Spark 解决智能电网中负荷预测和需求响应的大数据问题:伦敦低碳项目案例研究","authors":"Hussien Ali El-Sayed Ali, M. H. Alham, Doaa Khalil Ibrahim","doi":"10.1186/s40537-024-00909-6","DOIUrl":null,"url":null,"abstract":"<p>Using recent information and communication technologies for monitoring and management initiates a revolution in the smart grid. These technologies generate massive data that can only be processed using big data tools. This paper emphasizes the role of big data in resolving load forecasting, renewable energy sources integration, and demand response as significant aspects of smart grids. Meters data from the Low Carbon London Project is investigated as a case study. Because of the immense stream of meters' readings and exogenous data added to load forecasting models, addressing the problem is in the context of big data. Descriptive analytics are developed using Spark SQL to get insights regarding household energy consumption. Spark MLlib is utilized for predictive analytics by building scalable machine learning models accommodating meters' data streams. Multivariate polynomial regression and decision tree models are preferred here based on the big data point of view and the literature that ensures they are accurate and interpretable. The results confirmed the descriptive analytics and data visualization capabilities to provide valuable insights, guide the feature selection process, and enhance load forecasting models' accuracy. Accordingly, proper evaluation of demand response programs and integration of renewable energy resources is accomplished using achieved load forecasting results.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"37 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-04-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Big data resolving using Apache Spark for load forecasting and demand response in smart grid: a case study of Low Carbon London Project\",\"authors\":\"Hussien Ali El-Sayed Ali, M. H. Alham, Doaa Khalil Ibrahim\",\"doi\":\"10.1186/s40537-024-00909-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Using recent information and communication technologies for monitoring and management initiates a revolution in the smart grid. These technologies generate massive data that can only be processed using big data tools. This paper emphasizes the role of big data in resolving load forecasting, renewable energy sources integration, and demand response as significant aspects of smart grids. Meters data from the Low Carbon London Project is investigated as a case study. Because of the immense stream of meters' readings and exogenous data added to load forecasting models, addressing the problem is in the context of big data. Descriptive analytics are developed using Spark SQL to get insights regarding household energy consumption. Spark MLlib is utilized for predictive analytics by building scalable machine learning models accommodating meters' data streams. Multivariate polynomial regression and decision tree models are preferred here based on the big data point of view and the literature that ensures they are accurate and interpretable. The results confirmed the descriptive analytics and data visualization capabilities to provide valuable insights, guide the feature selection process, and enhance load forecasting models' accuracy. Accordingly, proper evaluation of demand response programs and integration of renewable energy resources is accomplished using achieved load forecasting results.</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"37 1\",\"pages\":\"\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-04-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-024-00909-6\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00909-6","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Big data resolving using Apache Spark for load forecasting and demand response in smart grid: a case study of Low Carbon London Project
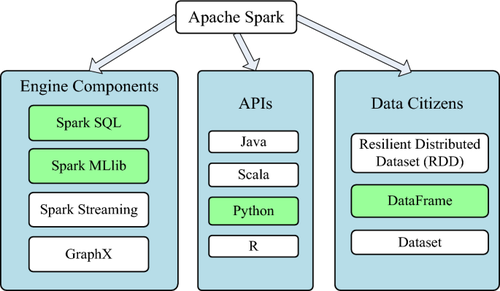
Using recent information and communication technologies for monitoring and management initiates a revolution in the smart grid. These technologies generate massive data that can only be processed using big data tools. This paper emphasizes the role of big data in resolving load forecasting, renewable energy sources integration, and demand response as significant aspects of smart grids. Meters data from the Low Carbon London Project is investigated as a case study. Because of the immense stream of meters' readings and exogenous data added to load forecasting models, addressing the problem is in the context of big data. Descriptive analytics are developed using Spark SQL to get insights regarding household energy consumption. Spark MLlib is utilized for predictive analytics by building scalable machine learning models accommodating meters' data streams. Multivariate polynomial regression and decision tree models are preferred here based on the big data point of view and the literature that ensures they are accurate and interpretable. The results confirmed the descriptive analytics and data visualization capabilities to provide valuable insights, guide the feature selection process, and enhance load forecasting models' accuracy. Accordingly, proper evaluation of demand response programs and integration of renewable energy resources is accomplished using achieved load forecasting results.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


