Fangjun Wang , Xurong Chi , Liangwu Wei , Yanzhi Song , Zhouwang Yang
{"title":"使用混合策略自训练连体网络进行多位置工业缺陷检测","authors":"Fangjun Wang , Xurong Chi , Liangwu Wei , Yanzhi Song , Zhouwang Yang","doi":"10.1016/j.jii.2024.100615","DOIUrl":null,"url":null,"abstract":"<div><p>Structural defects account for a large proportion of defects, and acquiring large batches of high-quality labels is labor-intensive and time-consuming for industrial visual defect inspection tasks. This paper addresses the above problem by exploiting sufficient unlabeled samples, and aims to achieve superior model performance with some labeled data by using self-training methods that incorporate positional information. Specifically, this paper proposes a novel self-training architecture, MixSiam, which uses a Multi-Position-based Mix strategy (MPMix) and Siamese network structure for defect classification. Furthermore, considering the prediction noise problem in unlabeled data during training, we propose a progressive MPMix (MPMix+) strategy to reduce the negative impacts of noise on model training. Finally, we validate the effectiveness of our architecture on industrial datasets. For example, our method achieves 71.40% and 87.01% accuracy on the SMT (Surface Mounting Technology) dataset and MBH (Motor Brush Holder) dataset with only 100 labeled samples, which are 2.40% and 5.86% higher than the state-of-the-art FixMatch method, respectively. Compared with the supervised algorithm with 3,600 labels, our method achieves comparable accuracy on the SMT and MBH datasets, respectively, while saving 2/3 the amount of labeled data. In conclusion, MixSiam effectively utilizes unlabeled industrial data and improves model accuracy with fewer labeled samples, thus reducing the burden of data annotation in industrial production.</p></div>","PeriodicalId":55975,"journal":{"name":"Journal of Industrial Information Integration","volume":"40 ","pages":"Article 100615"},"PeriodicalIF":10.4000,"publicationDate":"2024-04-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Multi-position industrial defect inspection using self-training siamese networks with mix strategies\",\"authors\":\"Fangjun Wang , Xurong Chi , Liangwu Wei , Yanzhi Song , Zhouwang Yang\",\"doi\":\"10.1016/j.jii.2024.100615\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Structural defects account for a large proportion of defects, and acquiring large batches of high-quality labels is labor-intensive and time-consuming for industrial visual defect inspection tasks. This paper addresses the above problem by exploiting sufficient unlabeled samples, and aims to achieve superior model performance with some labeled data by using self-training methods that incorporate positional information. Specifically, this paper proposes a novel self-training architecture, MixSiam, which uses a Multi-Position-based Mix strategy (MPMix) and Siamese network structure for defect classification. Furthermore, considering the prediction noise problem in unlabeled data during training, we propose a progressive MPMix (MPMix+) strategy to reduce the negative impacts of noise on model training. Finally, we validate the effectiveness of our architecture on industrial datasets. For example, our method achieves 71.40% and 87.01% accuracy on the SMT (Surface Mounting Technology) dataset and MBH (Motor Brush Holder) dataset with only 100 labeled samples, which are 2.40% and 5.86% higher than the state-of-the-art FixMatch method, respectively. Compared with the supervised algorithm with 3,600 labels, our method achieves comparable accuracy on the SMT and MBH datasets, respectively, while saving 2/3 the amount of labeled data. In conclusion, MixSiam effectively utilizes unlabeled industrial data and improves model accuracy with fewer labeled samples, thus reducing the burden of data annotation in industrial production.</p></div>\",\"PeriodicalId\":55975,\"journal\":{\"name\":\"Journal of Industrial Information Integration\",\"volume\":\"40 \",\"pages\":\"Article 100615\"},\"PeriodicalIF\":10.4000,\"publicationDate\":\"2024-04-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Industrial Information Integration\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2452414X24000591\",\"RegionNum\":1,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Industrial Information Integration","FirstCategoryId":"94","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2452414X24000591","RegionNum":1,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Multi-position industrial defect inspection using self-training siamese networks with mix strategies
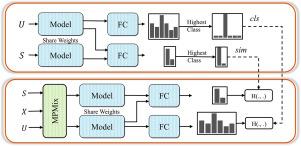
Structural defects account for a large proportion of defects, and acquiring large batches of high-quality labels is labor-intensive and time-consuming for industrial visual defect inspection tasks. This paper addresses the above problem by exploiting sufficient unlabeled samples, and aims to achieve superior model performance with some labeled data by using self-training methods that incorporate positional information. Specifically, this paper proposes a novel self-training architecture, MixSiam, which uses a Multi-Position-based Mix strategy (MPMix) and Siamese network structure for defect classification. Furthermore, considering the prediction noise problem in unlabeled data during training, we propose a progressive MPMix (MPMix+) strategy to reduce the negative impacts of noise on model training. Finally, we validate the effectiveness of our architecture on industrial datasets. For example, our method achieves 71.40% and 87.01% accuracy on the SMT (Surface Mounting Technology) dataset and MBH (Motor Brush Holder) dataset with only 100 labeled samples, which are 2.40% and 5.86% higher than the state-of-the-art FixMatch method, respectively. Compared with the supervised algorithm with 3,600 labels, our method achieves comparable accuracy on the SMT and MBH datasets, respectively, while saving 2/3 the amount of labeled data. In conclusion, MixSiam effectively utilizes unlabeled industrial data and improves model accuracy with fewer labeled samples, thus reducing the burden of data annotation in industrial production.
期刊介绍:
The Journal of Industrial Information Integration focuses on the industry's transition towards industrial integration and informatization, covering not only hardware and software but also information integration. It serves as a platform for promoting advances in industrial information integration, addressing challenges, issues, and solutions in an interdisciplinary forum for researchers, practitioners, and policy makers.
The Journal of Industrial Information Integration welcomes papers on foundational, technical, and practical aspects of industrial information integration, emphasizing the complex and cross-disciplinary topics that arise in industrial integration. Techniques from mathematical science, computer science, computer engineering, electrical and electronic engineering, manufacturing engineering, and engineering management are crucial in this context.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


