{"title":"带有事实强化和情感唤醒功能的视频情感描述","authors":"Pengjie Tang, Hong Rao, Ai Zhang, Yunlan Tan","doi":"10.1007/s12652-024-04779-x","DOIUrl":null,"url":null,"abstract":"<p>Video description aims to translate the visual content in a video with appropriate natural language. Most of current works only focus on the description of factual content, paying insufficient attention to the emotions in the video. And the sentences always lack flexibility and vividness. In this work, a fact enhancement and emotion awakening based model is proposed to describe the video, making the sentence more attractive and colorful. The strategy of deep incremental leaning is employed to build a multi-layer sequential network firstly, and multi-stage training method is used to sufficiently optimize the model. Secondly, the modules of fact inspiration, fact reinforcement and emotion awakening are constructed layer by layer to discovery more facts and embed emotions naturally. The three modules are cumulatively trained to sufficiently mine the factual and emotional information. Two public datasets including EmVidCap-S and EmVidCap are employed to evaluate the proposed model. The experimental results show that the performance of the proposed model is superior to not only the baseline models, but also the other popular methods.</p>","PeriodicalId":14959,"journal":{"name":"Journal of Ambient Intelligence and Humanized Computing","volume":"23 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-04-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Video emotional description with fact reinforcement and emotion awaking\",\"authors\":\"Pengjie Tang, Hong Rao, Ai Zhang, Yunlan Tan\",\"doi\":\"10.1007/s12652-024-04779-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Video description aims to translate the visual content in a video with appropriate natural language. Most of current works only focus on the description of factual content, paying insufficient attention to the emotions in the video. And the sentences always lack flexibility and vividness. In this work, a fact enhancement and emotion awakening based model is proposed to describe the video, making the sentence more attractive and colorful. The strategy of deep incremental leaning is employed to build a multi-layer sequential network firstly, and multi-stage training method is used to sufficiently optimize the model. Secondly, the modules of fact inspiration, fact reinforcement and emotion awakening are constructed layer by layer to discovery more facts and embed emotions naturally. The three modules are cumulatively trained to sufficiently mine the factual and emotional information. Two public datasets including EmVidCap-S and EmVidCap are employed to evaluate the proposed model. The experimental results show that the performance of the proposed model is superior to not only the baseline models, but also the other popular methods.</p>\",\"PeriodicalId\":14959,\"journal\":{\"name\":\"Journal of Ambient Intelligence and Humanized Computing\",\"volume\":\"23 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-04-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Ambient Intelligence and Humanized Computing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s12652-024-04779-x\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Ambient Intelligence and Humanized Computing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12652-024-04779-x","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Computer Science","Score":null,"Total":0}
Video emotional description with fact reinforcement and emotion awaking
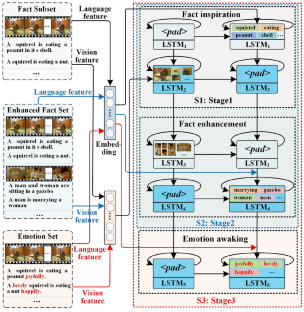
Video description aims to translate the visual content in a video with appropriate natural language. Most of current works only focus on the description of factual content, paying insufficient attention to the emotions in the video. And the sentences always lack flexibility and vividness. In this work, a fact enhancement and emotion awakening based model is proposed to describe the video, making the sentence more attractive and colorful. The strategy of deep incremental leaning is employed to build a multi-layer sequential network firstly, and multi-stage training method is used to sufficiently optimize the model. Secondly, the modules of fact inspiration, fact reinforcement and emotion awakening are constructed layer by layer to discovery more facts and embed emotions naturally. The three modules are cumulatively trained to sufficiently mine the factual and emotional information. Two public datasets including EmVidCap-S and EmVidCap are employed to evaluate the proposed model. The experimental results show that the performance of the proposed model is superior to not only the baseline models, but also the other popular methods.
期刊介绍:
The purpose of JAIHC is to provide a high profile, leading edge forum for academics, industrial professionals, educators and policy makers involved in the field to contribute, to disseminate the most innovative researches and developments of all aspects of ambient intelligence and humanized computing, such as intelligent/smart objects, environments/spaces, and systems. The journal discusses various technical, safety, personal, social, physical, political, artistic and economic issues. The research topics covered by the journal are (but not limited to):
Pervasive/Ubiquitous Computing and Applications
Cognitive wireless sensor network
Embedded Systems and Software
Mobile Computing and Wireless Communications
Next Generation Multimedia Systems
Security, Privacy and Trust
Service and Semantic Computing
Advanced Networking Architectures
Dependable, Reliable and Autonomic Computing
Embedded Smart Agents
Context awareness, social sensing and inference
Multi modal interaction design
Ergonomics and product prototyping
Intelligent and self-organizing transportation networks & services
Healthcare Systems
Virtual Humans & Virtual Worlds
Wearables sensors and actuators

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


