{"title":"ProRLearn:通过强化学习提高基于提示调整的漏洞检测能力","authors":"Zilong Ren, Xiaolin Ju, Xiang Chen, Hao Shen","doi":"10.1007/s10515-024-00438-9","DOIUrl":null,"url":null,"abstract":"<div><p>Software vulnerability detection is a critical step in ensuring system security and data protection. Recent research has demonstrated the effectiveness of deep learning in automated vulnerability detection. However, it is difficult for deep learning models to understand the semantics and domain-specific knowledge of source code. In this study, we introduce a new vulnerability detection framework, ProRLearn, which leverages two main techniques: prompt tuning and reinforcement learning. Since existing fine-tuning of pre-trained language models (PLMs) struggles to leverage domain knowledge fully, we introduce a new automatic prompt-tuning technique. Precisely, prompt tuning mimics the pre-training process of PLMs by rephrasing task input and adding prompts, using the PLM’s output as the prediction output. The introduction of the reinforcement learning reward mechanism aims to guide the behavior of vulnerability detection through a reward and punishment model, enabling it to learn effective strategies for obtaining maximum long-term rewards in specific environments. The introduction of reinforcement learning aims to encourage the model to learn how to maximize rewards or minimize penalties, thus enhancing performance. Experiments on three datasets (FFMPeg+Qemu, Reveal, and Big-Vul) indicate that ProRLearn achieves performance improvement of 3.27–70.96% over state-of-the-art baselines in terms of F1 score. The combination of prompt tuning and reinforcement learning can offer a potential opportunity to improve performance in vulnerability detection. This means that it can effectively improve the performance in responding to constantly changing network environments and new threats. This interdisciplinary approach contributes to a better understanding of the interplay between natural language processing and reinforcement learning, opening up new opportunities and challenges for future research and applications.</p></div>","PeriodicalId":55414,"journal":{"name":"Automated Software Engineering","volume":"31 2","pages":""},"PeriodicalIF":2.0000,"publicationDate":"2024-04-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"ProRLearn: boosting prompt tuning-based vulnerability detection by reinforcement learning\",\"authors\":\"Zilong Ren, Xiaolin Ju, Xiang Chen, Hao Shen\",\"doi\":\"10.1007/s10515-024-00438-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Software vulnerability detection is a critical step in ensuring system security and data protection. Recent research has demonstrated the effectiveness of deep learning in automated vulnerability detection. However, it is difficult for deep learning models to understand the semantics and domain-specific knowledge of source code. In this study, we introduce a new vulnerability detection framework, ProRLearn, which leverages two main techniques: prompt tuning and reinforcement learning. Since existing fine-tuning of pre-trained language models (PLMs) struggles to leverage domain knowledge fully, we introduce a new automatic prompt-tuning technique. Precisely, prompt tuning mimics the pre-training process of PLMs by rephrasing task input and adding prompts, using the PLM’s output as the prediction output. The introduction of the reinforcement learning reward mechanism aims to guide the behavior of vulnerability detection through a reward and punishment model, enabling it to learn effective strategies for obtaining maximum long-term rewards in specific environments. The introduction of reinforcement learning aims to encourage the model to learn how to maximize rewards or minimize penalties, thus enhancing performance. Experiments on three datasets (FFMPeg+Qemu, Reveal, and Big-Vul) indicate that ProRLearn achieves performance improvement of 3.27–70.96% over state-of-the-art baselines in terms of F1 score. The combination of prompt tuning and reinforcement learning can offer a potential opportunity to improve performance in vulnerability detection. This means that it can effectively improve the performance in responding to constantly changing network environments and new threats. This interdisciplinary approach contributes to a better understanding of the interplay between natural language processing and reinforcement learning, opening up new opportunities and challenges for future research and applications.</p></div>\",\"PeriodicalId\":55414,\"journal\":{\"name\":\"Automated Software Engineering\",\"volume\":\"31 2\",\"pages\":\"\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2024-04-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Automated Software Engineering\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10515-024-00438-9\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, SOFTWARE ENGINEERING\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Automated Software Engineering","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10515-024-00438-9","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, SOFTWARE ENGINEERING","Score":null,"Total":0}
引用次数: 0
摘要
软件漏洞检测是确保系统安全和数据保护的关键一步。最近的研究证明了深度学习在自动漏洞检测中的有效性。然而,深度学习模型很难理解源代码的语义和特定领域知识。在本研究中,我们介绍了一种新的漏洞检测框架 ProRLearn,它利用了两种主要技术:及时调整和强化学习。由于现有的预训练语言模型(PLM)的微调难以充分利用领域知识,我们引入了一种新的自动提示调整技术。确切地说,提示调整模拟了预训练语言模型的预训练过程,通过重新措辞任务输入并添加提示,将预训练语言模型的输出作为预测输出。引入强化学习奖励机制,旨在通过奖惩模型引导漏洞检测行为,使其学习有效策略,在特定环境中获得最大的长期回报。引入强化学习的目的是鼓励模型学习如何使奖励最大化或惩罚最小化,从而提高性能。在三个数据集(FFMPeg+Qemu、Reveal 和 Big-Vul)上的实验表明,就 F1 分数而言,ProRLearn 比最先进的基线模型提高了 3.27%-70.96% 的性能。提示调整与强化学习的结合为提高漏洞检测性能提供了潜在的机会。这意味着,它能有效提高应对不断变化的网络环境和新威胁的性能。这种跨学科方法有助于更好地理解自然语言处理和强化学习之间的相互作用,为未来的研究和应用带来了新的机遇和挑战。
ProRLearn: boosting prompt tuning-based vulnerability detection by reinforcement learning
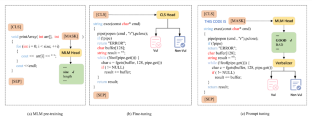
Software vulnerability detection is a critical step in ensuring system security and data protection. Recent research has demonstrated the effectiveness of deep learning in automated vulnerability detection. However, it is difficult for deep learning models to understand the semantics and domain-specific knowledge of source code. In this study, we introduce a new vulnerability detection framework, ProRLearn, which leverages two main techniques: prompt tuning and reinforcement learning. Since existing fine-tuning of pre-trained language models (PLMs) struggles to leverage domain knowledge fully, we introduce a new automatic prompt-tuning technique. Precisely, prompt tuning mimics the pre-training process of PLMs by rephrasing task input and adding prompts, using the PLM’s output as the prediction output. The introduction of the reinforcement learning reward mechanism aims to guide the behavior of vulnerability detection through a reward and punishment model, enabling it to learn effective strategies for obtaining maximum long-term rewards in specific environments. The introduction of reinforcement learning aims to encourage the model to learn how to maximize rewards or minimize penalties, thus enhancing performance. Experiments on three datasets (FFMPeg+Qemu, Reveal, and Big-Vul) indicate that ProRLearn achieves performance improvement of 3.27–70.96% over state-of-the-art baselines in terms of F1 score. The combination of prompt tuning and reinforcement learning can offer a potential opportunity to improve performance in vulnerability detection. This means that it can effectively improve the performance in responding to constantly changing network environments and new threats. This interdisciplinary approach contributes to a better understanding of the interplay between natural language processing and reinforcement learning, opening up new opportunities and challenges for future research and applications.
期刊介绍:
This journal details research, tutorial papers, survey and accounts of significant industrial experience in the foundations, techniques, tools and applications of automated software engineering technology. This includes the study of techniques for constructing, understanding, adapting, and modeling software artifacts and processes.
Coverage in Automated Software Engineering examines both automatic systems and collaborative systems as well as computational models of human software engineering activities. In addition, it presents knowledge representations and artificial intelligence techniques applicable to automated software engineering, and formal techniques that support or provide theoretical foundations. The journal also includes reviews of books, software, conferences and workshops.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


