{"title":"基于 FPGA 的上行 NOMA 网络 SIC 硬件加速器","authors":"Sreenu Sunkaraboina, Kalpana Naidu","doi":"10.1007/s11235-024-01144-3","DOIUrl":null,"url":null,"abstract":"<p>Non-Orthogonal Multiple Access (NOMA) is an emerging multiple access scheme for the fifth-generation (5G) and beyond 5G mobile communications. Since NOMA supports a massive number of users simultaneously in a single time/frequency resource block through power domain multiplexing. However, the “Successive Interference Cancellation (SIC)” decoding technique at the receiver is an intricate task in the NOMA systems. Even though SIC operates in a sequential manner, multiple parallel SIC operations can be performed when deploying user pairing. Hence, outsourcing the efficient parallel processing devices is a suitable solution to compute all clusters SIC swiftly. In this paper, we design an efficient high-speed FPGA-based hardware accelerator for SIC implementation in uplink NOMA systems with user pairing on the 32-bit low-memory edge device (PYNQ-Z2 board). Ultimately, experimental results corroborate that the proposed accelerator design provides better SIC computation time than the NVIDIA Tesla K80 Graphics Processing Unit, Central Processing Unit, and ARM-Processor on PYNQ-Z2 board.\n</p>","PeriodicalId":51194,"journal":{"name":"Telecommunication Systems","volume":"49 1","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-04-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"FPGA-based hardware accelerator for SIC in uplink NOMA networks\",\"authors\":\"Sreenu Sunkaraboina, Kalpana Naidu\",\"doi\":\"10.1007/s11235-024-01144-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Non-Orthogonal Multiple Access (NOMA) is an emerging multiple access scheme for the fifth-generation (5G) and beyond 5G mobile communications. Since NOMA supports a massive number of users simultaneously in a single time/frequency resource block through power domain multiplexing. However, the “Successive Interference Cancellation (SIC)” decoding technique at the receiver is an intricate task in the NOMA systems. Even though SIC operates in a sequential manner, multiple parallel SIC operations can be performed when deploying user pairing. Hence, outsourcing the efficient parallel processing devices is a suitable solution to compute all clusters SIC swiftly. In this paper, we design an efficient high-speed FPGA-based hardware accelerator for SIC implementation in uplink NOMA systems with user pairing on the 32-bit low-memory edge device (PYNQ-Z2 board). Ultimately, experimental results corroborate that the proposed accelerator design provides better SIC computation time than the NVIDIA Tesla K80 Graphics Processing Unit, Central Processing Unit, and ARM-Processor on PYNQ-Z2 board.\\n</p>\",\"PeriodicalId\":51194,\"journal\":{\"name\":\"Telecommunication Systems\",\"volume\":\"49 1\",\"pages\":\"\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-04-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Telecommunication Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11235-024-01144-3\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"TELECOMMUNICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Telecommunication Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11235-024-01144-3","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"TELECOMMUNICATIONS","Score":null,"Total":0}
引用次数: 0
摘要
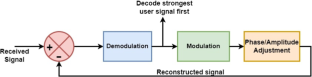
非正交多址接入(NOMA)是一种新兴的多址接入方案,适用于第五代(5G)及以后的 5G 移动通信。由于 NOMA 通过功率域多路复用,可在单个时/频资源块中同时支持大量用户。然而,在 NOMA 系统中,接收器的 "连续干扰消除(SIC)"解码技术是一项复杂的任务。尽管 SIC 以顺序方式运行,但在部署用户配对时可以执行多个并行 SIC 操作。因此,外购高效并行处理设备是快速计算所有集群 SIC 的合适解决方案。本文设计了一种基于 FPGA 的高效高速硬件加速器,用于在 32 位低内存边缘设备(PYNQ-Z2 板)上实现用户配对的上行 NOMA 系统中的 SIC。实验结果最终证实,与PYNQ-Z2板上的英伟达™(NVIDIA®)Tesla K80图形处理单元、中央处理单元和ARM处理器相比,本文提出的加速器设计能提供更好的SIC计算时间。
FPGA-based hardware accelerator for SIC in uplink NOMA networks
Non-Orthogonal Multiple Access (NOMA) is an emerging multiple access scheme for the fifth-generation (5G) and beyond 5G mobile communications. Since NOMA supports a massive number of users simultaneously in a single time/frequency resource block through power domain multiplexing. However, the “Successive Interference Cancellation (SIC)” decoding technique at the receiver is an intricate task in the NOMA systems. Even though SIC operates in a sequential manner, multiple parallel SIC operations can be performed when deploying user pairing. Hence, outsourcing the efficient parallel processing devices is a suitable solution to compute all clusters SIC swiftly. In this paper, we design an efficient high-speed FPGA-based hardware accelerator for SIC implementation in uplink NOMA systems with user pairing on the 32-bit low-memory edge device (PYNQ-Z2 board). Ultimately, experimental results corroborate that the proposed accelerator design provides better SIC computation time than the NVIDIA Tesla K80 Graphics Processing Unit, Central Processing Unit, and ARM-Processor on PYNQ-Z2 board.
期刊介绍:
Telecommunication Systems is a journal covering all aspects of modeling, analysis, design and management of telecommunication systems. The journal publishes high quality articles dealing with the use of analytic and quantitative tools for the modeling, analysis, design and management of telecommunication systems covering:
Performance Evaluation of Wide Area and Local Networks;
Network Interconnection;
Wire, wireless, Adhoc, mobile networks;
Impact of New Services (economic and organizational impact);
Fiberoptics and photonic switching;
DSL, ADSL, cable TV and their impact;
Design and Analysis Issues in Metropolitan Area Networks;
Networking Protocols;
Dynamics and Capacity Expansion of Telecommunication Systems;
Multimedia Based Systems, Their Design Configuration and Impact;
Configuration of Distributed Systems;
Pricing for Networking and Telecommunication Services;
Performance Analysis of Local Area Networks;
Distributed Group Decision Support Systems;
Configuring Telecommunication Systems with Reliability and Availability;
Cost Benefit Analysis and Economic Impact of Telecommunication Systems;
Standardization and Regulatory Issues;
Security, Privacy and Encryption in Telecommunication Systems;
Cellular, Mobile and Satellite Based Systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


