Neni Alya Firdausanti, Israel Mendonça, Masayoshi Aritsugi
{"title":"针对不平衡分类问题的无噪声采样与多数框架","authors":"Neni Alya Firdausanti, Israel Mendonça, Masayoshi Aritsugi","doi":"10.1007/s10115-024-02079-6","DOIUrl":null,"url":null,"abstract":"<p>Class imbalance has been widely accepted as a significant factor that negatively impacts a machine learning classifier’s performance. One of the techniques to avoid this problem is to balance the data distribution by using sampling-based approaches, in which synthetic data is generated using the probability distribution of the classes. However, this process is sensitive to the presence of noise in the data, and the boundaries between the majority class and the minority class are blurred. Such phenomena shift the algorithm’s decision boundary away from the ideal outcome. In this work, we propose a hybrid framework for two primary objectives. The first objective is to address class distribution imbalance by synthetically increasing the data of a minority class, and the second objective is, to devise an efficient noise reduction technique that improves the class balance algorithm. The proposed framework focuses on removing noisy elements from the majority class, and by doing so, provides more accurate information to the subsequent synthetic data generator algorithm. To evaluate the effectiveness of our framework, we employ the geometric mean (<i>G</i>-mean) as the evaluation metric. The experimental results show that our framework is capable of improving the prediction <i>G</i>-mean for eight classifiers across eleven datasets. The range of improvements varies from 7.78% on the Loan dataset to 67.45% on the Abalone19_vs_10-11-12-13 dataset.</p>","PeriodicalId":54749,"journal":{"name":"Knowledge and Information Systems","volume":"55 1","pages":""},"PeriodicalIF":3.1000,"publicationDate":"2024-04-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Noise-free sampling with majority framework for an imbalanced classification problem\",\"authors\":\"Neni Alya Firdausanti, Israel Mendonça, Masayoshi Aritsugi\",\"doi\":\"10.1007/s10115-024-02079-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Class imbalance has been widely accepted as a significant factor that negatively impacts a machine learning classifier’s performance. One of the techniques to avoid this problem is to balance the data distribution by using sampling-based approaches, in which synthetic data is generated using the probability distribution of the classes. However, this process is sensitive to the presence of noise in the data, and the boundaries between the majority class and the minority class are blurred. Such phenomena shift the algorithm’s decision boundary away from the ideal outcome. In this work, we propose a hybrid framework for two primary objectives. The first objective is to address class distribution imbalance by synthetically increasing the data of a minority class, and the second objective is, to devise an efficient noise reduction technique that improves the class balance algorithm. The proposed framework focuses on removing noisy elements from the majority class, and by doing so, provides more accurate information to the subsequent synthetic data generator algorithm. To evaluate the effectiveness of our framework, we employ the geometric mean (<i>G</i>-mean) as the evaluation metric. The experimental results show that our framework is capable of improving the prediction <i>G</i>-mean for eight classifiers across eleven datasets. The range of improvements varies from 7.78% on the Loan dataset to 67.45% on the Abalone19_vs_10-11-12-13 dataset.</p>\",\"PeriodicalId\":54749,\"journal\":{\"name\":\"Knowledge and Information Systems\",\"volume\":\"55 1\",\"pages\":\"\"},\"PeriodicalIF\":3.1000,\"publicationDate\":\"2024-04-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Knowledge and Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10115-024-02079-6\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Knowledge and Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10115-024-02079-6","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Noise-free sampling with majority framework for an imbalanced classification problem
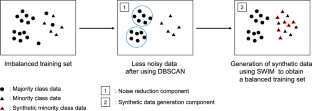
Class imbalance has been widely accepted as a significant factor that negatively impacts a machine learning classifier’s performance. One of the techniques to avoid this problem is to balance the data distribution by using sampling-based approaches, in which synthetic data is generated using the probability distribution of the classes. However, this process is sensitive to the presence of noise in the data, and the boundaries between the majority class and the minority class are blurred. Such phenomena shift the algorithm’s decision boundary away from the ideal outcome. In this work, we propose a hybrid framework for two primary objectives. The first objective is to address class distribution imbalance by synthetically increasing the data of a minority class, and the second objective is, to devise an efficient noise reduction technique that improves the class balance algorithm. The proposed framework focuses on removing noisy elements from the majority class, and by doing so, provides more accurate information to the subsequent synthetic data generator algorithm. To evaluate the effectiveness of our framework, we employ the geometric mean (G-mean) as the evaluation metric. The experimental results show that our framework is capable of improving the prediction G-mean for eight classifiers across eleven datasets. The range of improvements varies from 7.78% on the Loan dataset to 67.45% on the Abalone19_vs_10-11-12-13 dataset.
期刊介绍:
Knowledge and Information Systems (KAIS) provides an international forum for researchers and professionals to share their knowledge and report new advances on all topics related to knowledge systems and advanced information systems. This monthly peer-reviewed archival journal publishes state-of-the-art research reports on emerging topics in KAIS, reviews of important techniques in related areas, and application papers of interest to a general readership.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


