Simona Colucci, Francesco M. Donini, Eugenio Di Sciascio
{"title":"基于 RDF 的语义网系统的推理特点综述","authors":"Simona Colucci, Francesco M. Donini, Eugenio Di Sciascio","doi":"10.1002/widm.1537","DOIUrl":null,"url":null,"abstract":"Presented as a research challenge in 2001, the Semantic Web (SW) is now a mature technology, used in several cross-domain applications. One of its key benefits is a formal semantics of its RDF data format, which enables a system to validate data, infer implicit knowledge by automated reasoning, and explain it to a user; yet the analysis presented here of 71 RDF-based SW systems (out of which 17 reasoners) reveals that the exploitation of such semantics varies a lot among all SW applications. Since the simple enumeration of systems, each one with its characteristics, might result in a clueless listing, we borrow from Software Engineering the idea of maturity model, and organize our classification around it. Our model has three orthogonal dimensions: treatment of blank nodes, degree of deductive capabilities, and explanation of results. For each dimension, we define 3–4 levels of increasing exploitation of semantics, corresponding to an increasingly sophisticated output in that dimension. Each system is then classified in each dimension, based on its documentation and published articles. The distribution of systems along each dimension is depicted in the graphical abstract. We deliberately exclude resources consumption (time and space) since it is a dimension not peculiar to SW.","PeriodicalId":501013,"journal":{"name":"WIREs Data Mining and Knowledge Discovery","volume":"35 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2024-03-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A review of reasoning characteristics of RDF-based Semantic Web systems\",\"authors\":\"Simona Colucci, Francesco M. Donini, Eugenio Di Sciascio\",\"doi\":\"10.1002/widm.1537\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Presented as a research challenge in 2001, the Semantic Web (SW) is now a mature technology, used in several cross-domain applications. One of its key benefits is a formal semantics of its RDF data format, which enables a system to validate data, infer implicit knowledge by automated reasoning, and explain it to a user; yet the analysis presented here of 71 RDF-based SW systems (out of which 17 reasoners) reveals that the exploitation of such semantics varies a lot among all SW applications. Since the simple enumeration of systems, each one with its characteristics, might result in a clueless listing, we borrow from Software Engineering the idea of maturity model, and organize our classification around it. Our model has three orthogonal dimensions: treatment of blank nodes, degree of deductive capabilities, and explanation of results. For each dimension, we define 3–4 levels of increasing exploitation of semantics, corresponding to an increasingly sophisticated output in that dimension. Each system is then classified in each dimension, based on its documentation and published articles. The distribution of systems along each dimension is depicted in the graphical abstract. We deliberately exclude resources consumption (time and space) since it is a dimension not peculiar to SW.\",\"PeriodicalId\":501013,\"journal\":{\"name\":\"WIREs Data Mining and Knowledge Discovery\",\"volume\":\"35 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-03-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"WIREs Data Mining and Knowledge Discovery\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1002/widm.1537\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"WIREs Data Mining and Knowledge Discovery","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1002/widm.1537","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
A review of reasoning characteristics of RDF-based Semantic Web systems
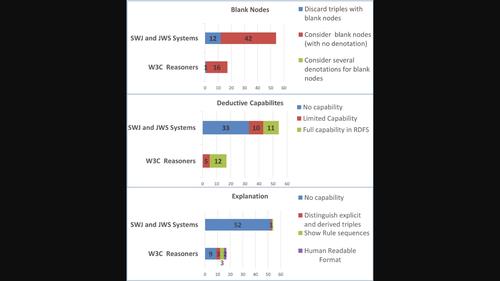
Presented as a research challenge in 2001, the Semantic Web (SW) is now a mature technology, used in several cross-domain applications. One of its key benefits is a formal semantics of its RDF data format, which enables a system to validate data, infer implicit knowledge by automated reasoning, and explain it to a user; yet the analysis presented here of 71 RDF-based SW systems (out of which 17 reasoners) reveals that the exploitation of such semantics varies a lot among all SW applications. Since the simple enumeration of systems, each one with its characteristics, might result in a clueless listing, we borrow from Software Engineering the idea of maturity model, and organize our classification around it. Our model has three orthogonal dimensions: treatment of blank nodes, degree of deductive capabilities, and explanation of results. For each dimension, we define 3–4 levels of increasing exploitation of semantics, corresponding to an increasingly sophisticated output in that dimension. Each system is then classified in each dimension, based on its documentation and published articles. The distribution of systems along each dimension is depicted in the graphical abstract. We deliberately exclude resources consumption (time and space) since it is a dimension not peculiar to SW.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


