Cheng Peng , Xi Yang , Kaleb E Smith , Zehao Yu , Aokun Chen , Jiang Bian , Yonghui Wu
{"title":"模型调整还是提示调整?用于临床概念和关系提取的大型语言模型研究","authors":"Cheng Peng , Xi Yang , Kaleb E Smith , Zehao Yu , Aokun Chen , Jiang Bian , Yonghui Wu","doi":"10.1016/j.jbi.2024.104630","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>To develop soft prompt-based learning architecture for large language models (LLMs), examine prompt-tuning using frozen/unfrozen LLMs, and assess their abilities in transfer learning and few-shot learning.</p></div><div><h3>Methods</h3><p>We developed a soft prompt-based learning architecture and compared 4 strategies including (1) fine-tuning without prompts; (2) hard-prompting with unfrozen LLMs; (3) soft-prompting with unfrozen LLMs; and (4) soft-prompting with frozen LLMs. We evaluated GatorTron, a clinical LLM with up to 8.9 billion parameters, and compared GatorTron with 4 existing transformer models for clinical concept and relation extraction on 2 benchmark datasets for adverse drug events and social determinants of health (SDoH). We evaluated the few-shot learning ability and generalizability for cross-institution applications.</p></div><div><h3>Results and Conclusion</h3><p>When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6 ∼ 3.1 % and 1.2 ∼ 2.9 %, respectively; GatorTron-345 M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming other two models by 0.2 ∼ 2 % and 0.6 ∼ 11.7 %, respectively. When LLMs are frozen, small LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen models. Soft prompting with a frozen GatorTron-8.9B model achieved the best performance for cross-institution evaluation. We demonstrate that (1) machines can learn soft prompts better than hard prompts composed by human, (2) frozen LLMs have good few-shot learning ability and generalizability for cross-institution applications, (3) frozen LLMs reduce computing cost to 2.5 ∼ 6 % of previous methods using unfrozen LLMs, and (4) frozen LLMs require large models (e.g., over several billions of parameters) for good performance.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":null,"pages":null},"PeriodicalIF":4.0000,"publicationDate":"2024-03-26","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Model tuning or prompt Tuning? a study of large language models for clinical concept and relation extraction\",\"authors\":\"Cheng Peng , Xi Yang , Kaleb E Smith , Zehao Yu , Aokun Chen , Jiang Bian , Yonghui Wu\",\"doi\":\"10.1016/j.jbi.2024.104630\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><p>To develop soft prompt-based learning architecture for large language models (LLMs), examine prompt-tuning using frozen/unfrozen LLMs, and assess their abilities in transfer learning and few-shot learning.</p></div><div><h3>Methods</h3><p>We developed a soft prompt-based learning architecture and compared 4 strategies including (1) fine-tuning without prompts; (2) hard-prompting with unfrozen LLMs; (3) soft-prompting with unfrozen LLMs; and (4) soft-prompting with frozen LLMs. We evaluated GatorTron, a clinical LLM with up to 8.9 billion parameters, and compared GatorTron with 4 existing transformer models for clinical concept and relation extraction on 2 benchmark datasets for adverse drug events and social determinants of health (SDoH). We evaluated the few-shot learning ability and generalizability for cross-institution applications.</p></div><div><h3>Results and Conclusion</h3><p>When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6 ∼ 3.1 % and 1.2 ∼ 2.9 %, respectively; GatorTron-345 M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming other two models by 0.2 ∼ 2 % and 0.6 ∼ 11.7 %, respectively. When LLMs are frozen, small LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen models. Soft prompting with a frozen GatorTron-8.9B model achieved the best performance for cross-institution evaluation. We demonstrate that (1) machines can learn soft prompts better than hard prompts composed by human, (2) frozen LLMs have good few-shot learning ability and generalizability for cross-institution applications, (3) frozen LLMs reduce computing cost to 2.5 ∼ 6 % of previous methods using unfrozen LLMs, and (4) frozen LLMs require large models (e.g., over several billions of parameters) for good performance.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-03-26\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000480\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000480","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Model tuning or prompt Tuning? a study of large language models for clinical concept and relation extraction
Objective
To develop soft prompt-based learning architecture for large language models (LLMs), examine prompt-tuning using frozen/unfrozen LLMs, and assess their abilities in transfer learning and few-shot learning.
Methods
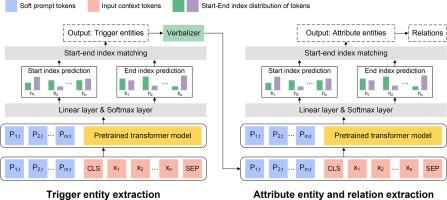
We developed a soft prompt-based learning architecture and compared 4 strategies including (1) fine-tuning without prompts; (2) hard-prompting with unfrozen LLMs; (3) soft-prompting with unfrozen LLMs; and (4) soft-prompting with frozen LLMs. We evaluated GatorTron, a clinical LLM with up to 8.9 billion parameters, and compared GatorTron with 4 existing transformer models for clinical concept and relation extraction on 2 benchmark datasets for adverse drug events and social determinants of health (SDoH). We evaluated the few-shot learning ability and generalizability for cross-institution applications.
Results and Conclusion
When LLMs are unfrozen, GatorTron-3.9B with soft prompting achieves the best strict F1-scores of 0.9118 and 0.8604 for concept extraction, outperforming the traditional fine-tuning and hard prompt-based models by 0.6 ∼ 3.1 % and 1.2 ∼ 2.9 %, respectively; GatorTron-345 M with soft prompting achieves the best F1-scores of 0.8332 and 0.7488 for end-to-end relation extraction, outperforming other two models by 0.2 ∼ 2 % and 0.6 ∼ 11.7 %, respectively. When LLMs are frozen, small LLMs have a big gap to be competitive with unfrozen models; scaling LLMs up to billions of parameters makes frozen LLMs competitive with unfrozen models. Soft prompting with a frozen GatorTron-8.9B model achieved the best performance for cross-institution evaluation. We demonstrate that (1) machines can learn soft prompts better than hard prompts composed by human, (2) frozen LLMs have good few-shot learning ability and generalizability for cross-institution applications, (3) frozen LLMs reduce computing cost to 2.5 ∼ 6 % of previous methods using unfrozen LLMs, and (4) frozen LLMs require large models (e.g., over several billions of parameters) for good performance.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


