{"title":"利用声学和音素特征学习深度嵌入,用于调频广播中的扬声器识别","authors":"Xiao Li, Xiao Chen, Rui Fu, Xiao Hu, Mintong Chen, Kun Niu","doi":"10.1049/2024/6694481","DOIUrl":null,"url":null,"abstract":"<p>Text-independent speaker verification (TI-SV) is a crucial task in speaker recognition, as it involves verifying an individual’s claimed identity from speech of arbitrary content without any human intervention. The target for TI-SV is to design a discriminative network to learn deep speaker embedding for speaker idiosyncrasy. In this paper, we propose a deep speaker embedding learning approach of a hybrid deep neural network (DNN) for TI-SV in FM broadcasting. Not only acoustic features are utilized, but also phoneme features are introduced as prior knowledge to collectively learn deep speaker embedding. The hybrid DNN consists of a convolutional neural network architecture for generating acoustic features and a multilayer perceptron architecture for extracting phoneme features sequentially, which represent significant pronunciation attributes. The extracted acoustic and phoneme features are concatenated to form deep embedding descriptors for speaker identity. The hybrid DNN demonstrates not only the complementarity between acoustic and phoneme features but also the temporality of phoneme features in a sequence. Our experiments show that the hybrid DNN outperforms existing methods and delivers a remarkable performance in FM broadcasting TI-SV.</p>","PeriodicalId":48821,"journal":{"name":"IET Biometrics","volume":"2024 1","pages":""},"PeriodicalIF":1.8000,"publicationDate":"2024-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1049/2024/6694481","citationCount":"0","resultStr":"{\"title\":\"Learning Deep Embedding with Acoustic and Phoneme Features for Speaker Recognition in FM Broadcasting\",\"authors\":\"Xiao Li, Xiao Chen, Rui Fu, Xiao Hu, Mintong Chen, Kun Niu\",\"doi\":\"10.1049/2024/6694481\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Text-independent speaker verification (TI-SV) is a crucial task in speaker recognition, as it involves verifying an individual’s claimed identity from speech of arbitrary content without any human intervention. The target for TI-SV is to design a discriminative network to learn deep speaker embedding for speaker idiosyncrasy. In this paper, we propose a deep speaker embedding learning approach of a hybrid deep neural network (DNN) for TI-SV in FM broadcasting. Not only acoustic features are utilized, but also phoneme features are introduced as prior knowledge to collectively learn deep speaker embedding. The hybrid DNN consists of a convolutional neural network architecture for generating acoustic features and a multilayer perceptron architecture for extracting phoneme features sequentially, which represent significant pronunciation attributes. The extracted acoustic and phoneme features are concatenated to form deep embedding descriptors for speaker identity. The hybrid DNN demonstrates not only the complementarity between acoustic and phoneme features but also the temporality of phoneme features in a sequence. Our experiments show that the hybrid DNN outperforms existing methods and delivers a remarkable performance in FM broadcasting TI-SV.</p>\",\"PeriodicalId\":48821,\"journal\":{\"name\":\"IET Biometrics\",\"volume\":\"2024 1\",\"pages\":\"\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2024-03-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1049/2024/6694481\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"IET Biometrics\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/2024/6694481\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"IET Biometrics","FirstCategoryId":"94","ListUrlMain":"https://ietresearch.onlinelibrary.wiley.com/doi/10.1049/2024/6694481","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Learning Deep Embedding with Acoustic and Phoneme Features for Speaker Recognition in FM Broadcasting
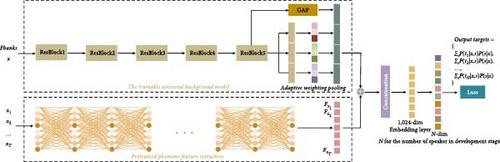
Text-independent speaker verification (TI-SV) is a crucial task in speaker recognition, as it involves verifying an individual’s claimed identity from speech of arbitrary content without any human intervention. The target for TI-SV is to design a discriminative network to learn deep speaker embedding for speaker idiosyncrasy. In this paper, we propose a deep speaker embedding learning approach of a hybrid deep neural network (DNN) for TI-SV in FM broadcasting. Not only acoustic features are utilized, but also phoneme features are introduced as prior knowledge to collectively learn deep speaker embedding. The hybrid DNN consists of a convolutional neural network architecture for generating acoustic features and a multilayer perceptron architecture for extracting phoneme features sequentially, which represent significant pronunciation attributes. The extracted acoustic and phoneme features are concatenated to form deep embedding descriptors for speaker identity. The hybrid DNN demonstrates not only the complementarity between acoustic and phoneme features but also the temporality of phoneme features in a sequence. Our experiments show that the hybrid DNN outperforms existing methods and delivers a remarkable performance in FM broadcasting TI-SV.
IET BiometricsCOMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE-
CiteScore
5.90
自引率
0.00%
发文量
46
审稿时长
33 weeks
期刊介绍:
The field of biometric recognition - automated recognition of individuals based on their behavioural and biological characteristics - has now reached a level of maturity where viable practical applications are both possible and increasingly available. The biometrics field is characterised especially by its interdisciplinarity since, while focused primarily around a strong technological base, effective system design and implementation often requires a broad range of skills encompassing, for example, human factors, data security and database technologies, psychological and physiological awareness, and so on. Also, the technology focus itself embraces diversity, since the engineering of effective biometric systems requires integration of image analysis, pattern recognition, sensor technology, database engineering, security design and many other strands of understanding.
The scope of the journal is intentionally relatively wide. While focusing on core technological issues, it is recognised that these may be inherently diverse and in many cases may cross traditional disciplinary boundaries. The scope of the journal will therefore include any topics where it can be shown that a paper can increase our understanding of biometric systems, signal future developments and applications for biometrics, or promote greater practical uptake for relevant technologies:
Development and enhancement of individual biometric modalities including the established and traditional modalities (e.g. face, fingerprint, iris, signature and handwriting recognition) and also newer or emerging modalities (gait, ear-shape, neurological patterns, etc.)
Multibiometrics, theoretical and practical issues, implementation of practical systems, multiclassifier and multimodal approaches
Soft biometrics and information fusion for identification, verification and trait prediction
Human factors and the human-computer interface issues for biometric systems, exception handling strategies
Template construction and template management, ageing factors and their impact on biometric systems
Usability and user-oriented design, psychological and physiological principles and system integration
Sensors and sensor technologies for biometric processing
Database technologies to support biometric systems
Implementation of biometric systems, security engineering implications, smartcard and associated technologies in implementation, implementation platforms, system design and performance evaluation
Trust and privacy issues, security of biometric systems and supporting technological solutions, biometric template protection
Biometric cryptosystems, security and biometrics-linked encryption
Links with forensic processing and cross-disciplinary commonalities
Core underpinning technologies (e.g. image analysis, pattern recognition, computer vision, signal processing, etc.), where the specific relevance to biometric processing can be demonstrated
Applications and application-led considerations
Position papers on technology or on the industrial context of biometric system development
Adoption and promotion of standards in biometrics, improving technology acceptance, deployment and interoperability, avoiding cross-cultural and cross-sector restrictions
Relevant ethical and social issues


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


