Muhamet Kastrati, Zenun Kastrati, Ali Shariq Imran, Marenglen Biba
{"title":"利用远程监督和深度学习进行 twitter 情感和情绪分类","authors":"Muhamet Kastrati, Zenun Kastrati, Ali Shariq Imran, Marenglen Biba","doi":"10.1007/s10844-024-00845-0","DOIUrl":null,"url":null,"abstract":"<p>Nowadays, various applications across industries, healthcare, and security have begun adopting automatic sentiment analysis and emotion detection in short texts, such as posts from social media. Twitter stands out as one of the most popular online social media platforms due to its easy, unique, and advanced accessibility using the API. On the other hand, supervised learning is the most widely used paradigm for tasks involving sentiment polarity and fine-grained emotion detection in short and informal texts, such as Twitter posts. However, supervised learning models are data-hungry and heavily reliant on abundant labeled data, which remains a challenge. This study aims to address this challenge by creating a large-scale real-world dataset of 17.5 million tweets. A distant supervision approach relying on emojis available in tweets is applied to label tweets corresponding to Ekman’s six basic emotions. Additionally, we conducted a series of experiments using various conventional machine learning models and deep learning, including transformer-based models, on our dataset to establish baseline results. The experimental results and an extensive ablation analysis on the dataset showed that BiLSTM with FastText and an attention mechanism outperforms other models in both classification tasks, achieving an F1-score of 70.92% for sentiment classification and 54.85% for emotion detection.</p>","PeriodicalId":56119,"journal":{"name":"Journal of Intelligent Information Systems","volume":"77 1","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2024-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Leveraging distant supervision and deep learning for twitter sentiment and emotion classification\",\"authors\":\"Muhamet Kastrati, Zenun Kastrati, Ali Shariq Imran, Marenglen Biba\",\"doi\":\"10.1007/s10844-024-00845-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Nowadays, various applications across industries, healthcare, and security have begun adopting automatic sentiment analysis and emotion detection in short texts, such as posts from social media. Twitter stands out as one of the most popular online social media platforms due to its easy, unique, and advanced accessibility using the API. On the other hand, supervised learning is the most widely used paradigm for tasks involving sentiment polarity and fine-grained emotion detection in short and informal texts, such as Twitter posts. However, supervised learning models are data-hungry and heavily reliant on abundant labeled data, which remains a challenge. This study aims to address this challenge by creating a large-scale real-world dataset of 17.5 million tweets. A distant supervision approach relying on emojis available in tweets is applied to label tweets corresponding to Ekman’s six basic emotions. Additionally, we conducted a series of experiments using various conventional machine learning models and deep learning, including transformer-based models, on our dataset to establish baseline results. The experimental results and an extensive ablation analysis on the dataset showed that BiLSTM with FastText and an attention mechanism outperforms other models in both classification tasks, achieving an F1-score of 70.92% for sentiment classification and 54.85% for emotion detection.</p>\",\"PeriodicalId\":56119,\"journal\":{\"name\":\"Journal of Intelligent Information Systems\",\"volume\":\"77 1\",\"pages\":\"\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2024-03-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Intelligent Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10844-024-00845-0\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Intelligent Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10844-024-00845-0","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
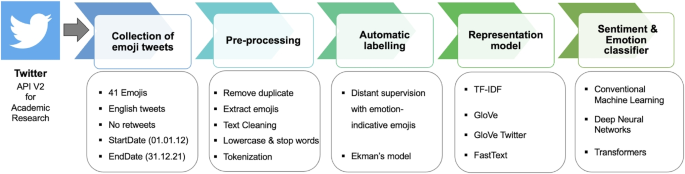
如今,各行各业、医疗保健和安全领域的各种应用都开始采用自动情感分析和情感检测短文,如社交媒体上的帖子。Twitter 是最受欢迎的在线社交媒体平台之一,因为它可以使用 API 进行简单、独特和先进的访问。另一方面,对于涉及情感极性和短篇非正式文本(如 Twitter 帖子)中细粒度情感检测的任务,监督学习是最广泛使用的范式。然而,监督学习模型对数据要求较高,严重依赖丰富的标记数据,这仍然是一个挑战。本研究旨在通过创建一个包含 1750 万条推文的大规模真实世界数据集来应对这一挑战。我们采用了一种远距离监督方法,依靠推文中的表情符号来标记与埃克曼的六种基本情绪相对应的推文。此外,我们还在数据集上使用各种传统机器学习模型和深度学习(包括基于变换器的模型)进行了一系列实验,以确定基线结果。实验结果和对数据集的广泛消融分析表明,带有 FastText 和注意力机制的 BiLSTM 在两项分类任务中都优于其他模型,情感分类的 F1 分数达到 70.92%,情感检测的 F1 分数达到 54.85%。
Leveraging distant supervision and deep learning for twitter sentiment and emotion classification
Nowadays, various applications across industries, healthcare, and security have begun adopting automatic sentiment analysis and emotion detection in short texts, such as posts from social media. Twitter stands out as one of the most popular online social media platforms due to its easy, unique, and advanced accessibility using the API. On the other hand, supervised learning is the most widely used paradigm for tasks involving sentiment polarity and fine-grained emotion detection in short and informal texts, such as Twitter posts. However, supervised learning models are data-hungry and heavily reliant on abundant labeled data, which remains a challenge. This study aims to address this challenge by creating a large-scale real-world dataset of 17.5 million tweets. A distant supervision approach relying on emojis available in tweets is applied to label tweets corresponding to Ekman’s six basic emotions. Additionally, we conducted a series of experiments using various conventional machine learning models and deep learning, including transformer-based models, on our dataset to establish baseline results. The experimental results and an extensive ablation analysis on the dataset showed that BiLSTM with FastText and an attention mechanism outperforms other models in both classification tasks, achieving an F1-score of 70.92% for sentiment classification and 54.85% for emotion detection.
期刊介绍:
The mission of the Journal of Intelligent Information Systems: Integrating Artifical Intelligence and Database Technologies is to foster and present research and development results focused on the integration of artificial intelligence and database technologies to create next generation information systems - Intelligent Information Systems.
These new information systems embody knowledge that allows them to exhibit intelligent behavior, cooperate with users and other systems in problem solving, discovery, access, retrieval and manipulation of a wide variety of multimedia data and knowledge, and reason under uncertainty. Increasingly, knowledge-directed inference processes are being used to:
discover knowledge from large data collections,
provide cooperative support to users in complex query formulation and refinement,
access, retrieve, store and manage large collections of multimedia data and knowledge,
integrate information from multiple heterogeneous data and knowledge sources, and
reason about information under uncertain conditions.
Multimedia and hypermedia information systems now operate on a global scale over the Internet, and new tools and techniques are needed to manage these dynamic and evolving information spaces.
The Journal of Intelligent Information Systems provides a forum wherein academics, researchers and practitioners may publish high-quality, original and state-of-the-art papers describing theoretical aspects, systems architectures, analysis and design tools and techniques, and implementation experiences in intelligent information systems. The categories of papers published by JIIS include: research papers, invited papters, meetings, workshop and conference annoucements and reports, survey and tutorial articles, and book reviews. Short articles describing open problems or their solutions are also welcome.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


