Zhao Li , Lan Lan , Yujia Zhou , Ruoxing Li , Kenneth D. Chavin , Hua Xu , Liang Li , David J.H. Shih , W. Jim Zheng
{"title":"开发基于深度学习的策略,从电子健康记录中预测非酒精性脂肪肝患者罹患肝细胞癌的风险。","authors":"Zhao Li , Lan Lan , Yujia Zhou , Ruoxing Li , Kenneth D. Chavin , Hua Xu , Liang Li , David J.H. Shih , W. Jim Zheng","doi":"10.1016/j.jbi.2024.104626","DOIUrl":null,"url":null,"abstract":"<div><h3>Objective</h3><p>The accuracy of deep learning models for many disease prediction problems is affected by time-varying covariates, rare incidence, covariate imbalance and delayed diagnosis when using structured electronic health records data. The situation is further exasperated when predicting the risk of one disease on condition of another disease, such as the hepatocellular carcinoma risk among patients with nonalcoholic fatty liver disease due to slow, chronic progression, the scarce of data with both disease conditions and the sex bias of the diseases. The goal of this study is to investigate the extent to which the aforementioned issues influence deep learning performance, and then devised strategies to tackle these challenges. These strategies were applied to improve hepatocellular carcinoma risk prediction among patients with nonalcoholic fatty liver disease.</p></div><div><h3>Methods</h3><p>We evaluated two representative deep learning models in the task of predicting the occurrence of hepatocellular carcinoma in a cohort of patients with nonalcoholic fatty liver disease (n = 220,838) from a national EHR database. The disease prediction task was carefully formulated as a classification problem while taking censorship and the length of follow-up into consideration.</p></div><div><h3>Results</h3><p>We developed a novel backward masking scheme to deal with the issue of delayed diagnosis which is very common in EHR data analysis and evaluate how the length of longitudinal information after the index date affects disease prediction. We observed that modeling time-varying covariates improved the performance of the algorithms and transfer learning mitigated reduced performance caused by the lack of data. In addition, covariate imbalance, such as sex bias in data impaired performance. Deep learning models trained on one sex and evaluated in the other sex showed reduced performance, indicating the importance of assessing covariate imbalance while preparing data for model training.</p></div><div><h3>Conclusions</h3><p>The strategies developed in this work can significantly improve the performance of hepatocellular carcinoma risk prediction among patients with nonalcoholic fatty liver disease. Furthermore, our novel strategies can be generalized to apply to other disease risk predictions using structured electronic health records, especially for disease risks on condition of another disease.</p></div>","PeriodicalId":15263,"journal":{"name":"Journal of Biomedical Informatics","volume":null,"pages":null},"PeriodicalIF":4.0000,"publicationDate":"2024-03-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Developing deep learning-based strategies to predict the risk of hepatocellular carcinoma among patients with nonalcoholic fatty liver disease from electronic health records\",\"authors\":\"Zhao Li , Lan Lan , Yujia Zhou , Ruoxing Li , Kenneth D. Chavin , Hua Xu , Liang Li , David J.H. Shih , W. Jim Zheng\",\"doi\":\"10.1016/j.jbi.2024.104626\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><h3>Objective</h3><p>The accuracy of deep learning models for many disease prediction problems is affected by time-varying covariates, rare incidence, covariate imbalance and delayed diagnosis when using structured electronic health records data. The situation is further exasperated when predicting the risk of one disease on condition of another disease, such as the hepatocellular carcinoma risk among patients with nonalcoholic fatty liver disease due to slow, chronic progression, the scarce of data with both disease conditions and the sex bias of the diseases. The goal of this study is to investigate the extent to which the aforementioned issues influence deep learning performance, and then devised strategies to tackle these challenges. These strategies were applied to improve hepatocellular carcinoma risk prediction among patients with nonalcoholic fatty liver disease.</p></div><div><h3>Methods</h3><p>We evaluated two representative deep learning models in the task of predicting the occurrence of hepatocellular carcinoma in a cohort of patients with nonalcoholic fatty liver disease (n = 220,838) from a national EHR database. The disease prediction task was carefully formulated as a classification problem while taking censorship and the length of follow-up into consideration.</p></div><div><h3>Results</h3><p>We developed a novel backward masking scheme to deal with the issue of delayed diagnosis which is very common in EHR data analysis and evaluate how the length of longitudinal information after the index date affects disease prediction. We observed that modeling time-varying covariates improved the performance of the algorithms and transfer learning mitigated reduced performance caused by the lack of data. In addition, covariate imbalance, such as sex bias in data impaired performance. Deep learning models trained on one sex and evaluated in the other sex showed reduced performance, indicating the importance of assessing covariate imbalance while preparing data for model training.</p></div><div><h3>Conclusions</h3><p>The strategies developed in this work can significantly improve the performance of hepatocellular carcinoma risk prediction among patients with nonalcoholic fatty liver disease. Furthermore, our novel strategies can be generalized to apply to other disease risk predictions using structured electronic health records, especially for disease risks on condition of another disease.</p></div>\",\"PeriodicalId\":15263,\"journal\":{\"name\":\"Journal of Biomedical Informatics\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2024-03-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Informatics\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S1532046424000443\",\"RegionNum\":2,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Informatics","FirstCategoryId":"3","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S1532046424000443","RegionNum":2,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, INTERDISCIPLINARY APPLICATIONS","Score":null,"Total":0}
Developing deep learning-based strategies to predict the risk of hepatocellular carcinoma among patients with nonalcoholic fatty liver disease from electronic health records
Objective
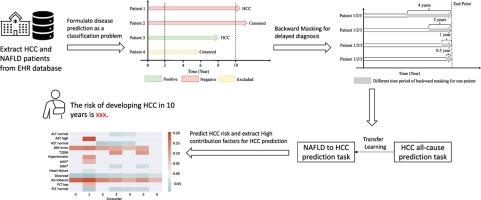
The accuracy of deep learning models for many disease prediction problems is affected by time-varying covariates, rare incidence, covariate imbalance and delayed diagnosis when using structured electronic health records data. The situation is further exasperated when predicting the risk of one disease on condition of another disease, such as the hepatocellular carcinoma risk among patients with nonalcoholic fatty liver disease due to slow, chronic progression, the scarce of data with both disease conditions and the sex bias of the diseases. The goal of this study is to investigate the extent to which the aforementioned issues influence deep learning performance, and then devised strategies to tackle these challenges. These strategies were applied to improve hepatocellular carcinoma risk prediction among patients with nonalcoholic fatty liver disease.
Methods
We evaluated two representative deep learning models in the task of predicting the occurrence of hepatocellular carcinoma in a cohort of patients with nonalcoholic fatty liver disease (n = 220,838) from a national EHR database. The disease prediction task was carefully formulated as a classification problem while taking censorship and the length of follow-up into consideration.
Results
We developed a novel backward masking scheme to deal with the issue of delayed diagnosis which is very common in EHR data analysis and evaluate how the length of longitudinal information after the index date affects disease prediction. We observed that modeling time-varying covariates improved the performance of the algorithms and transfer learning mitigated reduced performance caused by the lack of data. In addition, covariate imbalance, such as sex bias in data impaired performance. Deep learning models trained on one sex and evaluated in the other sex showed reduced performance, indicating the importance of assessing covariate imbalance while preparing data for model training.
Conclusions
The strategies developed in this work can significantly improve the performance of hepatocellular carcinoma risk prediction among patients with nonalcoholic fatty liver disease. Furthermore, our novel strategies can be generalized to apply to other disease risk predictions using structured electronic health records, especially for disease risks on condition of another disease.
期刊介绍:
The Journal of Biomedical Informatics reflects a commitment to high-quality original research papers, reviews, and commentaries in the area of biomedical informatics methodology. Although we publish articles motivated by applications in the biomedical sciences (for example, clinical medicine, health care, population health, and translational bioinformatics), the journal emphasizes reports of new methodologies and techniques that have general applicability and that form the basis for the evolving science of biomedical informatics. Articles on medical devices; evaluations of implemented systems (including clinical trials of information technologies); or papers that provide insight into a biological process, a specific disease, or treatment options would generally be more suitable for publication in other venues. Papers on applications of signal processing and image analysis are often more suitable for biomedical engineering journals or other informatics journals, although we do publish papers that emphasize the information management and knowledge representation/modeling issues that arise in the storage and use of biological signals and images. System descriptions are welcome if they illustrate and substantiate the underlying methodology that is the principal focus of the report and an effort is made to address the generalizability and/or range of application of that methodology. Note also that, given the international nature of JBI, papers that deal with specific languages other than English, or with country-specific health systems or approaches, are acceptable for JBI only if they offer generalizable lessons that are relevant to the broad JBI readership, regardless of their country, language, culture, or health system.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


