{"title":"通过薄弱监管及早发现新兴话题的假新闻","authors":"Serhat Hakki Akdag, Nihan Kesim Cicekli","doi":"10.1007/s10844-024-00852-1","DOIUrl":null,"url":null,"abstract":"<p>In this paper, we present a methodology for the early detection of fake news on emerging topics through the innovative application of weak supervision. Traditional techniques for fake news detection often rely on fact-checkers or supervised learning with labeled data, which is not readily available for emerging topics. To address this, we introduce the Weakly Supervised Text Classification framework (WeSTeC), an end-to-end solution designed to programmatically label large-scale text datasets within specific domains and train supervised text classifiers using the assigned labels. The proposed framework automatically generates labeling functions through multiple weak labeling strategies and eliminates underperforming ones. Labels assigned through the generated labeling functions are then used to fine-tune a pre-trained RoBERTa classifier for fake news detection. By using a weakly labeled dataset, which contains fake news related to the emerging topic, the trained fake news detection model becomes specialized for the topic under consideration. We explore both semi-supervision and domain adaptation setups, utilizing small amounts of labeled data and labeled data from other domains, respectively. The fake news classification model generated by the proposed framework excels when compared with all baselines in both setups. In addition, when compared to its fully supervised counterpart, our fake news detection model trained through weak labels achieves accuracy within 1%, emphasizing the robustness of the proposed framework’s weak labeling capabilities.</p>","PeriodicalId":56119,"journal":{"name":"Journal of Intelligent Information Systems","volume":"186 1","pages":""},"PeriodicalIF":3.4000,"publicationDate":"2024-03-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Early detection of fake news on emerging topics through weak supervision\",\"authors\":\"Serhat Hakki Akdag, Nihan Kesim Cicekli\",\"doi\":\"10.1007/s10844-024-00852-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>In this paper, we present a methodology for the early detection of fake news on emerging topics through the innovative application of weak supervision. Traditional techniques for fake news detection often rely on fact-checkers or supervised learning with labeled data, which is not readily available for emerging topics. To address this, we introduce the Weakly Supervised Text Classification framework (WeSTeC), an end-to-end solution designed to programmatically label large-scale text datasets within specific domains and train supervised text classifiers using the assigned labels. The proposed framework automatically generates labeling functions through multiple weak labeling strategies and eliminates underperforming ones. Labels assigned through the generated labeling functions are then used to fine-tune a pre-trained RoBERTa classifier for fake news detection. By using a weakly labeled dataset, which contains fake news related to the emerging topic, the trained fake news detection model becomes specialized for the topic under consideration. We explore both semi-supervision and domain adaptation setups, utilizing small amounts of labeled data and labeled data from other domains, respectively. The fake news classification model generated by the proposed framework excels when compared with all baselines in both setups. In addition, when compared to its fully supervised counterpart, our fake news detection model trained through weak labels achieves accuracy within 1%, emphasizing the robustness of the proposed framework’s weak labeling capabilities.</p>\",\"PeriodicalId\":56119,\"journal\":{\"name\":\"Journal of Intelligent Information Systems\",\"volume\":\"186 1\",\"pages\":\"\"},\"PeriodicalIF\":3.4000,\"publicationDate\":\"2024-03-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Intelligent Information Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10844-024-00852-1\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Intelligent Information Systems","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10844-024-00852-1","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
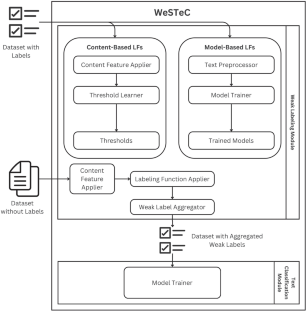
在本文中,我们提出了一种通过创新应用弱监督来早期检测新兴话题假新闻的方法。传统的假新闻检测技术通常依赖于事实核查人员或有标注数据的监督学习,而对于新兴话题来说,这些数据并不容易获得。为了解决这个问题,我们推出了弱监督文本分类框架(WeSTeC),这是一个端到端的解决方案,旨在以编程方式为特定领域内的大规模文本数据集贴标签,并使用分配的标签训练监督文本分类器。所提出的框架通过多种弱标签策略自动生成标签函数,并消除表现不佳的标签。然后,通过生成的标签函数分配的标签被用于微调预训练的 RoBERTa 分类器,以检测假新闻。通过使用弱标签数据集(其中包含与新兴话题相关的假新闻),经过训练的假新闻检测模型变得专门针对所考虑的话题。我们探索了半监督和领域适应设置,分别利用了少量标记数据和来自其他领域的标记数据。在这两种设置中,与所有基线相比,拟议框架生成的假新闻分类模型都非常出色。此外,与完全监督的假新闻检测模型相比,我们通过弱标签训练的假新闻检测模型的准确率在 1%以内,强调了所提出框架的弱标签功能的鲁棒性。
Early detection of fake news on emerging topics through weak supervision
In this paper, we present a methodology for the early detection of fake news on emerging topics through the innovative application of weak supervision. Traditional techniques for fake news detection often rely on fact-checkers or supervised learning with labeled data, which is not readily available for emerging topics. To address this, we introduce the Weakly Supervised Text Classification framework (WeSTeC), an end-to-end solution designed to programmatically label large-scale text datasets within specific domains and train supervised text classifiers using the assigned labels. The proposed framework automatically generates labeling functions through multiple weak labeling strategies and eliminates underperforming ones. Labels assigned through the generated labeling functions are then used to fine-tune a pre-trained RoBERTa classifier for fake news detection. By using a weakly labeled dataset, which contains fake news related to the emerging topic, the trained fake news detection model becomes specialized for the topic under consideration. We explore both semi-supervision and domain adaptation setups, utilizing small amounts of labeled data and labeled data from other domains, respectively. The fake news classification model generated by the proposed framework excels when compared with all baselines in both setups. In addition, when compared to its fully supervised counterpart, our fake news detection model trained through weak labels achieves accuracy within 1%, emphasizing the robustness of the proposed framework’s weak labeling capabilities.
期刊介绍:
The mission of the Journal of Intelligent Information Systems: Integrating Artifical Intelligence and Database Technologies is to foster and present research and development results focused on the integration of artificial intelligence and database technologies to create next generation information systems - Intelligent Information Systems.
These new information systems embody knowledge that allows them to exhibit intelligent behavior, cooperate with users and other systems in problem solving, discovery, access, retrieval and manipulation of a wide variety of multimedia data and knowledge, and reason under uncertainty. Increasingly, knowledge-directed inference processes are being used to:
discover knowledge from large data collections,
provide cooperative support to users in complex query formulation and refinement,
access, retrieve, store and manage large collections of multimedia data and knowledge,
integrate information from multiple heterogeneous data and knowledge sources, and
reason about information under uncertain conditions.
Multimedia and hypermedia information systems now operate on a global scale over the Internet, and new tools and techniques are needed to manage these dynamic and evolving information spaces.
The Journal of Intelligent Information Systems provides a forum wherein academics, researchers and practitioners may publish high-quality, original and state-of-the-art papers describing theoretical aspects, systems architectures, analysis and design tools and techniques, and implementation experiences in intelligent information systems. The categories of papers published by JIIS include: research papers, invited papters, meetings, workshop and conference annoucements and reports, survey and tutorial articles, and book reviews. Short articles describing open problems or their solutions are also welcome.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


