{"title":"ArQuAD:专家注释的阿拉伯语机器阅读理解数据集","authors":"Rasha Obeidat, Marwa Al-Harbi, Mahmoud Al-Ayyoub, Luay Alawneh","doi":"10.1007/s12559-024-10248-6","DOIUrl":null,"url":null,"abstract":"<p>Machine Reading Comprehension (MRC) is a task that enables machines to mirror key cognitive processes involving reading, comprehending a text passage, and answering questions about it. There has been significant progress in this task for English in recent years, where recent systems not only surpassed human-level performance but also demonstrated advancements in emulating complex human cognitive processes. However, the development of Arabic MRC has not kept pace due to language challenges and the lack of large-scale, high-quality datasets. Existing datasets are either small, low quality or released as a part of large multilingual corpora. We present the <b>Ar</b>abic <b>Qu</b>estion <b>A</b>nswering <b>D</b>ataset (<b>ArQuaD</b>), a large MRC dataset for the Arabic language. The dataset comprises 16,020 questions posed by language experts on passages extracted from Arabic Wikipedia articles, where the answer to each question is a text segment from the corresponding reading passage. Besides providing various dataset analyses, we fine-tuned several pre-trained language models to obtain benchmark results. Among the compared methods, AraBERTv0.2-large achieved the best performance with an exact match of 68.95% and an F1-score of 87.15%. However, the significantly higher performance observed in human evaluations (exact match of 86% and F1-score of 95.5%) suggests a significant margin of possible improvement in future research. We release the dataset publicly at https://github.com/RashaMObeidat/ArQuAD to encourage further development of language-aware MRC models for the Arabic language.</p>","PeriodicalId":51243,"journal":{"name":"Cognitive Computation","volume":"42 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2024-03-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"ArQuAD: An Expert-Annotated Arabic Machine Reading Comprehension Dataset\",\"authors\":\"Rasha Obeidat, Marwa Al-Harbi, Mahmoud Al-Ayyoub, Luay Alawneh\",\"doi\":\"10.1007/s12559-024-10248-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Machine Reading Comprehension (MRC) is a task that enables machines to mirror key cognitive processes involving reading, comprehending a text passage, and answering questions about it. There has been significant progress in this task for English in recent years, where recent systems not only surpassed human-level performance but also demonstrated advancements in emulating complex human cognitive processes. However, the development of Arabic MRC has not kept pace due to language challenges and the lack of large-scale, high-quality datasets. Existing datasets are either small, low quality or released as a part of large multilingual corpora. We present the <b>Ar</b>abic <b>Qu</b>estion <b>A</b>nswering <b>D</b>ataset (<b>ArQuaD</b>), a large MRC dataset for the Arabic language. The dataset comprises 16,020 questions posed by language experts on passages extracted from Arabic Wikipedia articles, where the answer to each question is a text segment from the corresponding reading passage. Besides providing various dataset analyses, we fine-tuned several pre-trained language models to obtain benchmark results. Among the compared methods, AraBERTv0.2-large achieved the best performance with an exact match of 68.95% and an F1-score of 87.15%. However, the significantly higher performance observed in human evaluations (exact match of 86% and F1-score of 95.5%) suggests a significant margin of possible improvement in future research. We release the dataset publicly at https://github.com/RashaMObeidat/ArQuAD to encourage further development of language-aware MRC models for the Arabic language.</p>\",\"PeriodicalId\":51243,\"journal\":{\"name\":\"Cognitive Computation\",\"volume\":\"42 1\",\"pages\":\"\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2024-03-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Cognitive Computation\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s12559-024-10248-6\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Cognitive Computation","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s12559-024-10248-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
ArQuAD: An Expert-Annotated Arabic Machine Reading Comprehension Dataset
Machine Reading Comprehension (MRC) is a task that enables machines to mirror key cognitive processes involving reading, comprehending a text passage, and answering questions about it. There has been significant progress in this task for English in recent years, where recent systems not only surpassed human-level performance but also demonstrated advancements in emulating complex human cognitive processes. However, the development of Arabic MRC has not kept pace due to language challenges and the lack of large-scale, high-quality datasets. Existing datasets are either small, low quality or released as a part of large multilingual corpora. We present the Arabic Question Answering Dataset (ArQuaD), a large MRC dataset for the Arabic language. The dataset comprises 16,020 questions posed by language experts on passages extracted from Arabic Wikipedia articles, where the answer to each question is a text segment from the corresponding reading passage. Besides providing various dataset analyses, we fine-tuned several pre-trained language models to obtain benchmark results. Among the compared methods, AraBERTv0.2-large achieved the best performance with an exact match of 68.95% and an F1-score of 87.15%. However, the significantly higher performance observed in human evaluations (exact match of 86% and F1-score of 95.5%) suggests a significant margin of possible improvement in future research. We release the dataset publicly at https://github.com/RashaMObeidat/ArQuAD to encourage further development of language-aware MRC models for the Arabic language.
期刊介绍:
Cognitive Computation is an international, peer-reviewed, interdisciplinary journal that publishes cutting-edge articles describing original basic and applied work involving biologically-inspired computational accounts of all aspects of natural and artificial cognitive systems. It provides a new platform for the dissemination of research, current practices and future trends in the emerging discipline of cognitive computation that bridges the gap between life sciences, social sciences, engineering, physical and mathematical sciences, and humanities.
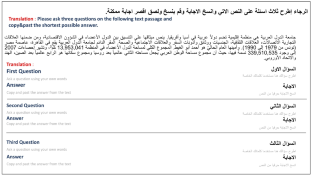

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


