Md. Alamin Talukder, Md. Manowarul Islam, Md Ashraf Uddin, Khondokar Fida Hasan, Selina Sharmin, Salem A. Alyami, Mohammad Ali Moni
{"title":"利用超采样、堆叠特征嵌入和特征提取,基于机器学习的大数据和不平衡数据网络入侵检测","authors":"Md. Alamin Talukder, Md. Manowarul Islam, Md Ashraf Uddin, Khondokar Fida Hasan, Selina Sharmin, Salem A. Alyami, Mohammad Ali Moni","doi":"10.1186/s40537-024-00886-w","DOIUrl":null,"url":null,"abstract":"<p>Cybersecurity has emerged as a critical global concern. Intrusion Detection Systems (IDS) play a critical role in protecting interconnected networks by detecting malicious actors and activities. Machine Learning (ML)-based behavior analysis within the IDS has considerable potential for detecting dynamic cyber threats, identifying abnormalities, and identifying malicious conduct within the network. However, as the number of data grows, dimension reduction becomes an increasingly difficult task when training ML models. Addressing this, our paper introduces a novel ML-based network intrusion detection model that uses Random Oversampling (RO) to address data imbalance and Stacking Feature Embedding based on clustering results, as well as Principal Component Analysis (PCA) for dimension reduction and is specifically designed for large and imbalanced datasets. This model’s performance is carefully evaluated using three cutting-edge benchmark datasets: UNSW-NB15, CIC-IDS-2017, and CIC-IDS-2018. On the UNSW-NB15 dataset, our trials show that the RF and ET models achieve accuracy rates of 99.59% and 99.95%, respectively. Furthermore, using the CIC-IDS2017 dataset, DT, RF, and ET models reach 99.99% accuracy, while DT and RF models obtain 99.94% accuracy on CIC-IDS2018. These performance results continuously outperform the state-of-art, indicating significant progress in the field of network intrusion detection. This achievement demonstrates the efficacy of the suggested methodology, which can be used practically to accurately monitor and identify network traffic intrusions, thereby blocking possible threats.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"32 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-02-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Machine learning-based network intrusion detection for big and imbalanced data using oversampling, stacking feature embedding and feature extraction\",\"authors\":\"Md. Alamin Talukder, Md. Manowarul Islam, Md Ashraf Uddin, Khondokar Fida Hasan, Selina Sharmin, Salem A. Alyami, Mohammad Ali Moni\",\"doi\":\"10.1186/s40537-024-00886-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Cybersecurity has emerged as a critical global concern. Intrusion Detection Systems (IDS) play a critical role in protecting interconnected networks by detecting malicious actors and activities. Machine Learning (ML)-based behavior analysis within the IDS has considerable potential for detecting dynamic cyber threats, identifying abnormalities, and identifying malicious conduct within the network. However, as the number of data grows, dimension reduction becomes an increasingly difficult task when training ML models. Addressing this, our paper introduces a novel ML-based network intrusion detection model that uses Random Oversampling (RO) to address data imbalance and Stacking Feature Embedding based on clustering results, as well as Principal Component Analysis (PCA) for dimension reduction and is specifically designed for large and imbalanced datasets. This model’s performance is carefully evaluated using three cutting-edge benchmark datasets: UNSW-NB15, CIC-IDS-2017, and CIC-IDS-2018. On the UNSW-NB15 dataset, our trials show that the RF and ET models achieve accuracy rates of 99.59% and 99.95%, respectively. Furthermore, using the CIC-IDS2017 dataset, DT, RF, and ET models reach 99.99% accuracy, while DT and RF models obtain 99.94% accuracy on CIC-IDS2018. These performance results continuously outperform the state-of-art, indicating significant progress in the field of network intrusion detection. This achievement demonstrates the efficacy of the suggested methodology, which can be used practically to accurately monitor and identify network traffic intrusions, thereby blocking possible threats.</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"32 1\",\"pages\":\"\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-02-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-024-00886-w\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00886-w","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
引用次数: 0
摘要
网络安全已成为全球关注的重要问题。入侵检测系统(IDS)通过检测恶意行为者和活动,在保护互连网络方面发挥着至关重要的作用。入侵检测系统中基于机器学习(ML)的行为分析在检测动态网络威胁、识别异常和识别网络中的恶意行为方面具有相当大的潜力。然而,随着数据数量的增加,在训练 ML 模型时,降维变得越来越困难。针对这一问题,我们的论文介绍了一种基于 ML 的新型网络入侵检测模型,该模型使用随机过采样(RO)来解决数据不平衡问题,并基于聚类结果和主成分分析(PCA)进行堆叠特征嵌入来降低维度,是专为大型和不平衡数据集而设计的。该模型的性能通过三个前沿基准数据集进行了仔细评估:UNSW-NB15、CIC-IDS-2017 和 CIC-IDS-2018。在 UNSW-NB15 数据集上,我们的试验表明 RF 和 ET 模型的准确率分别达到了 99.59% 和 99.95%。此外,在 CIC-IDS2017 数据集上,DT、RF 和 ET 模型的准确率达到 99.99%,而在 CIC-IDS2018 上,DT 和 RF 模型的准确率达到 99.94%。这些性能结果不断超越最新技术水平,表明在网络入侵检测领域取得了重大进展。这一成绩证明了所建议方法的有效性,可实际用于准确监控和识别网络流量入侵,从而阻止可能的威胁。
Machine learning-based network intrusion detection for big and imbalanced data using oversampling, stacking feature embedding and feature extraction
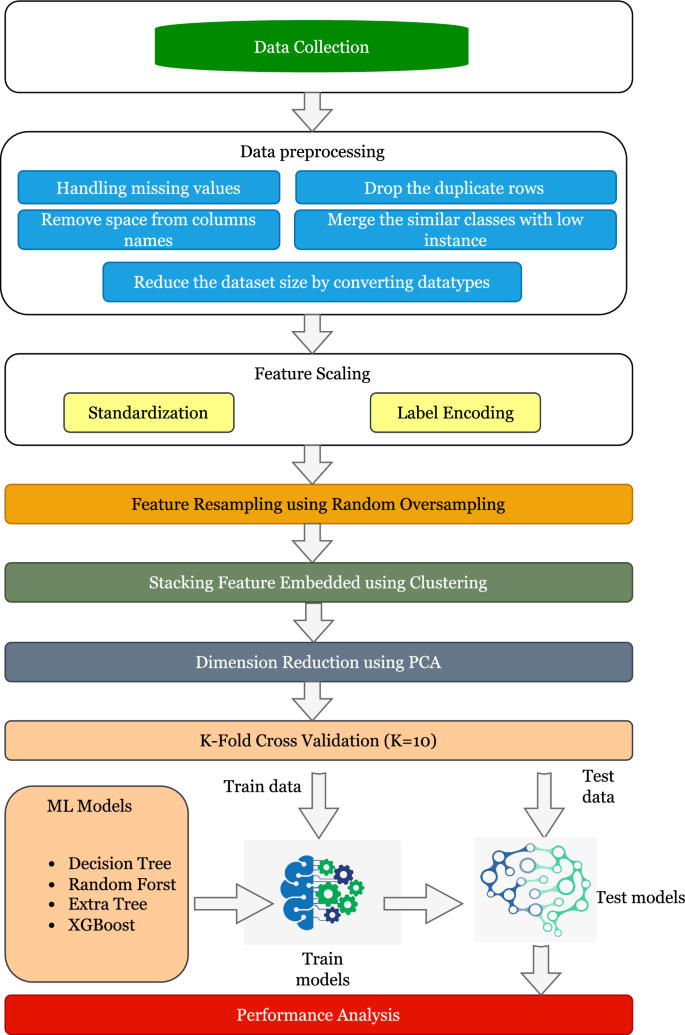
Cybersecurity has emerged as a critical global concern. Intrusion Detection Systems (IDS) play a critical role in protecting interconnected networks by detecting malicious actors and activities. Machine Learning (ML)-based behavior analysis within the IDS has considerable potential for detecting dynamic cyber threats, identifying abnormalities, and identifying malicious conduct within the network. However, as the number of data grows, dimension reduction becomes an increasingly difficult task when training ML models. Addressing this, our paper introduces a novel ML-based network intrusion detection model that uses Random Oversampling (RO) to address data imbalance and Stacking Feature Embedding based on clustering results, as well as Principal Component Analysis (PCA) for dimension reduction and is specifically designed for large and imbalanced datasets. This model’s performance is carefully evaluated using three cutting-edge benchmark datasets: UNSW-NB15, CIC-IDS-2017, and CIC-IDS-2018. On the UNSW-NB15 dataset, our trials show that the RF and ET models achieve accuracy rates of 99.59% and 99.95%, respectively. Furthermore, using the CIC-IDS2017 dataset, DT, RF, and ET models reach 99.99% accuracy, while DT and RF models obtain 99.94% accuracy on CIC-IDS2018. These performance results continuously outperform the state-of-art, indicating significant progress in the field of network intrusion detection. This achievement demonstrates the efficacy of the suggested methodology, which can be used practically to accurately monitor and identify network traffic intrusions, thereby blocking possible threats.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


