{"title":"基于机器学习的信用风险预测引擎系统,使用堆叠分类器和基于过滤器的特征选择方法","authors":"Ileberi Emmanuel, Yanxia Sun, Zenghui Wang","doi":"10.1186/s40537-024-00882-0","DOIUrl":null,"url":null,"abstract":"<p>Credit risk prediction is a crucial task for financial institutions. The technological advancements in machine learning, coupled with the availability of data and computing power, has given rise to more credit risk prediction models in financial institutions. In this paper, we propose a stacked classifier approach coupled with a filter-based feature selection (FS) technique to achieve efficient credit risk prediction using multiple datasets. The proposed stacked model includes the following base estimators: Random Forest (RF), Gradient Boosting (GB), and Extreme Gradient Boosting (XGB). Furthermore, the estimators in the Stacked architecture were linked sequentially to extract the best performance. The filter- based FS method that is used in this research is based on information gain (IG) theory. The proposed algorithm was evaluated using the accuracy, the F1-Score and the Area Under the Curve (AUC). Furthermore, the Stacked algorithm was compared to the following methods: Artificial Neural Network (ANN), Decision Tree (DT), and k-Nearest Neighbour (KNN). The experimental results show that stacked model obtained AUCs of 0.934, 0.944 and 0.870 on the Australian, German and Taiwan datasets, respectively. These results, in conjunction with the accuracy and F1-score metrics, demonstrated that the proposed stacked classifier outperforms the individual estimators and other existing methods.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"62 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-02-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A machine learning-based credit risk prediction engine system using a stacked classifier and a filter-based feature selection method\",\"authors\":\"Ileberi Emmanuel, Yanxia Sun, Zenghui Wang\",\"doi\":\"10.1186/s40537-024-00882-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Credit risk prediction is a crucial task for financial institutions. The technological advancements in machine learning, coupled with the availability of data and computing power, has given rise to more credit risk prediction models in financial institutions. In this paper, we propose a stacked classifier approach coupled with a filter-based feature selection (FS) technique to achieve efficient credit risk prediction using multiple datasets. The proposed stacked model includes the following base estimators: Random Forest (RF), Gradient Boosting (GB), and Extreme Gradient Boosting (XGB). Furthermore, the estimators in the Stacked architecture were linked sequentially to extract the best performance. The filter- based FS method that is used in this research is based on information gain (IG) theory. The proposed algorithm was evaluated using the accuracy, the F1-Score and the Area Under the Curve (AUC). Furthermore, the Stacked algorithm was compared to the following methods: Artificial Neural Network (ANN), Decision Tree (DT), and k-Nearest Neighbour (KNN). The experimental results show that stacked model obtained AUCs of 0.934, 0.944 and 0.870 on the Australian, German and Taiwan datasets, respectively. These results, in conjunction with the accuracy and F1-score metrics, demonstrated that the proposed stacked classifier outperforms the individual estimators and other existing methods.</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"62 1\",\"pages\":\"\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-02-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-024-00882-0\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-024-00882-0","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
A machine learning-based credit risk prediction engine system using a stacked classifier and a filter-based feature selection method
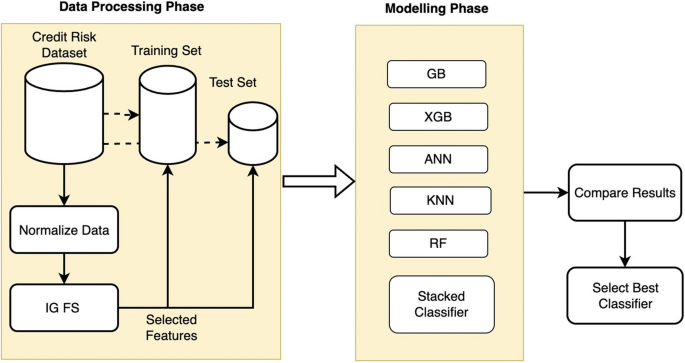
Credit risk prediction is a crucial task for financial institutions. The technological advancements in machine learning, coupled with the availability of data and computing power, has given rise to more credit risk prediction models in financial institutions. In this paper, we propose a stacked classifier approach coupled with a filter-based feature selection (FS) technique to achieve efficient credit risk prediction using multiple datasets. The proposed stacked model includes the following base estimators: Random Forest (RF), Gradient Boosting (GB), and Extreme Gradient Boosting (XGB). Furthermore, the estimators in the Stacked architecture were linked sequentially to extract the best performance. The filter- based FS method that is used in this research is based on information gain (IG) theory. The proposed algorithm was evaluated using the accuracy, the F1-Score and the Area Under the Curve (AUC). Furthermore, the Stacked algorithm was compared to the following methods: Artificial Neural Network (ANN), Decision Tree (DT), and k-Nearest Neighbour (KNN). The experimental results show that stacked model obtained AUCs of 0.934, 0.944 and 0.870 on the Australian, German and Taiwan datasets, respectively. These results, in conjunction with the accuracy and F1-score metrics, demonstrated that the proposed stacked classifier outperforms the individual estimators and other existing methods.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


