{"title":"利用自适应余量和能量驱动细化技术解决动作分割中的动作混淆问题","authors":"Zhichao Ma, Kan Li","doi":"10.1007/s00138-023-01505-z","DOIUrl":null,"url":null,"abstract":"<p>Video action segmentation is a crucial task in evaluating the ability to understand human activities. Previous works on this task mainly focus on capturing complex temporal structures and fail to consider the feature ambiguity among similar actions and the biased training sets, thus they are easy to confuse some actions. In this paper, we propose a novel action segmentation framework, called DeConfuNet, to solve the above issue. First, we design a discriminative enhancement module (DEM) trained by an adaptive margin-guided discriminative feature learning which adjusts the margin adaptively to increase the feature distinguishability among similar actions, and whose multi-stage reasoning and adaptive feature fusion structures provide structural advantages for distinguishing similar actions. Second, we propose an equalizing influence module (EIM) that can overcome the impact of biased training sets by balancing the influence of training samples under a coefficient-adaptive loss function. Third, an energy and context-driven refinement module (ECRM) further alleviates the impact of the unbalanced influence of training samples by fusing and refining the inference of DEM and EIM, which utilizes the phased prediction including context and energy clues to assimilate untrustworthy segments, alleviating over-segmentation hugely. Extensive experiments show the effectiveness of each proposed technique, they verify that the DEM and EIM are complementary in reasoning and cooperate to overcome the confusion issue, and our approach achieves significant improvement and state-of-the-art performance of accuracy, edit score, and F1 score on the challenging 50Salads, GTEA, and Breakfast benchmarks.</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"1 1","pages":""},"PeriodicalIF":2.3000,"publicationDate":"2024-01-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Tackling confusion among actions for action segmentation with adaptive margin and energy-driven refinement\",\"authors\":\"Zhichao Ma, Kan Li\",\"doi\":\"10.1007/s00138-023-01505-z\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Video action segmentation is a crucial task in evaluating the ability to understand human activities. Previous works on this task mainly focus on capturing complex temporal structures and fail to consider the feature ambiguity among similar actions and the biased training sets, thus they are easy to confuse some actions. In this paper, we propose a novel action segmentation framework, called DeConfuNet, to solve the above issue. First, we design a discriminative enhancement module (DEM) trained by an adaptive margin-guided discriminative feature learning which adjusts the margin adaptively to increase the feature distinguishability among similar actions, and whose multi-stage reasoning and adaptive feature fusion structures provide structural advantages for distinguishing similar actions. Second, we propose an equalizing influence module (EIM) that can overcome the impact of biased training sets by balancing the influence of training samples under a coefficient-adaptive loss function. Third, an energy and context-driven refinement module (ECRM) further alleviates the impact of the unbalanced influence of training samples by fusing and refining the inference of DEM and EIM, which utilizes the phased prediction including context and energy clues to assimilate untrustworthy segments, alleviating over-segmentation hugely. Extensive experiments show the effectiveness of each proposed technique, they verify that the DEM and EIM are complementary in reasoning and cooperate to overcome the confusion issue, and our approach achieves significant improvement and state-of-the-art performance of accuracy, edit score, and F1 score on the challenging 50Salads, GTEA, and Breakfast benchmarks.</p>\",\"PeriodicalId\":51116,\"journal\":{\"name\":\"Machine Vision and Applications\",\"volume\":\"1 1\",\"pages\":\"\"},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2024-01-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Machine Vision and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00138-023-01505-z\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-023-01505-z","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
引用次数: 0
摘要
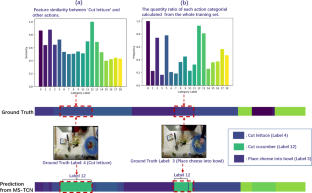
视频动作分割是评估理解人类活动能力的一项重要任务。以往关于这项任务的研究主要集中于捕捉复杂的时序结构,没有考虑相似动作之间的特征模糊性和训练集的偏差,因此容易混淆一些动作。本文提出了一种新颖的动作分割框架,称为 DeConfuNet,以解决上述问题。首先,我们设计了一个由自适应边际引导的判别特征学习训练的判别增强模块(DEM),该模块通过自适应调整边际来提高相似动作之间的特征可区分性,其多级推理和自适应特征融合结构为区分相似动作提供了结构优势。其次,我们提出了均衡影响模块(EIM),它可以在系数自适应损失函数下平衡训练样本的影响,从而克服偏差训练集的影响。第三,能量和上下文驱动的细化模块(ECRM)通过融合和细化 DEM 和 EIM 的推理,进一步减轻了训练样本不平衡影响的影响,该模块利用包括上下文和能量线索在内的分阶段预测来同化不可信的片段,从而减轻了过度分割的巨大影响。广泛的实验表明了所提出的每种技术的有效性,它们验证了 DEM 和 EIM 在推理中的互补性,并合作克服了混淆问题,而且我们的方法在具有挑战性的 50Salads、GTEA 和 Breakfast 基准上实现了准确率、编辑分数和 F1 分数的显著提高和一流性能。
Tackling confusion among actions for action segmentation with adaptive margin and energy-driven refinement
Video action segmentation is a crucial task in evaluating the ability to understand human activities. Previous works on this task mainly focus on capturing complex temporal structures and fail to consider the feature ambiguity among similar actions and the biased training sets, thus they are easy to confuse some actions. In this paper, we propose a novel action segmentation framework, called DeConfuNet, to solve the above issue. First, we design a discriminative enhancement module (DEM) trained by an adaptive margin-guided discriminative feature learning which adjusts the margin adaptively to increase the feature distinguishability among similar actions, and whose multi-stage reasoning and adaptive feature fusion structures provide structural advantages for distinguishing similar actions. Second, we propose an equalizing influence module (EIM) that can overcome the impact of biased training sets by balancing the influence of training samples under a coefficient-adaptive loss function. Third, an energy and context-driven refinement module (ECRM) further alleviates the impact of the unbalanced influence of training samples by fusing and refining the inference of DEM and EIM, which utilizes the phased prediction including context and energy clues to assimilate untrustworthy segments, alleviating over-segmentation hugely. Extensive experiments show the effectiveness of each proposed technique, they verify that the DEM and EIM are complementary in reasoning and cooperate to overcome the confusion issue, and our approach achieves significant improvement and state-of-the-art performance of accuracy, edit score, and F1 score on the challenging 50Salads, GTEA, and Breakfast benchmarks.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


