Riccardo Cantini, Fabrizio Marozzo, Alessio Orsino, Domenico Talia, Paolo Trunfio, Rosa M. Badia, Jorge Ejarque, Fernando Vázquez-Novoa
{"title":"利用机器学习技术为高性能计算应用中的数据分区估算块大小","authors":"Riccardo Cantini, Fabrizio Marozzo, Alessio Orsino, Domenico Talia, Paolo Trunfio, Rosa M. Badia, Jorge Ejarque, Fernando Vázquez-Novoa","doi":"10.1186/s40537-023-00862-w","DOIUrl":null,"url":null,"abstract":"<p>The extensive use of HPC infrastructures and frameworks for running data-intensive applications has led to a growing interest in data partitioning techniques and strategies. In fact, application performance can be heavily affected by how data are partitioned, which in turn depends on the selected size for data blocks, i.e. the block size. Therefore, finding an effective partitioning, i.e. a suitable block size, is a key strategy to speed-up parallel data-intensive applications and increase scalability. This paper describes a methodology, namely BLEST-ML (BLock size ESTimation through Machine Learning), for block size estimation that relies on supervised machine learning techniques. The proposed methodology was evaluated by designing an implementation tailored to <i>dislib</i>, a distributed computing library highly focused on machine learning algorithms built on top of the PyCOMPSs framework. We assessed the effectiveness of the provided implementation through an extensive experimental evaluation considering different algorithms from dislib, datasets, and infrastructures, including the MareNostrum 4 supercomputer. The results we obtained show the ability of BLEST-ML to efficiently determine a suitable way to split a given dataset, thus providing a proof of its applicability to enable the efficient execution of data-parallel applications in high performance environments.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"12 1","pages":""},"PeriodicalIF":6.4000,"publicationDate":"2024-01-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Block size estimation for data partitioning in HPC applications using machine learning techniques\",\"authors\":\"Riccardo Cantini, Fabrizio Marozzo, Alessio Orsino, Domenico Talia, Paolo Trunfio, Rosa M. Badia, Jorge Ejarque, Fernando Vázquez-Novoa\",\"doi\":\"10.1186/s40537-023-00862-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>The extensive use of HPC infrastructures and frameworks for running data-intensive applications has led to a growing interest in data partitioning techniques and strategies. In fact, application performance can be heavily affected by how data are partitioned, which in turn depends on the selected size for data blocks, i.e. the block size. Therefore, finding an effective partitioning, i.e. a suitable block size, is a key strategy to speed-up parallel data-intensive applications and increase scalability. This paper describes a methodology, namely BLEST-ML (BLock size ESTimation through Machine Learning), for block size estimation that relies on supervised machine learning techniques. The proposed methodology was evaluated by designing an implementation tailored to <i>dislib</i>, a distributed computing library highly focused on machine learning algorithms built on top of the PyCOMPSs framework. We assessed the effectiveness of the provided implementation through an extensive experimental evaluation considering different algorithms from dislib, datasets, and infrastructures, including the MareNostrum 4 supercomputer. The results we obtained show the ability of BLEST-ML to efficiently determine a suitable way to split a given dataset, thus providing a proof of its applicability to enable the efficient execution of data-parallel applications in high performance environments.</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"12 1\",\"pages\":\"\"},\"PeriodicalIF\":6.4000,\"publicationDate\":\"2024-01-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-023-00862-w\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-023-00862-w","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Block size estimation for data partitioning in HPC applications using machine learning techniques
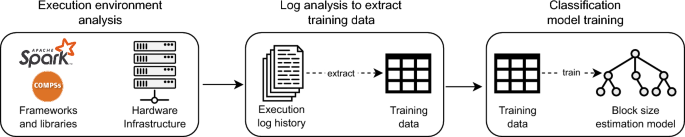
The extensive use of HPC infrastructures and frameworks for running data-intensive applications has led to a growing interest in data partitioning techniques and strategies. In fact, application performance can be heavily affected by how data are partitioned, which in turn depends on the selected size for data blocks, i.e. the block size. Therefore, finding an effective partitioning, i.e. a suitable block size, is a key strategy to speed-up parallel data-intensive applications and increase scalability. This paper describes a methodology, namely BLEST-ML (BLock size ESTimation through Machine Learning), for block size estimation that relies on supervised machine learning techniques. The proposed methodology was evaluated by designing an implementation tailored to dislib, a distributed computing library highly focused on machine learning algorithms built on top of the PyCOMPSs framework. We assessed the effectiveness of the provided implementation through an extensive experimental evaluation considering different algorithms from dislib, datasets, and infrastructures, including the MareNostrum 4 supercomputer. The results we obtained show the ability of BLEST-ML to efficiently determine a suitable way to split a given dataset, thus providing a proof of its applicability to enable the efficient execution of data-parallel applications in high performance environments.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


