Tommaso Dolci, Lorenzo Amata, Carlo Manco, Fabio Azzalini, Marco Gribaudo, Letizia Tanca
{"title":"医疗数据湖基础设施基准测试工具","authors":"Tommaso Dolci, Lorenzo Amata, Carlo Manco, Fabio Azzalini, Marco Gribaudo, Letizia Tanca","doi":"10.1007/s10796-023-10468-5","DOIUrl":null,"url":null,"abstract":"<p>Vast amounts of medical data are generated every day, and constitute a crucial asset to improve therapy outcomes, medical treatments and healthcare costs. Data lakes are a valuable solution for the management and analysis of such a variety and abundance of data, yet to date there is no data lake architecture specifically designed for the healthcare domain. Moreover, benchmarking the underlying infrastructure of data lakes is fundamental for optimizing resource allocation and performance, increasing the potential of this kind of data platforms. This work describes a data lake architecture to ingest, store, process, and analyze heterogeneous medical data. Also, we present a benchmark for infrastructures supporting healthcare data lakes, focusing on a variety of analysis tasks, from relational analysis to machine learning. The benchmark is tested on a virtualized implementation of our data lake architecture, and on two external cloud-based infrastructures. Our results highlight distinctions between infrastructures and tasks of different nature, according to the machine learning techniques, data sizes and formats involved.</p>","PeriodicalId":13610,"journal":{"name":"Information Systems Frontiers","volume":"8 1","pages":""},"PeriodicalIF":6.9000,"publicationDate":"2024-01-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Tools for Healthcare Data Lake Infrastructure Benchmarking\",\"authors\":\"Tommaso Dolci, Lorenzo Amata, Carlo Manco, Fabio Azzalini, Marco Gribaudo, Letizia Tanca\",\"doi\":\"10.1007/s10796-023-10468-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Vast amounts of medical data are generated every day, and constitute a crucial asset to improve therapy outcomes, medical treatments and healthcare costs. Data lakes are a valuable solution for the management and analysis of such a variety and abundance of data, yet to date there is no data lake architecture specifically designed for the healthcare domain. Moreover, benchmarking the underlying infrastructure of data lakes is fundamental for optimizing resource allocation and performance, increasing the potential of this kind of data platforms. This work describes a data lake architecture to ingest, store, process, and analyze heterogeneous medical data. Also, we present a benchmark for infrastructures supporting healthcare data lakes, focusing on a variety of analysis tasks, from relational analysis to machine learning. The benchmark is tested on a virtualized implementation of our data lake architecture, and on two external cloud-based infrastructures. Our results highlight distinctions between infrastructures and tasks of different nature, according to the machine learning techniques, data sizes and formats involved.</p>\",\"PeriodicalId\":13610,\"journal\":{\"name\":\"Information Systems Frontiers\",\"volume\":\"8 1\",\"pages\":\"\"},\"PeriodicalIF\":6.9000,\"publicationDate\":\"2024-01-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Information Systems Frontiers\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s10796-023-10468-5\",\"RegionNum\":3,\"RegionCategory\":\"管理学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Information Systems Frontiers","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s10796-023-10468-5","RegionNum":3,"RegionCategory":"管理学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
Tools for Healthcare Data Lake Infrastructure Benchmarking
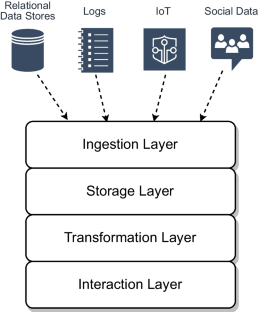
Vast amounts of medical data are generated every day, and constitute a crucial asset to improve therapy outcomes, medical treatments and healthcare costs. Data lakes are a valuable solution for the management and analysis of such a variety and abundance of data, yet to date there is no data lake architecture specifically designed for the healthcare domain. Moreover, benchmarking the underlying infrastructure of data lakes is fundamental for optimizing resource allocation and performance, increasing the potential of this kind of data platforms. This work describes a data lake architecture to ingest, store, process, and analyze heterogeneous medical data. Also, we present a benchmark for infrastructures supporting healthcare data lakes, focusing on a variety of analysis tasks, from relational analysis to machine learning. The benchmark is tested on a virtualized implementation of our data lake architecture, and on two external cloud-based infrastructures. Our results highlight distinctions between infrastructures and tasks of different nature, according to the machine learning techniques, data sizes and formats involved.
期刊介绍:
The interdisciplinary interfaces of Information Systems (IS) are fast emerging as defining areas of research and development in IS. These developments are largely due to the transformation of Information Technology (IT) towards networked worlds and its effects on global communications and economies. While these developments are shaping the way information is used in all forms of human enterprise, they are also setting the tone and pace of information systems of the future. The major advances in IT such as client/server systems, the Internet and the desktop/multimedia computing revolution, for example, have led to numerous important vistas of research and development with considerable practical impact and academic significance. While the industry seeks to develop high performance IS/IT solutions to a variety of contemporary information support needs, academia looks to extend the reach of IS technology into new application domains. Information Systems Frontiers (ISF) aims to provide a common forum of dissemination of frontline industrial developments of substantial academic value and pioneering academic research of significant practical impact.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


