{"title":"评估抑郁症的预后:比较人工智能模型、心理健康专业人员和普通大众的观点。","authors":"Zohar Elyoseph, Inbar Levkovich, Shiri Shinan-Altman","doi":"10.1136/fmch-2023-002583","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Artificial intelligence (AI) has rapidly permeated various sectors, including healthcare, highlighting its potential to facilitate mental health assessments. This study explores the underexplored domain of AI's role in evaluating prognosis and long-term outcomes in depressive disorders, offering insights into how AI large language models (LLMs) compare with human perspectives.</p><p><strong>Methods: </strong>Using case vignettes, we conducted a comparative analysis involving different LLMs (ChatGPT-3.5, ChatGPT-4, Claude and Bard), mental health professionals (general practitioners, psychiatrists, clinical psychologists and mental health nurses), and the general public that reported previously. We evaluate the LLMs ability to generate prognosis, anticipated outcomes with and without professional intervention, and envisioned long-term positive and negative consequences for individuals with depression.</p><p><strong>Results: </strong>In most of the examined cases, the four LLMs consistently identified depression as the primary diagnosis and recommended a combined treatment of psychotherapy and antidepressant medication. ChatGPT-3.5 exhibited a significantly pessimistic prognosis distinct from other LLMs, professionals and the public. ChatGPT-4, Claude and Bard aligned closely with mental health professionals and the general public perspectives, all of whom anticipated no improvement or worsening without professional help. Regarding long-term outcomes, ChatGPT 3.5, Claude and Bard consistently projected significantly fewer negative long-term consequences of treatment than ChatGPT-4.</p><p><strong>Conclusions: </strong>This study underscores the potential of AI to complement the expertise of mental health professionals and promote a collaborative paradigm in mental healthcare. The observation that three of the four LLMs closely mirrored the anticipations of mental health experts in scenarios involving treatment underscores the technology's prospective value in offering professional clinical forecasts. The pessimistic outlook presented by ChatGPT 3.5 is concerning, as it could potentially diminish patients' drive to initiate or continue depression therapy. In summary, although LLMs show potential in enhancing healthcare services, their utilisation requires thorough verification and a seamless integration with human judgement and skills.</p>","PeriodicalId":44590,"journal":{"name":"Family Medicine and Community Health","volume":"12 Suppl 1","pages":""},"PeriodicalIF":4.3000,"publicationDate":"2024-01-09","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10806564/pdf/","citationCount":"0","resultStr":"{\"title\":\"Assessing prognosis in depression: comparing perspectives of AI models, mental health professionals and the general public.\",\"authors\":\"Zohar Elyoseph, Inbar Levkovich, Shiri Shinan-Altman\",\"doi\":\"10.1136/fmch-2023-002583\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Artificial intelligence (AI) has rapidly permeated various sectors, including healthcare, highlighting its potential to facilitate mental health assessments. This study explores the underexplored domain of AI's role in evaluating prognosis and long-term outcomes in depressive disorders, offering insights into how AI large language models (LLMs) compare with human perspectives.</p><p><strong>Methods: </strong>Using case vignettes, we conducted a comparative analysis involving different LLMs (ChatGPT-3.5, ChatGPT-4, Claude and Bard), mental health professionals (general practitioners, psychiatrists, clinical psychologists and mental health nurses), and the general public that reported previously. We evaluate the LLMs ability to generate prognosis, anticipated outcomes with and without professional intervention, and envisioned long-term positive and negative consequences for individuals with depression.</p><p><strong>Results: </strong>In most of the examined cases, the four LLMs consistently identified depression as the primary diagnosis and recommended a combined treatment of psychotherapy and antidepressant medication. ChatGPT-3.5 exhibited a significantly pessimistic prognosis distinct from other LLMs, professionals and the public. ChatGPT-4, Claude and Bard aligned closely with mental health professionals and the general public perspectives, all of whom anticipated no improvement or worsening without professional help. Regarding long-term outcomes, ChatGPT 3.5, Claude and Bard consistently projected significantly fewer negative long-term consequences of treatment than ChatGPT-4.</p><p><strong>Conclusions: </strong>This study underscores the potential of AI to complement the expertise of mental health professionals and promote a collaborative paradigm in mental healthcare. The observation that three of the four LLMs closely mirrored the anticipations of mental health experts in scenarios involving treatment underscores the technology's prospective value in offering professional clinical forecasts. The pessimistic outlook presented by ChatGPT 3.5 is concerning, as it could potentially diminish patients' drive to initiate or continue depression therapy. In summary, although LLMs show potential in enhancing healthcare services, their utilisation requires thorough verification and a seamless integration with human judgement and skills.</p>\",\"PeriodicalId\":44590,\"journal\":{\"name\":\"Family Medicine and Community Health\",\"volume\":\"12 Suppl 1\",\"pages\":\"\"},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2024-01-09\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10806564/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Family Medicine and Community Health\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1136/fmch-2023-002583\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"PRIMARY HEALTH CARE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Family Medicine and Community Health","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1136/fmch-2023-002583","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"PRIMARY HEALTH CARE","Score":null,"Total":0}
Assessing prognosis in depression: comparing perspectives of AI models, mental health professionals and the general public.
Background: Artificial intelligence (AI) has rapidly permeated various sectors, including healthcare, highlighting its potential to facilitate mental health assessments. This study explores the underexplored domain of AI's role in evaluating prognosis and long-term outcomes in depressive disorders, offering insights into how AI large language models (LLMs) compare with human perspectives.
Methods: Using case vignettes, we conducted a comparative analysis involving different LLMs (ChatGPT-3.5, ChatGPT-4, Claude and Bard), mental health professionals (general practitioners, psychiatrists, clinical psychologists and mental health nurses), and the general public that reported previously. We evaluate the LLMs ability to generate prognosis, anticipated outcomes with and without professional intervention, and envisioned long-term positive and negative consequences for individuals with depression.
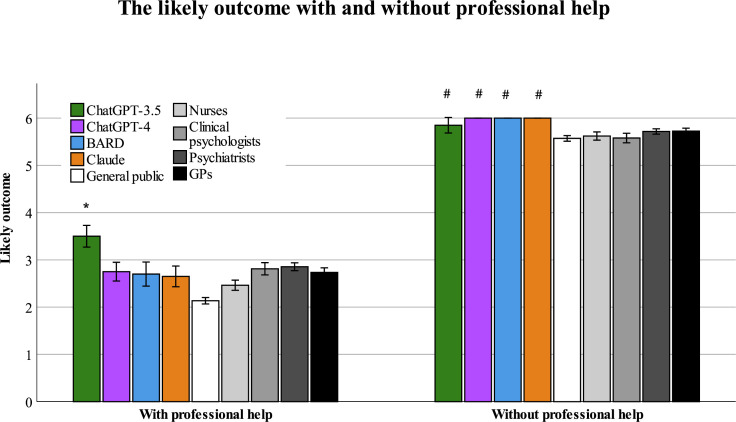
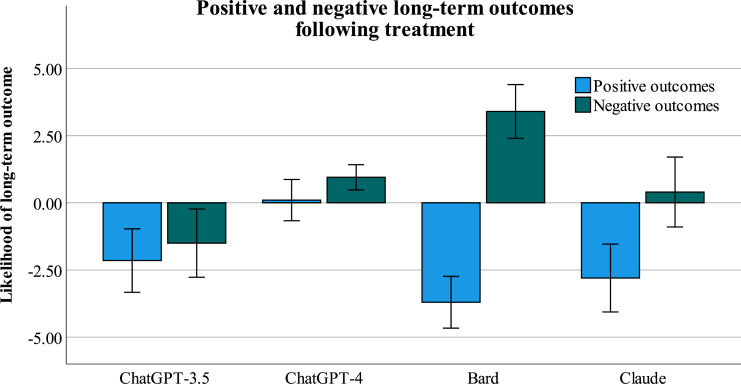
Results: In most of the examined cases, the four LLMs consistently identified depression as the primary diagnosis and recommended a combined treatment of psychotherapy and antidepressant medication. ChatGPT-3.5 exhibited a significantly pessimistic prognosis distinct from other LLMs, professionals and the public. ChatGPT-4, Claude and Bard aligned closely with mental health professionals and the general public perspectives, all of whom anticipated no improvement or worsening without professional help. Regarding long-term outcomes, ChatGPT 3.5, Claude and Bard consistently projected significantly fewer negative long-term consequences of treatment than ChatGPT-4.
Conclusions: This study underscores the potential of AI to complement the expertise of mental health professionals and promote a collaborative paradigm in mental healthcare. The observation that three of the four LLMs closely mirrored the anticipations of mental health experts in scenarios involving treatment underscores the technology's prospective value in offering professional clinical forecasts. The pessimistic outlook presented by ChatGPT 3.5 is concerning, as it could potentially diminish patients' drive to initiate or continue depression therapy. In summary, although LLMs show potential in enhancing healthcare services, their utilisation requires thorough verification and a seamless integration with human judgement and skills.
期刊介绍:
Family Medicine and Community Health (FMCH) is a peer-reviewed, open-access journal focusing on the topics of family medicine, general practice and community health. FMCH strives to be a leading international journal that promotes ‘Health Care for All’ through disseminating novel knowledge and best practices in primary care, family medicine, and community health. FMCH publishes original research, review, methodology, commentary, reflection, and case-study from the lens of population health. FMCH’s Asian Focus section features reports of family medicine development in the Asia-pacific region. FMCH aims to be an exemplary forum for the timely communication of medical knowledge and skills with the goal of promoting improved health care through the practice of family and community-based medicine globally. FMCH aims to serve a diverse audience including researchers, educators, policymakers and leaders of family medicine and community health. We also aim to provide content relevant for researchers working on population health, epidemiology, public policy, disease control and management, preventative medicine and disease burden. FMCH does not impose any article processing charges (APC) or submission charges.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


