Cynthia Yang, Egill A. Fridgeirsson, Jan A. Kors, Jenna M. Reps, Peter R. Rijnbeek
{"title":"随机过采样和随机欠采样对利用健康观察数据开发的预测模型性能的影响","authors":"Cynthia Yang, Egill A. Fridgeirsson, Jan A. Kors, Jenna M. Reps, Peter R. Rijnbeek","doi":"10.1186/s40537-023-00857-7","DOIUrl":null,"url":null,"abstract":"<h3 data-test=\"abstract-sub-heading\">Background</h3><p>There is currently no consensus on the impact of class imbalance methods on the performance of clinical prediction models. We aimed to empirically investigate the impact of random oversampling and random undersampling, two commonly used class imbalance methods, on the internal and external validation performance of prediction models developed using observational health data.</p><h3 data-test=\"abstract-sub-heading\">Methods</h3><p>We developed and externally validated prediction models for various outcomes of interest within a target population of people with pharmaceutically treated depression across four large observational health databases. We used three different classifiers (lasso logistic regression, random forest, XGBoost) and varied the target imbalance ratio. We evaluated the impact on model performance in terms of discrimination and calibration. Discrimination was assessed using the area under the receiver operating characteristic curve (AUROC) and calibration was assessed using calibration plots.</p><h3 data-test=\"abstract-sub-heading\">Results</h3><p>We developed and externally validated a total of 1,566 prediction models. On internal and external validation, random oversampling and random undersampling generally did not result in higher AUROCs. Moreover, we found overestimated risks, although this miscalibration could largely be corrected by recalibrating the models towards the imbalance ratios in the original dataset.</p><h3 data-test=\"abstract-sub-heading\">Conclusions</h3><p>Overall, we found that random oversampling or random undersampling generally does not improve the internal and external validation performance of prediction models developed in large observational health databases. Based on our findings, we do not recommend applying random oversampling or random undersampling when developing prediction models in large observational health databases.</p>","PeriodicalId":15158,"journal":{"name":"Journal of Big Data","volume":"27 1","pages":""},"PeriodicalIF":8.6000,"publicationDate":"2024-01-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Impact of random oversampling and random undersampling on the performance of prediction models developed using observational health data\",\"authors\":\"Cynthia Yang, Egill A. Fridgeirsson, Jan A. Kors, Jenna M. Reps, Peter R. Rijnbeek\",\"doi\":\"10.1186/s40537-023-00857-7\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<h3 data-test=\\\"abstract-sub-heading\\\">Background</h3><p>There is currently no consensus on the impact of class imbalance methods on the performance of clinical prediction models. We aimed to empirically investigate the impact of random oversampling and random undersampling, two commonly used class imbalance methods, on the internal and external validation performance of prediction models developed using observational health data.</p><h3 data-test=\\\"abstract-sub-heading\\\">Methods</h3><p>We developed and externally validated prediction models for various outcomes of interest within a target population of people with pharmaceutically treated depression across four large observational health databases. We used three different classifiers (lasso logistic regression, random forest, XGBoost) and varied the target imbalance ratio. We evaluated the impact on model performance in terms of discrimination and calibration. Discrimination was assessed using the area under the receiver operating characteristic curve (AUROC) and calibration was assessed using calibration plots.</p><h3 data-test=\\\"abstract-sub-heading\\\">Results</h3><p>We developed and externally validated a total of 1,566 prediction models. On internal and external validation, random oversampling and random undersampling generally did not result in higher AUROCs. Moreover, we found overestimated risks, although this miscalibration could largely be corrected by recalibrating the models towards the imbalance ratios in the original dataset.</p><h3 data-test=\\\"abstract-sub-heading\\\">Conclusions</h3><p>Overall, we found that random oversampling or random undersampling generally does not improve the internal and external validation performance of prediction models developed in large observational health databases. Based on our findings, we do not recommend applying random oversampling or random undersampling when developing prediction models in large observational health databases.</p>\",\"PeriodicalId\":15158,\"journal\":{\"name\":\"Journal of Big Data\",\"volume\":\"27 1\",\"pages\":\"\"},\"PeriodicalIF\":8.6000,\"publicationDate\":\"2024-01-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Big Data\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/s40537-023-00857-7\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, THEORY & METHODS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Big Data","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/s40537-023-00857-7","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, THEORY & METHODS","Score":null,"Total":0}
Impact of random oversampling and random undersampling on the performance of prediction models developed using observational health data
Background
There is currently no consensus on the impact of class imbalance methods on the performance of clinical prediction models. We aimed to empirically investigate the impact of random oversampling and random undersampling, two commonly used class imbalance methods, on the internal and external validation performance of prediction models developed using observational health data.
Methods
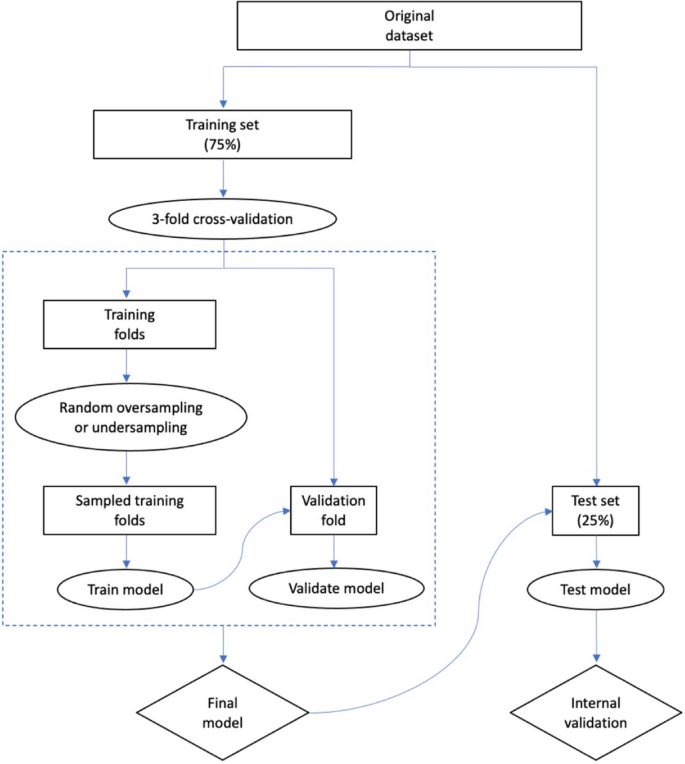
We developed and externally validated prediction models for various outcomes of interest within a target population of people with pharmaceutically treated depression across four large observational health databases. We used three different classifiers (lasso logistic regression, random forest, XGBoost) and varied the target imbalance ratio. We evaluated the impact on model performance in terms of discrimination and calibration. Discrimination was assessed using the area under the receiver operating characteristic curve (AUROC) and calibration was assessed using calibration plots.
Results
We developed and externally validated a total of 1,566 prediction models. On internal and external validation, random oversampling and random undersampling generally did not result in higher AUROCs. Moreover, we found overestimated risks, although this miscalibration could largely be corrected by recalibrating the models towards the imbalance ratios in the original dataset.
Conclusions
Overall, we found that random oversampling or random undersampling generally does not improve the internal and external validation performance of prediction models developed in large observational health databases. Based on our findings, we do not recommend applying random oversampling or random undersampling when developing prediction models in large observational health databases.
期刊介绍:
The Journal of Big Data publishes high-quality, scholarly research papers, methodologies, and case studies covering a broad spectrum of topics, from big data analytics to data-intensive computing and all applications of big data research. It addresses challenges facing big data today and in the future, including data capture and storage, search, sharing, analytics, technologies, visualization, architectures, data mining, machine learning, cloud computing, distributed systems, and scalable storage. The journal serves as a seminal source of innovative material for academic researchers and practitioners alike.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


