Bao Hoang, Yijiang Pang, Hiroko H Dodge, Jiayu Zhou
{"title":"数字生物标记物的主题协调:从语言标记改进对轻度认知障碍的检测。","authors":"Bao Hoang, Yijiang Pang, Hiroko H Dodge, Jiayu Zhou","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Mild cognitive impairment (MCI) represents the early stage of dementia including Alzheimer's disease (AD) and is a crucial stage for therapeutic interventions and treatment. Early detection of MCI offers opportunities for early intervention and significantly benefits cohort enrichment for clinical trials. Imaging and in vivo markers in plasma and cerebrospinal fluid biomarkers have high detection performance, yet their prohibitive costs and intrusiveness demand more affordable and accessible alternatives. The recent advances in digital biomarkers, especially language markers, have shown great potential, where variables informative to MCI are derived from linguistic and/or speech and later used for predictive modeling. A major challenge in modeling language markers comes from the variability of how each person speaks. As the cohort size for language studies is usually small due to extensive data collection efforts, the variability among persons makes language markers hard to generalize to unseen subjects. In this paper, we propose a novel subject harmonization tool to address the issue of distributional differences in language markers across subjects, thus enhancing the generalization performance of machine learning models. Our empirical results show that machine learning models built on our harmonized features have improved prediction performance on unseen data. The source code and experiment scripts are available at https://github.com/illidanlab/subject_harmonization.</p>","PeriodicalId":34954,"journal":{"name":"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing","volume":"29 ","pages":"187-200"},"PeriodicalIF":0.0000,"publicationDate":"2024-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11017207/pdf/","citationCount":"0","resultStr":"{\"title\":\"Subject Harmonization of Digital Biomarkers: Improved Detection of Mild Cognitive Impairment from Language Markers.\",\"authors\":\"Bao Hoang, Yijiang Pang, Hiroko H Dodge, Jiayu Zhou\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Mild cognitive impairment (MCI) represents the early stage of dementia including Alzheimer's disease (AD) and is a crucial stage for therapeutic interventions and treatment. Early detection of MCI offers opportunities for early intervention and significantly benefits cohort enrichment for clinical trials. Imaging and in vivo markers in plasma and cerebrospinal fluid biomarkers have high detection performance, yet their prohibitive costs and intrusiveness demand more affordable and accessible alternatives. The recent advances in digital biomarkers, especially language markers, have shown great potential, where variables informative to MCI are derived from linguistic and/or speech and later used for predictive modeling. A major challenge in modeling language markers comes from the variability of how each person speaks. As the cohort size for language studies is usually small due to extensive data collection efforts, the variability among persons makes language markers hard to generalize to unseen subjects. In this paper, we propose a novel subject harmonization tool to address the issue of distributional differences in language markers across subjects, thus enhancing the generalization performance of machine learning models. Our empirical results show that machine learning models built on our harmonized features have improved prediction performance on unseen data. The source code and experiment scripts are available at https://github.com/illidanlab/subject_harmonization.</p>\",\"PeriodicalId\":34954,\"journal\":{\"name\":\"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing\",\"volume\":\"29 \",\"pages\":\"187-200\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2024-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11017207/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Computer Science\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Pacific Symposium on Biocomputing. Pacific Symposium on Biocomputing","FirstCategoryId":"1085","ListUrlMain":"","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Computer Science","Score":null,"Total":0}
Subject Harmonization of Digital Biomarkers: Improved Detection of Mild Cognitive Impairment from Language Markers.
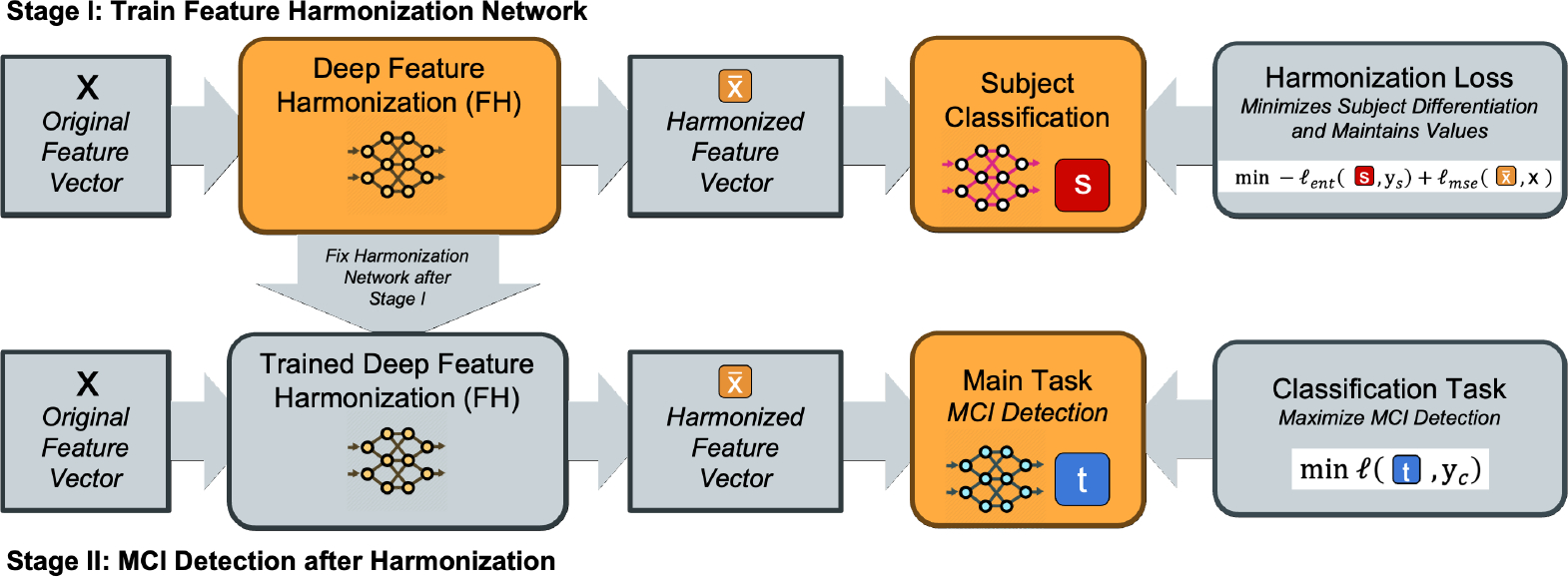
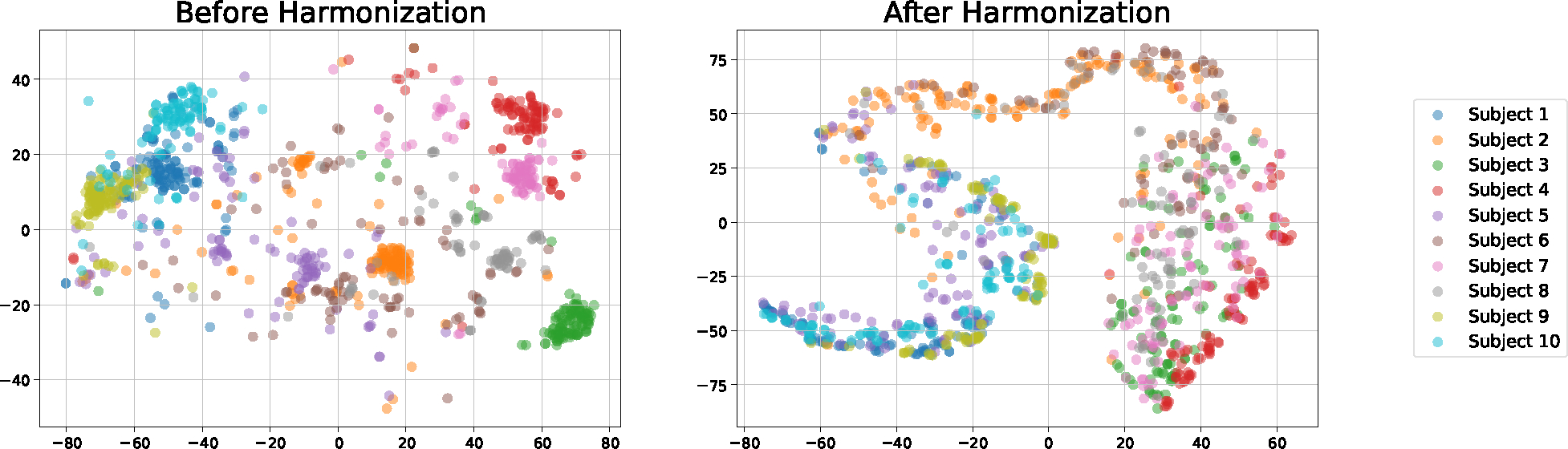
Mild cognitive impairment (MCI) represents the early stage of dementia including Alzheimer's disease (AD) and is a crucial stage for therapeutic interventions and treatment. Early detection of MCI offers opportunities for early intervention and significantly benefits cohort enrichment for clinical trials. Imaging and in vivo markers in plasma and cerebrospinal fluid biomarkers have high detection performance, yet their prohibitive costs and intrusiveness demand more affordable and accessible alternatives. The recent advances in digital biomarkers, especially language markers, have shown great potential, where variables informative to MCI are derived from linguistic and/or speech and later used for predictive modeling. A major challenge in modeling language markers comes from the variability of how each person speaks. As the cohort size for language studies is usually small due to extensive data collection efforts, the variability among persons makes language markers hard to generalize to unseen subjects. In this paper, we propose a novel subject harmonization tool to address the issue of distributional differences in language markers across subjects, thus enhancing the generalization performance of machine learning models. Our empirical results show that machine learning models built on our harmonized features have improved prediction performance on unseen data. The source code and experiment scripts are available at https://github.com/illidanlab/subject_harmonization.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


