{"title":"通过非线性特征对齐加强知识提炼","authors":"Jiangxiao Zhang, Feng Gao, Lina Huo, Hongliang Wang, Ying Dang","doi":"10.3103/S1060992X23040136","DOIUrl":null,"url":null,"abstract":"<p>Deploying AI models on resource-constrained devices is indeed a challenging task. It requires models to have a small parameter while maintaining high performance. Achieving a balance between model size and performance is essential to ensuring the efficient and effective deployment of AI models in such environments. Knowledge distillation (KD) is an important model compression technique that aims to have a small model learn from a larger model by leveraging the high-performance features of the larger model to enhance the performance of the smaller model, ultimately achieving or surpassing the performance of the larger models. This paper presents a pipeline-based knowledge distillation method that improves model performance through non-linear feature alignment (FA) after the feature extraction stage. We conducted experiments on both single-teacher distillation and multi-teacher distillation and through extensive experimentation, we demonstrated that our method can improve the accuracy of knowledge distillation on the existing KD loss function and further improve the performance of small models.</p>","PeriodicalId":721,"journal":{"name":"Optical Memory and Neural Networks","volume":"32 4","pages":"310 - 317"},"PeriodicalIF":1.0000,"publicationDate":"2023-12-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Enhancement of Knowledge Distillation via Non-Linear Feature Alignment\",\"authors\":\"Jiangxiao Zhang, Feng Gao, Lina Huo, Hongliang Wang, Ying Dang\",\"doi\":\"10.3103/S1060992X23040136\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Deploying AI models on resource-constrained devices is indeed a challenging task. It requires models to have a small parameter while maintaining high performance. Achieving a balance between model size and performance is essential to ensuring the efficient and effective deployment of AI models in such environments. Knowledge distillation (KD) is an important model compression technique that aims to have a small model learn from a larger model by leveraging the high-performance features of the larger model to enhance the performance of the smaller model, ultimately achieving or surpassing the performance of the larger models. This paper presents a pipeline-based knowledge distillation method that improves model performance through non-linear feature alignment (FA) after the feature extraction stage. We conducted experiments on both single-teacher distillation and multi-teacher distillation and through extensive experimentation, we demonstrated that our method can improve the accuracy of knowledge distillation on the existing KD loss function and further improve the performance of small models.</p>\",\"PeriodicalId\":721,\"journal\":{\"name\":\"Optical Memory and Neural Networks\",\"volume\":\"32 4\",\"pages\":\"310 - 317\"},\"PeriodicalIF\":1.0000,\"publicationDate\":\"2023-12-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Optical Memory and Neural Networks\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.3103/S1060992X23040136\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"OPTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Optical Memory and Neural Networks","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.3103/S1060992X23040136","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"OPTICS","Score":null,"Total":0}
Enhancement of Knowledge Distillation via Non-Linear Feature Alignment
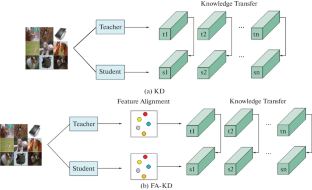
Deploying AI models on resource-constrained devices is indeed a challenging task. It requires models to have a small parameter while maintaining high performance. Achieving a balance between model size and performance is essential to ensuring the efficient and effective deployment of AI models in such environments. Knowledge distillation (KD) is an important model compression technique that aims to have a small model learn from a larger model by leveraging the high-performance features of the larger model to enhance the performance of the smaller model, ultimately achieving or surpassing the performance of the larger models. This paper presents a pipeline-based knowledge distillation method that improves model performance through non-linear feature alignment (FA) after the feature extraction stage. We conducted experiments on both single-teacher distillation and multi-teacher distillation and through extensive experimentation, we demonstrated that our method can improve the accuracy of knowledge distillation on the existing KD loss function and further improve the performance of small models.
期刊介绍:
The journal covers a wide range of issues in information optics such as optical memory, mechanisms for optical data recording and processing, photosensitive materials, optical, optoelectronic and holographic nanostructures, and many other related topics. Papers on memory systems using holographic and biological structures and concepts of brain operation are also included. The journal pays particular attention to research in the field of neural net systems that may lead to a new generation of computional technologies by endowing them with intelligence.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


