{"title":"论一种新的帕累托-威布尔混合分布:其参数回归模型与保险应用","authors":"Deepesh Bhati, Buddepu Pavan, Girish Aradhye","doi":"10.1007/s40745-023-00502-3","DOIUrl":null,"url":null,"abstract":"<div><p>This article introduces a new probability distribution suitable for modeling heavy-tailed and right-skewed data sets. The proposed distribution is derived from the continuous mixture of the scale parameter of the Pareto family with the Weibull distribution. Analytical expressions for various distributional properties and actuarial risk measures of the proposed model are derived. The applicability of the proposed model is assessed using two real-world insurance data sets, and its performance is compared with the existing class of heavy-tailed models. The proposed model is assumed for the response variable in parametric regression modeling to account for the heterogeneity of individual policyholders. The Expectation-Maximization (EM) Algorithm is included to expedite the process of finding maximum likelihood (ML) estimates for the parameters of the proposed models. Real-world data application demonstrates that the proposed distribution performs well compared to its competitor models. The regression model utilizing the mixed Pareto–Weibull response distribution, characterized by regression structures for both the mean and dispersion parameters, demonstrates superior performance when compared to the Pareto–Weibull regression model, where the dispersion parameter depends on covariates.</p></div>","PeriodicalId":36280,"journal":{"name":"Annals of Data Science","volume":"11 6","pages":"2077 - 2107"},"PeriodicalIF":0.0000,"publicationDate":"2023-12-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"On a New Mixed Pareto–Weibull Distribution: Its Parametric Regression Model with an Insurance Applications\",\"authors\":\"Deepesh Bhati, Buddepu Pavan, Girish Aradhye\",\"doi\":\"10.1007/s40745-023-00502-3\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>This article introduces a new probability distribution suitable for modeling heavy-tailed and right-skewed data sets. The proposed distribution is derived from the continuous mixture of the scale parameter of the Pareto family with the Weibull distribution. Analytical expressions for various distributional properties and actuarial risk measures of the proposed model are derived. The applicability of the proposed model is assessed using two real-world insurance data sets, and its performance is compared with the existing class of heavy-tailed models. The proposed model is assumed for the response variable in parametric regression modeling to account for the heterogeneity of individual policyholders. The Expectation-Maximization (EM) Algorithm is included to expedite the process of finding maximum likelihood (ML) estimates for the parameters of the proposed models. Real-world data application demonstrates that the proposed distribution performs well compared to its competitor models. The regression model utilizing the mixed Pareto–Weibull response distribution, characterized by regression structures for both the mean and dispersion parameters, demonstrates superior performance when compared to the Pareto–Weibull regression model, where the dispersion parameter depends on covariates.</p></div>\",\"PeriodicalId\":36280,\"journal\":{\"name\":\"Annals of Data Science\",\"volume\":\"11 6\",\"pages\":\"2077 - 2107\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-12-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Annals of Data Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s40745-023-00502-3\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Decision Sciences\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Annals of Data Science","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.1007/s40745-023-00502-3","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Decision Sciences","Score":null,"Total":0}
On a New Mixed Pareto–Weibull Distribution: Its Parametric Regression Model with an Insurance Applications
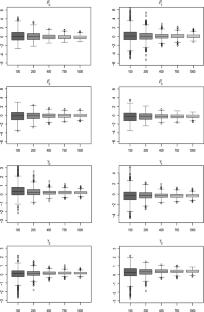
This article introduces a new probability distribution suitable for modeling heavy-tailed and right-skewed data sets. The proposed distribution is derived from the continuous mixture of the scale parameter of the Pareto family with the Weibull distribution. Analytical expressions for various distributional properties and actuarial risk measures of the proposed model are derived. The applicability of the proposed model is assessed using two real-world insurance data sets, and its performance is compared with the existing class of heavy-tailed models. The proposed model is assumed for the response variable in parametric regression modeling to account for the heterogeneity of individual policyholders. The Expectation-Maximization (EM) Algorithm is included to expedite the process of finding maximum likelihood (ML) estimates for the parameters of the proposed models. Real-world data application demonstrates that the proposed distribution performs well compared to its competitor models. The regression model utilizing the mixed Pareto–Weibull response distribution, characterized by regression structures for both the mean and dispersion parameters, demonstrates superior performance when compared to the Pareto–Weibull regression model, where the dispersion parameter depends on covariates.
期刊介绍:
Annals of Data Science (ADS) publishes cutting-edge research findings, experimental results and case studies of data science. Although Data Science is regarded as an interdisciplinary field of using mathematics, statistics, databases, data mining, high-performance computing, knowledge management and virtualization to discover knowledge from Big Data, it should have its own scientific contents, such as axioms, laws and rules, which are fundamentally important for experts in different fields to explore their own interests from Big Data. ADS encourages contributors to address such challenging problems at this exchange platform. At present, how to discover knowledge from heterogeneous data under Big Data environment needs to be addressed. ADS is a series of volumes edited by either the editorial office or guest editors. Guest editors will be responsible for call-for-papers and the review process for high-quality contributions in their volumes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


