基于图神经网络的语义模式对齐的主动学习
摘要
语义模式对齐的目的是基于语义表示来匹配跨一对模式的元素。它是数据集成的关键原语,有助于跨异构数据源创建公共数据结构。像图表示学习这样的深度学习方法已经显示出对语义丰富的模式(通常作为本体捕获)进行有效对齐的希望。这些方法中的大多数都是有监督的,并且需要大量标记的训练数据,这在成本和人工方面都是昂贵的。主动学习(AL)技术可以通过利用人在循环方法智能地选择要标记的数据来缓解这个问题,同时最小化所需的标记训练数据量。然而,现有的主动学习技术在利用来自底层模式的丰富语义信息方面受到限制。因此,它们不能驱动有效和高效的人类标签样本选择,这是扩展到更大数据集所必需的。在本文中,我们提出了一个主动学习框架Alfa来克服这些限制。Alfa利用模式元素属性以及模式元素(结构)之间的关系来驱动一种新的本体感知的样本选择和标签传播算法,用于训练高精度的对齐模型。我们提出语义块在不影响模型质量的情况下扩展到更大的数据集。我们在三个真实世界数据集上的实验结果表明:(1)阿尔法导致大量减少(27-82)%) in the cost of human labeling, (2) semantic blocking reduces label skew up to 40\(\times \) without adversely affecting model quality and scales AL to large datasets, and (3) sample selection achieves comparable schema matching quality (90% F1-score) to models trained on the entire set of available training data. We also show that Alfa outperforms the state-of-the-art ontology alignment system, BERTMap, in terms of (1) 10\(\times \) shorter time per AL iteration and (2) requiring half of the AL iterations to achieve the highest convergent F1-score.
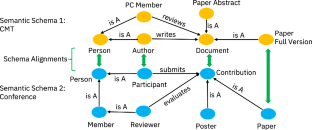
Semantic schema alignment aims to match elements across a pair of schemas based on their semantic representation. It is a key primitive for data integration that facilitates the creation of a common data fabric across heterogeneous data sources. Deep learning approaches such as graph representation learning have shown promise for effective alignment of semantically rich schemas, often captured as ontologies. Most of these approaches are supervised and require large amounts of labeled training data, which is expensive in terms of cost and manual labor. Active learning (AL) techniques can alleviate this issue by intelligently choosing the data to be labeled utilizing a human-in-the-loop approach, while minimizing the amount of labeled training data required. However, existing active learning techniques are limited in their ability to utilize the rich semantic information from underlying schemas. Therefore, they cannot drive effective and efficient sample selection for human labeling that is necessary to scale to larger datasets. In this paper, we propose Alfa, an active learning framework to overcome these limitations. Alfa exploits the schema element properties as well as the relationships between schema elements (structure) to drive a novel ontology-aware sample selection and label propagation algorithm for training highly accurate alignment models. We propose semantic blocking to scale to larger datasets without compromising model quality. Our experimental results across three real-world datasets show that (1) Alfa leads to a substantial reduction (27–82%) in the cost of human labeling, (2) semantic blocking reduces label skew up to 40\(\times \) without adversely affecting model quality and scales AL to large datasets, and (3) sample selection achieves comparable schema matching quality (90% F1-score) to models trained on the entire set of available training data. We also show that Alfa outperforms the state-of-the-art ontology alignment system, BERTMap, in terms of (1) 10\(\times \) shorter time per AL iteration and (2) requiring half of the AL iterations to achieve the highest convergent F1-score.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


