{"title":"基于视频的人物再识别的时空图引导全局注意力网络","authors":"Xiaobao Li, Wen Wang, Qingyong Li, Jiang Zhang","doi":"10.1007/s00138-023-01489-w","DOIUrl":null,"url":null,"abstract":"<p>Global attention learning has been extensively applied in video-based person re-identification due to its superiority in capturing contextual correlations. However, existing global attention learning methods usually adopt the conventional neural network to model non-Euclidean contextual correlations, resulting in a limited representation ability. Inspired by the graph-structure property of the contextual correlations, we propose a spatial-temporal graph-guided global attention network (STG<span>\\(^3\\)</span>A) for video-based person re-identification. STG<span>\\(^3\\)</span>A comprises two graph-guided attention modules to capture the spatial contexts within a frame and temporal contexts across all frames in a sequence for global attention learning. Furthermore, the graphs from both modules are encoded as graph representations, which combine with weighted representations to grasp the spatial-temporal contextual information adequately for video feature learning. To reduce the effect of noisy graph nodes and learn robust graph representations, a graph node attention is developed to trade-off the importance of each graph node, leading to noise-tolerant graph models. Finally, we design a graph-guided fusion scheme to integrate the representations output by these two attentive modules for a more compact video feature. Extensive experiments on MARS and DukeMTMCVideoReID datasets demonstrate the superior performance of the STG<span>\\(^3\\)</span>A.</p>","PeriodicalId":51116,"journal":{"name":"Machine Vision and Applications","volume":"55 1","pages":""},"PeriodicalIF":2.4000,"publicationDate":"2023-12-03","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"Spatial-temporal graph-guided global attention network for video-based person re-identification\",\"authors\":\"Xiaobao Li, Wen Wang, Qingyong Li, Jiang Zhang\",\"doi\":\"10.1007/s00138-023-01489-w\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Global attention learning has been extensively applied in video-based person re-identification due to its superiority in capturing contextual correlations. However, existing global attention learning methods usually adopt the conventional neural network to model non-Euclidean contextual correlations, resulting in a limited representation ability. Inspired by the graph-structure property of the contextual correlations, we propose a spatial-temporal graph-guided global attention network (STG<span>\\\\(^3\\\\)</span>A) for video-based person re-identification. STG<span>\\\\(^3\\\\)</span>A comprises two graph-guided attention modules to capture the spatial contexts within a frame and temporal contexts across all frames in a sequence for global attention learning. Furthermore, the graphs from both modules are encoded as graph representations, which combine with weighted representations to grasp the spatial-temporal contextual information adequately for video feature learning. To reduce the effect of noisy graph nodes and learn robust graph representations, a graph node attention is developed to trade-off the importance of each graph node, leading to noise-tolerant graph models. Finally, we design a graph-guided fusion scheme to integrate the representations output by these two attentive modules for a more compact video feature. Extensive experiments on MARS and DukeMTMCVideoReID datasets demonstrate the superior performance of the STG<span>\\\\(^3\\\\)</span>A.</p>\",\"PeriodicalId\":51116,\"journal\":{\"name\":\"Machine Vision and Applications\",\"volume\":\"55 1\",\"pages\":\"\"},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2023-12-03\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Machine Vision and Applications\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s00138-023-01489-w\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Machine Vision and Applications","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s00138-023-01489-w","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
Spatial-temporal graph-guided global attention network for video-based person re-identification
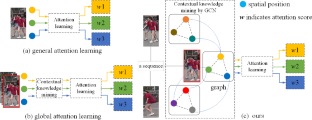
Global attention learning has been extensively applied in video-based person re-identification due to its superiority in capturing contextual correlations. However, existing global attention learning methods usually adopt the conventional neural network to model non-Euclidean contextual correlations, resulting in a limited representation ability. Inspired by the graph-structure property of the contextual correlations, we propose a spatial-temporal graph-guided global attention network (STG\(^3\)A) for video-based person re-identification. STG\(^3\)A comprises two graph-guided attention modules to capture the spatial contexts within a frame and temporal contexts across all frames in a sequence for global attention learning. Furthermore, the graphs from both modules are encoded as graph representations, which combine with weighted representations to grasp the spatial-temporal contextual information adequately for video feature learning. To reduce the effect of noisy graph nodes and learn robust graph representations, a graph node attention is developed to trade-off the importance of each graph node, leading to noise-tolerant graph models. Finally, we design a graph-guided fusion scheme to integrate the representations output by these two attentive modules for a more compact video feature. Extensive experiments on MARS and DukeMTMCVideoReID datasets demonstrate the superior performance of the STG\(^3\)A.
期刊介绍:
Machine Vision and Applications publishes high-quality technical contributions in machine vision research and development. Specifically, the editors encourage submittals in all applications and engineering aspects of image-related computing. In particular, original contributions dealing with scientific, commercial, industrial, military, and biomedical applications of machine vision, are all within the scope of the journal.
Particular emphasis is placed on engineering and technology aspects of image processing and computer vision.
The following aspects of machine vision applications are of interest: algorithms, architectures, VLSI implementations, AI techniques and expert systems for machine vision, front-end sensing, multidimensional and multisensor machine vision, real-time techniques, image databases, virtual reality and visualization. Papers must include a significant experimental validation component.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


