Dmitry Zankov, Timur Madzhidov, Alexandre Varnek, Pavel Polishchuk
{"title":"化学复杂性挑战:多实例机器学习是解决方案吗?","authors":"Dmitry Zankov, Timur Madzhidov, Alexandre Varnek, Pavel Polishchuk","doi":"10.1002/wcms.1698","DOIUrl":null,"url":null,"abstract":"<p>Molecules are complex dynamic objects that can exist in different molecular forms (conformations, tautomers, stereoisomers, protonation states, etc.) and often it is not known which molecular form is responsible for observed physicochemical and biological properties of a given molecule. This raises the problem of the selection of the correct molecular form for machine learning modeling of target properties. The same problem is common to biological molecules (RNA, DNA, proteins)—long sequences where only key segments, which often cannot be located precisely, are involved in biological functions. Multi-instance machine learning (MIL) is an efficient approach for solving problems where objects under study cannot be uniquely represented by a single instance, but rather by a set of multiple alternative instances. Multi-instance learning was formalized in 1997 and motivated by the problem of conformation selection in drug activity prediction tasks. Since then MIL has found a lot of applications in various domains, such as information retrieval, computer vision, signal processing, bankruptcy prediction, and so on. In the given review we describe the MIL framework and its applications to the tasks associated with ambiguity in the representation of small and biological molecules in chemoinformatics and bioinformatics. We have collected examples that demonstrate the advantages of MIL over the traditional single-instance learning (SIL) approach. Special attention was paid to the ability of MIL models to identify key instances responsible for a modeling property.</p><p>This article is categorized under:\n </p>","PeriodicalId":236,"journal":{"name":"Wiley Interdisciplinary Reviews: Computational Molecular Science","volume":"14 1","pages":""},"PeriodicalIF":27.0000,"publicationDate":"2023-11-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/wcms.1698","citationCount":"0","resultStr":"{\"title\":\"Chemical complexity challenge: Is multi-instance machine learning a solution?\",\"authors\":\"Dmitry Zankov, Timur Madzhidov, Alexandre Varnek, Pavel Polishchuk\",\"doi\":\"10.1002/wcms.1698\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>Molecules are complex dynamic objects that can exist in different molecular forms (conformations, tautomers, stereoisomers, protonation states, etc.) and often it is not known which molecular form is responsible for observed physicochemical and biological properties of a given molecule. This raises the problem of the selection of the correct molecular form for machine learning modeling of target properties. The same problem is common to biological molecules (RNA, DNA, proteins)—long sequences where only key segments, which often cannot be located precisely, are involved in biological functions. Multi-instance machine learning (MIL) is an efficient approach for solving problems where objects under study cannot be uniquely represented by a single instance, but rather by a set of multiple alternative instances. Multi-instance learning was formalized in 1997 and motivated by the problem of conformation selection in drug activity prediction tasks. Since then MIL has found a lot of applications in various domains, such as information retrieval, computer vision, signal processing, bankruptcy prediction, and so on. In the given review we describe the MIL framework and its applications to the tasks associated with ambiguity in the representation of small and biological molecules in chemoinformatics and bioinformatics. We have collected examples that demonstrate the advantages of MIL over the traditional single-instance learning (SIL) approach. Special attention was paid to the ability of MIL models to identify key instances responsible for a modeling property.</p><p>This article is categorized under:\\n </p>\",\"PeriodicalId\":236,\"journal\":{\"name\":\"Wiley Interdisciplinary Reviews: Computational Molecular Science\",\"volume\":\"14 1\",\"pages\":\"\"},\"PeriodicalIF\":27.0000,\"publicationDate\":\"2023-11-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/wcms.1698\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Wiley Interdisciplinary Reviews: Computational Molecular Science\",\"FirstCategoryId\":\"92\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/wcms.1698\",\"RegionNum\":2,\"RegionCategory\":\"化学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"CHEMISTRY, MULTIDISCIPLINARY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Wiley Interdisciplinary Reviews: Computational Molecular Science","FirstCategoryId":"92","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/wcms.1698","RegionNum":2,"RegionCategory":"化学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"CHEMISTRY, MULTIDISCIPLINARY","Score":null,"Total":0}
Chemical complexity challenge: Is multi-instance machine learning a solution?
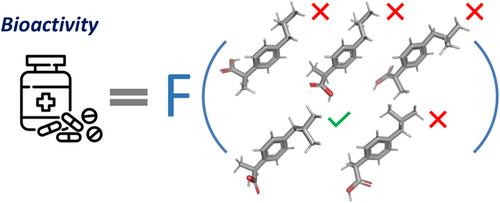
Molecules are complex dynamic objects that can exist in different molecular forms (conformations, tautomers, stereoisomers, protonation states, etc.) and often it is not known which molecular form is responsible for observed physicochemical and biological properties of a given molecule. This raises the problem of the selection of the correct molecular form for machine learning modeling of target properties. The same problem is common to biological molecules (RNA, DNA, proteins)—long sequences where only key segments, which often cannot be located precisely, are involved in biological functions. Multi-instance machine learning (MIL) is an efficient approach for solving problems where objects under study cannot be uniquely represented by a single instance, but rather by a set of multiple alternative instances. Multi-instance learning was formalized in 1997 and motivated by the problem of conformation selection in drug activity prediction tasks. Since then MIL has found a lot of applications in various domains, such as information retrieval, computer vision, signal processing, bankruptcy prediction, and so on. In the given review we describe the MIL framework and its applications to the tasks associated with ambiguity in the representation of small and biological molecules in chemoinformatics and bioinformatics. We have collected examples that demonstrate the advantages of MIL over the traditional single-instance learning (SIL) approach. Special attention was paid to the ability of MIL models to identify key instances responsible for a modeling property.
期刊介绍:
Computational molecular sciences harness the power of rigorous chemical and physical theories, employing computer-based modeling, specialized hardware, software development, algorithm design, and database management to explore and illuminate every facet of molecular sciences. These interdisciplinary approaches form a bridge between chemistry, biology, and materials sciences, establishing connections with adjacent application-driven fields in both chemistry and biology. WIREs Computational Molecular Science stands as a platform to comprehensively review and spotlight research from these dynamic and interconnected fields.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


